HW02-语音识别



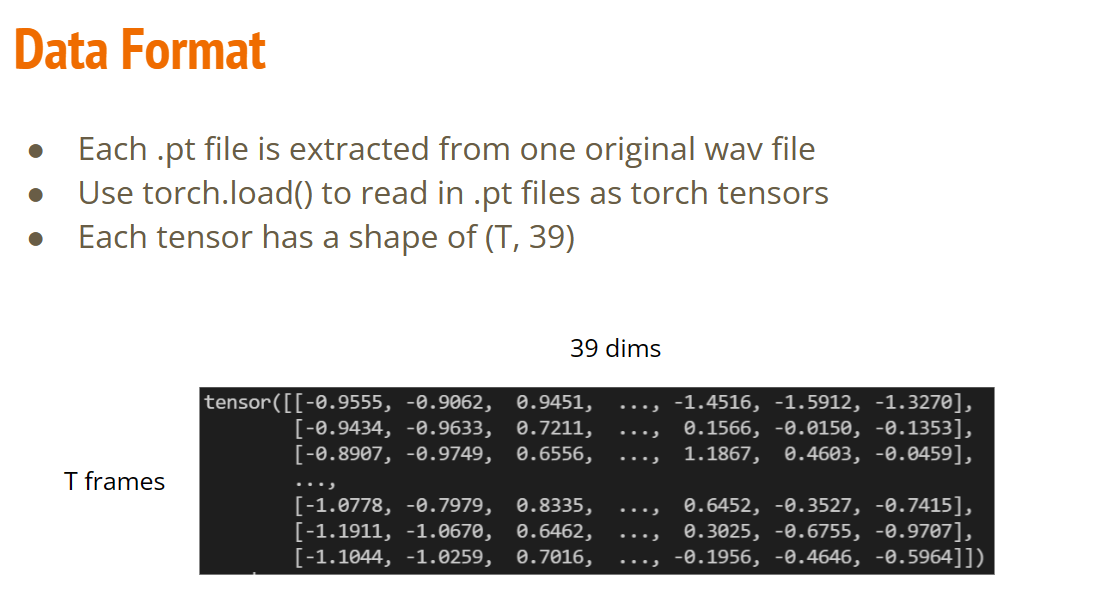

Homework 2 Phoneme Classification
Download Data
Download data from google drive, then unzip it.
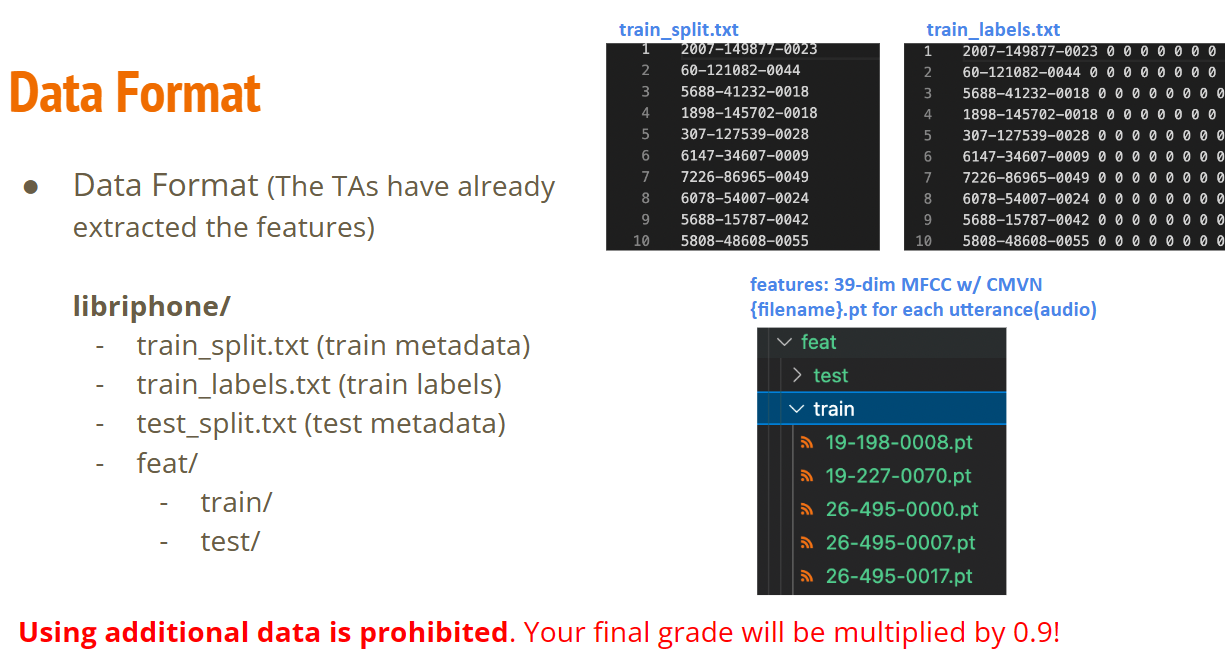
You should have
libriphone/train_split.txtlibriphone/train_labelslibriphone/test_split.txtlibriphone/feat/train/*.pt: training featurelibriphone/feat/test/*.pt: testing feature
after running the following block.
Notes: if the google drive link is dead, you can download the data directly from Kaggle and upload it to the workspace
Download train/test metadata
!pip install --upgrade gdown
Main link
!gdown --id ‘1o6Ag-G3qItSmYhTheX6DYiuyNzWyHyTc’ --output libriphone.zip
Backup link 1
!gdown --id ‘1R1uQYi4QpX0tBfUWt2mbZcncdBsJkxeW’ --output libriphone.zip
Bqckup link 2
!wget -O libriphone.zip “https://www.dropbox.com/s/wqww8c5dbrl2ka9/libriphone.zip?dl=1”
!unzip -q libriphone.zip
!ls libriphone
Preparing Data
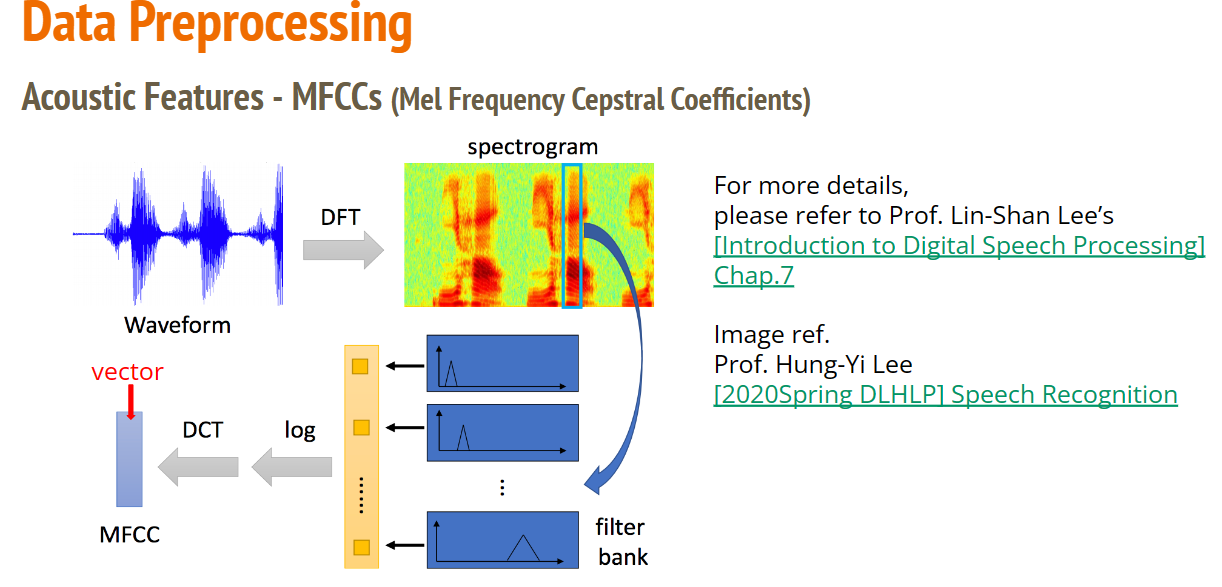
Helper functions to pre-process the training data from raw MFCC features of each utterance.
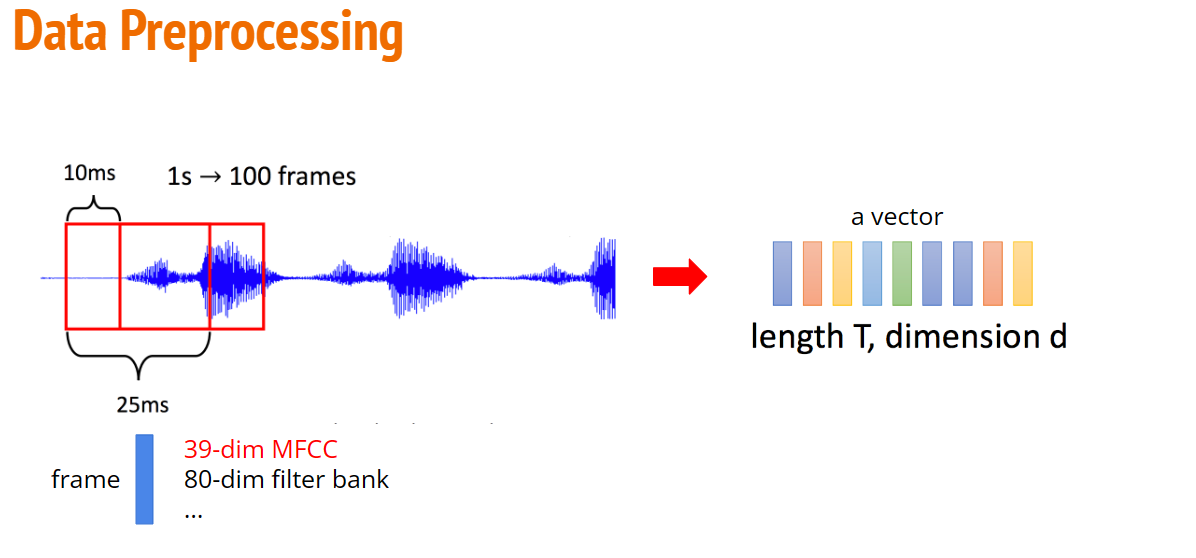
A phoneme may span several frames and is dependent to past and future frames.
Hence we concatenate neighboring phonemes for training to achieve higher accuracy. The concat_feat function concatenates past and future k frames (total 2k+1 = n frames), and we predict the center frame.
Feel free to modify the data preprocess functions, but do not drop any frame (if you modify the functions, remember to check that the number of frames are the same as mentioned in the slides)
import os
import random
import pandas as pd
import torch
from tqdm import tqdm
def load_feat(path):
feat = torch.load(path)
return feat
def shift(x, n):
if n < 0:
left = x[0].repeat(-n, 1)
right = x[:n]
elif n > 0:
right = x[-1].repeat(n, 1)
left = x[n:]
else:
return x
return torch.cat((left, right), dim=0)
def concat_feat(x, concat_n):
assert concat_n % 2 == 1 # n must be odd
if concat_n < 2:
return x
seq_len, feature_dim = x.size(0), x.size(1)
x = x.repeat(1, concat_n)
x = x.view(seq_len, concat_n, feature_dim).permute(1, 0, 2) # concat_n, seq_len, feature_dim
mid = (concat_n // 2)
for r_idx in range(1, mid+1):
x[mid + r_idx, :] = shift(x[mid + r_idx], r_idx)
x[mid - r_idx, :] = shift(x[mid - r_idx], -r_idx)
return x.permute(1, 0, 2).view(seq_len, concat_n * feature_dim)
def preprocess_data(split, feat_dir, phone_path, concat_nframes, train_ratio=0.8, train_val_seed=1337):
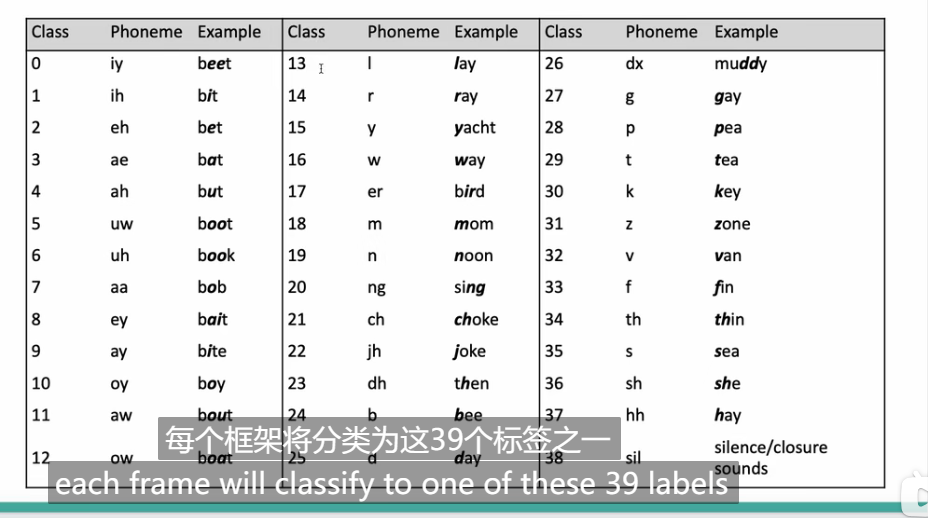
class_num = 41 # NOTE: pre-computed, should not need change
mode = 'train' if (split == 'train' or split == 'val') else 'test'
label_dict = {}
if mode != 'test':
phone_file = open(os.path.join(phone_path, f'{mode}_labels.txt')).readlines()
for line in phone_file:
line = line.strip('\n').split(' ')
label_dict[line[0]] = [int(p) for p in line[1:]]
if split == 'train' or split == 'val':
# split training and validation data
usage_list = open(os.path.join(phone_path, 'train_split.txt')).readlines()
random.seed(train_val_seed)
random.shuffle(usage_list)
percent = int(len(usage_list) * train_ratio)
usage_list = usage_list[:percent] if split == 'train' else usage_list[percent:]
elif split == 'test':
usage_list = open(os.path.join(phone_path, 'test_split.txt')).readlines()
else:
raise ValueError('Invalid \'split\' argument for dataset: PhoneDataset!')
usage_list = [line.strip('\n') for line in usage_list]
print('[Dataset] - # phone classes: ' + str(class_num) + ', number of utterances for ' + split + ': ' + str(len(usage_list)))
max_len = 3000000
X = torch.empty(max_len, 39 * concat_nframes)
if mode != 'test':
y = torch.empty(max_len, dtype=torch.long)
idx = 0
for i, fname in tqdm(enumerate(usage_list)):
feat = load_feat(os.path.join(feat_dir, mode, f'{fname}.pt'))
cur_len = len(feat)
feat = concat_feat(feat, concat_nframes)
if mode != 'test':
label = torch.LongTensor(label_dict[fname])
X[idx: idx + cur_len, :] = feat
if mode != 'test':
y[idx: idx + cur_len] = label
idx += cur_len
X = X[:idx, :]
if mode != 'test':
y = y[:idx]
print(f'[INFO] {split} set')
print(X.shape)
if mode != 'test':
print(y.shape)
return X, y
else:
return X
Define Dataset
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class LibriDataset(Dataset):
def __init__(self, X, y=None):
self.data = X
if y is not None:
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)
Define Model
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, input_dim, output_dim):
super(BasicBlock, self).__init__()
self.block = nn.Sequential(
nn.Linear(input_dim, output_dim),
nn.ReLU(),
nn.BatchNorm1d(output_dim),
nn.Dropout(0.35),
)
def forward(self, x):
x = self.block(x)
return x
class Classifier(nn.Module):
def __init__(self, input_dim, output_dim=41, hidden_layers=1, hidden_dim=256):
super(Classifier, self).__init__()
self.fc = nn.Sequential(
BasicBlock(input_dim, hidden_dim),
*[BasicBlock(hidden_dim, hidden_dim) for _ in range(hidden_layers)],
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
x = self.fc(x)
return x
Hyper-parameters
# data prarameters
concat_nframes = 19 # the number of frames to concat with, n must be odd (total 2k+1 = n frames)
train_ratio = 0.8 # the ratio of data used for training, the rest will be used for validation
# training parameters
seed = 0 # random seed
batch_size = 2048 # batch size
num_epoch = 50 # the number of training epoch
early_stopping = 8
learning_rate = 0.0001 #learning rate
model_path = './model.ckpt' # the path where the checkpoint will be saved
# model parameters
input_dim = 39 * concat_nframes # the input dim of the model, you should not change the value
hidden_layers = 3 # the number of hidden layers
hidden_dim = 1024 # the hidden dim
Prepare dataset and model
import gc
# preprocess data
train_X, train_y = preprocess_data(split='train', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
val_X, val_y = preprocess_data(split='val', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes, train_ratio=train_ratio)
# get dataset
train_set = LibriDataset(train_X, train_y)
val_set = LibriDataset(val_X, val_y)
# remove raw feature to save memory
del train_X, train_y, val_X, val_y
gc.collect()
# get dataloader
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False)
[Dataset] - # phone classes: 41, number of utterances for train: 3428
3428it [00:07, 464.93it/s]
[INFO] train set
torch.Size([2116368, 741])
torch.Size([2116368])
[Dataset] - # phone classes: 41, number of utterances for val: 858
858it [00:01, 485.84it/s]
[INFO] val set
torch.Size([527790, 741])
torch.Size([527790])
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
print(f'DEVICE: {device}')
DEVICE: cuda:0
import numpy as np
#fix seed
def same_seeds(seed):
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
# fix random seed
same_seeds(seed)
# create model, define a loss function, and optimizer
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate*5, weight_decay=0.01)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,
T_0=8, T_mult=2, eta_min=learning_rate/2)
import torchsummary
torchsummary.summary(model, input_size=(input_dim,))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Linear-1 [-1, 1024] 759,808
ReLU-2 [-1, 1024] 0
BatchNorm1d-3 [-1, 1024] 2,048
Dropout-4 [-1, 1024] 0
BasicBlock-5 [-1, 1024] 0
Linear-6 [-1, 1024] 1,049,600
ReLU-7 [-1, 1024] 0
BatchNorm1d-8 [-1, 1024] 2,048
Dropout-9 [-1, 1024] 0
BasicBlock-10 [-1, 1024] 0
Linear-11 [-1, 1024] 1,049,600
ReLU-12 [-1, 1024] 0
BatchNorm1d-13 [-1, 1024] 2,048
Dropout-14 [-1, 1024] 0
BasicBlock-15 [-1, 1024] 0
Linear-16 [-1, 1024] 1,049,600
ReLU-17 [-1, 1024] 0
BatchNorm1d-18 [-1, 1024] 2,048
Dropout-19 [-1, 1024] 0
BasicBlock-20 [-1, 1024] 0
Linear-21 [-1, 41] 42,025
================================================================
Total params: 3,958,825
Trainable params: 3,958,825
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.16
Params size (MB): 15.10
Estimated Total Size (MB): 15.26
----------------------------------------------------------------
Training
best_acc = 0.0
early_stop_count = 0
for epoch in range(num_epoch):
train_acc = 0.0
train_loss = 0.0
val_acc = 0.0
val_loss = 0.0
# training
model.train() # set the model to training mode
pbar = tqdm(train_loader, ncols=110)
pbar.set_description(f'T: {epoch+1}/{num_epoch}')
samples = 0
for i, batch in enumerate(pbar):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, train_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
correct = (train_pred.detach() == labels.detach()).sum().item()
train_acc += correct
samples += labels.size(0)
train_loss += loss.item()
lr = optimizer.param_groups[0]["lr"]
pbar.set_postfix({'lr':lr, 'batch acc':correct/labels.size(0),
'acc':train_acc/samples, 'loss':train_loss/(i+1)})
scheduler.step()
pbar.close()
# validation
if len(val_set) > 0:
model.eval() # set the model to evaluation mode
with torch.no_grad():
pbar = tqdm(val_loader, ncols=110)
pbar.set_description(f'V: {epoch+1}/{num_epoch}')
samples = 0
for i, batch in enumerate(pbar):
features, labels = batch
features = features.to(device)
labels = labels.to(device)
outputs = model(features)
loss = criterion(outputs, labels)
_, val_pred = torch.max(outputs, 1) #get the index of the class with the highest probability
val_acc += (val_pred.cpu() == labels.cpu()).sum().item()
samples += labels.size(0)
val_loss += loss.item()
pbar.set_postfix({'val acc':val_acc/samples ,'val loss':val_loss/(i+1)})
pbar.close()
# if the model improves, save a checkpoint at this epoch
if val_acc > best_acc:
best_acc = val_acc
torch.save(model.state_dict(), model_path)
print('saving model with acc {:.3f}'.format(best_acc/len(val_set)))
early_stop_count = 0
else:
early_stop_count += 1
if early_stop_count >= early_stopping:
print(f"Epoch: {epoch + 1}, model not improving, early stopping.")
break
else:
print(f'[{epoch+1:03d}/{num_epoch:03d}] Acc: {acc:3.6f} Loss: {loss:3.6f}')
# if not validating, save the last epoch
if len(val_set) == 0:
torch.save(model.state_dict(), model_path)
print('saving model at last epoch')
T: 1/50: 100%|██████████| 1034/1034 [01:03<00:00, 16.34it/s, lr=0.0005, batch acc=0.629, acc=0.587, loss=1.36]
V: 1/50: 100%|████████████████████████████████| 258/258 [00:08<00:00, 31.96it/s, val acc=0.661, val loss=1.08]
saving model with acc 0.661
T: 2/50: 100%|████████| 1034/1034 [00:57<00:00, 17.94it/s, lr=0.000483, batch acc=0.676, acc=0.646, loss=1.13]
V: 2/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 35.71it/s, val acc=0.685, val loss=0.994]
saving model with acc 0.685
T: 3/50: 100%|████████| 1034/1034 [00:57<00:00, 18.01it/s, lr=0.000434, batch acc=0.672, acc=0.667, loss=1.06]
V: 3/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 36.54it/s, val acc=0.701, val loss=0.943]
saving model with acc 0.701
T: 4/50: 100%|██████████| 1034/1034 [00:59<00:00, 17.24it/s, lr=0.000361, batch acc=0.7, acc=0.681, loss=1.01]
V: 4/50: 100%|████████████████████████████████| 258/258 [00:07<00:00, 34.34it/s, val acc=0.71, val loss=0.912]
saving model with acc 0.710
T: 5/50: 100%|███████| 1034/1034 [01:01<00:00, 16.80it/s, lr=0.000275, batch acc=0.671, acc=0.693, loss=0.965]
V: 5/50: 100%|████████████████████████████████| 258/258 [00:07<00:00, 34.58it/s, val acc=0.719, val loss=0.88]
saving model with acc 0.719
T: 6/50: 100%|███████| 1034/1034 [01:02<00:00, 16.49it/s, lr=0.000189, batch acc=0.719, acc=0.703, loss=0.932]
V: 6/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 34.44it/s, val acc=0.725, val loss=0.864]
saving model with acc 0.725
T: 7/50: 100%|████████| 1034/1034 [01:02<00:00, 16.59it/s, lr=0.000116, batch acc=0.704, acc=0.71, loss=0.907]
V: 7/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 34.48it/s, val acc=0.729, val loss=0.848]
saving model with acc 0.729
T: 8/50: 100%|█████████| 1034/1034 [01:02<00:00, 16.51it/s, lr=6.71e-5, batch acc=0.704, acc=0.715, loss=0.89]
V: 8/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 35.02it/s, val acc=0.732, val loss=0.841]
saving model with acc 0.732
T: 9/50: 100%|█████████| 1034/1034 [01:02<00:00, 16.54it/s, lr=0.0005, batch acc=0.712, acc=0.698, loss=0.947]
V: 9/50: 100%|████████████████████████████████| 258/258 [00:07<00:00, 34.85it/s, val acc=0.722, val loss=0.87]
T: 10/50: 100%|██████| 1034/1034 [01:03<00:00, 16.36it/s, lr=0.000496, batch acc=0.731, acc=0.702, loss=0.931]
V: 10/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 35.65it/s, val acc=0.725, val loss=0.859]
T: 11/50: 100%|██████| 1034/1034 [01:02<00:00, 16.44it/s, lr=0.000483, batch acc=0.698, acc=0.708, loss=0.914]
V: 11/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 34.54it/s, val acc=0.73, val loss=0.847]
T: 12/50: 100%|██████| 1034/1034 [01:02<00:00, 16.44it/s, lr=0.000462, batch acc=0.732, acc=0.712, loss=0.898]
V: 12/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.87it/s, val acc=0.732, val loss=0.839]
T: 13/50: 100%|██████| 1034/1034 [01:02<00:00, 16.52it/s, lr=0.000434, batch acc=0.721, acc=0.717, loss=0.881]
V: 13/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.02it/s, val acc=0.735, val loss=0.827]
saving model with acc 0.735
T: 14/50: 100%|████████| 1034/1034 [01:02<00:00, 16.48it/s, lr=0.0004, batch acc=0.722, acc=0.721, loss=0.867]
V: 14/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 36.40it/s, val acc=0.738, val loss=0.819]
saving model with acc 0.738
T: 15/50: 100%|██████| 1034/1034 [01:02<00:00, 16.52it/s, lr=0.000361, batch acc=0.705, acc=0.725, loss=0.853]
V: 15/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 34.40it/s, val acc=0.74, val loss=0.814]
saving model with acc 0.740
T: 16/50: 100%|██████| 1034/1034 [01:02<00:00, 16.56it/s, lr=0.000319, batch acc=0.736, acc=0.729, loss=0.839]
V: 16/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.95it/s, val acc=0.743, val loss=0.805]
saving model with acc 0.743
T: 17/50: 100%|██████| 1034/1034 [01:02<00:00, 16.63it/s, lr=0.000275, batch acc=0.709, acc=0.733, loss=0.825]
V: 17/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 35.12it/s, val acc=0.744, val loss=0.799]
saving model with acc 0.744
T: 18/50: 100%|██████| 1034/1034 [01:02<00:00, 16.44it/s, lr=0.000231, batch acc=0.739, acc=0.736, loss=0.814]
V: 18/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 36.27it/s, val acc=0.746, val loss=0.793]
saving model with acc 0.746
T: 19/50: 100%|███████| 1034/1034 [01:03<00:00, 16.36it/s, lr=0.000189, batch acc=0.756, acc=0.74, loss=0.802]
V: 19/50: 100%|███████████████████████████████| 258/258 [00:08<00:00, 31.98it/s, val acc=0.747, val loss=0.79]
saving model with acc 0.747
T: 20/50: 100%|███████| 1034/1034 [01:03<00:00, 16.21it/s, lr=0.00015, batch acc=0.741, acc=0.742, loss=0.792]
V: 20/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.22it/s, val acc=0.748, val loss=0.787]
saving model with acc 0.748
T: 21/50: 100%|██████| 1034/1034 [01:04<00:00, 16.01it/s, lr=0.000116, batch acc=0.719, acc=0.745, loss=0.783]
V: 21/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 34.87it/s, val acc=0.75, val loss=0.782]
saving model with acc 0.750
T: 22/50: 100%|███████| 1034/1034 [01:04<00:00, 15.97it/s, lr=8.79e-5, batch acc=0.733, acc=0.747, loss=0.776]
V: 22/50: 100%|███████████████████████████████| 258/258 [00:07<00:00, 33.96it/s, val acc=0.751, val loss=0.78]
saving model with acc 0.751
T: 23/50: 100%|████████| 1034/1034 [01:04<00:00, 15.97it/s, lr=6.71e-5, batch acc=0.776, acc=0.749, loss=0.77]
V: 23/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.76it/s, val acc=0.751, val loss=0.778]
saving model with acc 0.751
T: 24/50: 100%|████████| 1034/1034 [01:03<00:00, 16.22it/s, lr=5.43e-5, batch acc=0.751, acc=0.75, loss=0.766]
V: 24/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.39it/s, val acc=0.752, val loss=0.778]
saving model with acc 0.752
T: 25/50: 100%|████████| 1034/1034 [01:02<00:00, 16.50it/s, lr=0.0005, batch acc=0.724, acc=0.733, loss=0.824]
V: 25/50: 100%|██████████████████████████████| 258/258 [00:06<00:00, 36.92it/s, val acc=0.743, val loss=0.803]
T: 26/50: 100%|██████| 1034/1034 [01:02<00:00, 16.57it/s, lr=0.000499, batch acc=0.714, acc=0.732, loss=0.826]
V: 26/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.60it/s, val acc=0.744, val loss=0.802]
T: 27/50: 100%|██████| 1034/1034 [01:02<00:00, 16.46it/s, lr=0.000496, batch acc=0.702, acc=0.733, loss=0.823]
V: 27/50: 100%|████████████████████████████████| 258/258 [00:07<00:00, 34.61it/s, val acc=0.745, val loss=0.8]
T: 28/50: 100%|███████| 1034/1034 [01:03<00:00, 16.35it/s, lr=0.00049, batch acc=0.712, acc=0.734, loss=0.818]
V: 28/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 35.71it/s, val acc=0.745, val loss=0.797]
T: 29/50: 100%|██████| 1034/1034 [01:02<00:00, 16.55it/s, lr=0.000483, batch acc=0.726, acc=0.735, loss=0.813]
V: 29/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 36.43it/s, val acc=0.746, val loss=0.794]
T: 30/50: 100%|██████| 1034/1034 [01:02<00:00, 16.60it/s, lr=0.000473, batch acc=0.745, acc=0.737, loss=0.808]
V: 30/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 35.16it/s, val acc=0.746, val loss=0.791]
T: 31/50: 100%|██████| 1034/1034 [01:02<00:00, 16.63it/s, lr=0.000462, batch acc=0.705, acc=0.739, loss=0.802]
V: 31/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.56it/s, val acc=0.749, val loss=0.787]
T: 32/50: 100%|████████| 1034/1034 [01:02<00:00, 16.42it/s, lr=0.000449, batch acc=0.73, acc=0.74, loss=0.797]
V: 32/50: 100%|██████████████████████████████| 258/258 [00:07<00:00, 34.74it/s, val acc=0.749, val loss=0.786]
Epoch: 32, model not improving, early stopping.
del train_loader, val_loader
gc.collect()
0
Testing
Create a testing dataset, and load model from the saved checkpoint.
# load data
test_X = preprocess_data(split='test', feat_dir='./libriphone/feat', phone_path='./libriphone', concat_nframes=concat_nframes)
test_set = LibriDataset(test_X, None)
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False)
[Dataset] - # phone classes: 41, number of utterances for test: 1078
1078it [00:02, 520.90it/s]
[INFO] test set
torch.Size([646268, 741])
# load model
model = Classifier(input_dim=input_dim, hidden_layers=hidden_layers, hidden_dim=hidden_dim).to(device)
model.load_state_dict(torch.load(model_path))
<All keys matched successfully>
Make prediction.
test_acc = 0.0
test_lengths = 0
pred = np.array([], dtype=np.int32)
model.eval()
with torch.no_grad():
for i, batch in enumerate(tqdm(test_loader)):
features = batch
features = features.to(device)
outputs = model(features)
_, test_pred = torch.max(outputs, 1) # get the index of the class with the highest probability
pred = np.concatenate((pred, test_pred.cpu().numpy()), axis=0)
100%|██████████████████████████████████████████████████████████████████| 316/316 [00:05<00:00, 53.00it/s]
Write prediction to a CSV file.
After finish running this block, download the file prediction.csv from the files section on the left-hand side and submit it to Kaggle.
with open('prediction.csv', 'w') as f:
f.write('Id,Class\n')
for i, y in enumerate(pred):
f.write('{},{}\n'.format(i, y))
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java 实现自动获取法定节假日
- Altium Designer软件界面切换为浅灰色与深灰色的方法图文教程及视频演示
- 网络工程师:软件编程基础知识面试题(九)
- opcode end
- Vue 点击按钮复制内容到系统剪贴板
- 高级编程JavaScript中的数据类型?存储上能有什么差别?
- 《二叉树》——2
- GPIO口工作原理的超详细解释(附电路图)
- Python中使用HTTP代理进行网络请求
- vfb控件数组的实现原理(visual freebasic ide),64位VB6 vb7