Linux云服务器 虚拟机 docker容器安装消息中间件kafka
发布时间:2023年12月31日
1.大数据的杀手锏,谈到大数据领域内的消息传输,则绕不开Kafka,这款为大数据而生的消息中间件,以其百万级TPS的吞吐量名声大噪,迅速成为大数据领域的宠儿,在数据采集、传输存储的过程中发挥着举足轻重的作用。目前已经被LinkedIn,,Uber,Twitter,Netflix等大公司所采纳。
优点:性能卓越,单机写入TPS约在百万条/秒,最大的优点,就是吞吐量高。时效性ms级可用性非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用,消费者采用Pul方式获取消息,消息有序,通过控制能够保证所有消息被消费且仅被消费一次;有优秀的第三方
Kafka Web管理界面Kafka-Manager;在日志领域比较成熟,被多家公司和多个开源项目使用;功能支持:功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用
缺点:Kafka 单机超过64个队列/分区,Load 会发生明显的飙高现象,队列越多load越高,发送消息响应时间变长,使用短轮询方式,实时性取决于轮询间隔时间,消费失败不支持重试;支持消息顺序,但是一台代理宕机后,就会产生消息乱序,社区更新较慢;
我是Java领域 不会涉及太多这种高并发,?RabbitMq 万级并发就足够
安装之前是要必须安装 JDK1.8+的和docker容器的
下面来开始安装 kafka? 安装之前先安装zookeeper
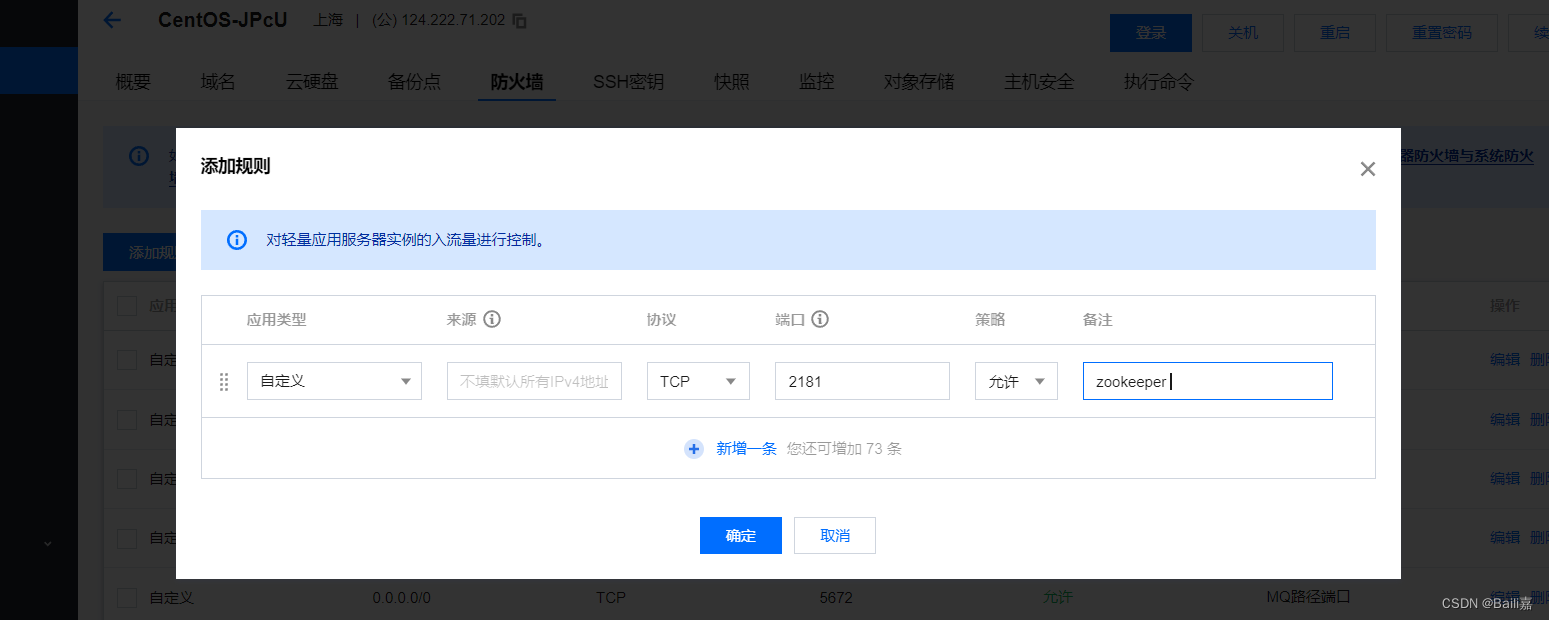
先安装?zookeeper? 放开端口号? 2181?9092

在
docker
目录下创建一个文件夹、
去docker 目录下
cd usr/local/docker创建?zookeeper文件夹
mkdir zookeeper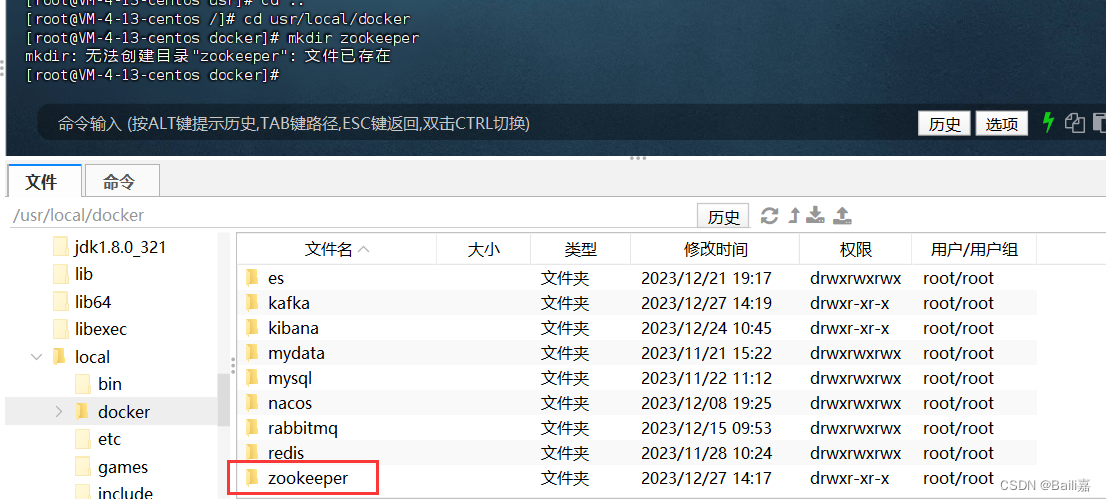
跳转到该目录下
cd zookeeper/
用docker拉去zookeeper镜像
镜像拉取好后配置启动容器
编辑启动文件
vim startZookeeper.sh粘贴此内容:
docker run -d \
--privileged=true \
--name zookeeper \
--restart=always \
-p 2181:2181 zookeeper:3.4.14
按ESC :wq! 退出
后给启动文件赋予权限
最大权限? 可读可写可执行
chmod -R 777 startZookeeper.sh安装好zookeeper后在docker目录下创建一个kafka目录
cd .. 返回docker
mkdir kafka
创建好跳转到该目录下
使用docker拉取kafka镜像
docker pull wurstmeister/kafka:2.12-2.3.1
镜像拉取好后,编辑
kafka
启动文件
vim startKafka.sh将以下配置粘贴到启动文件中
?注意看 你自己云服务器ip的地方? 改一下你自己的ip 不要纯粘贴不看!!?
配置好文件后,输入:wq!保存并退出? 注意看内容 :(改自己云服务器ip)?
docker run -d \
--privileged=true \
--name kafka \
--restart=always \
--env KAFKA_ADVERTISED_HOST_NAME=你自己的云服务器ip \
--env KAFKA_ZOOKEEPER_CONNECT=你自己的云服务器ip:2181 \
--env KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://你自己的云服务器ip:9092 \
--env KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms256M" \
--net=host wurstmeister/kafka:2.12-2.3.1
按?ESC:wq! 退出
结束后赋予脚本权限
chmod -R 777 脚本
运行:
./startKafka.sh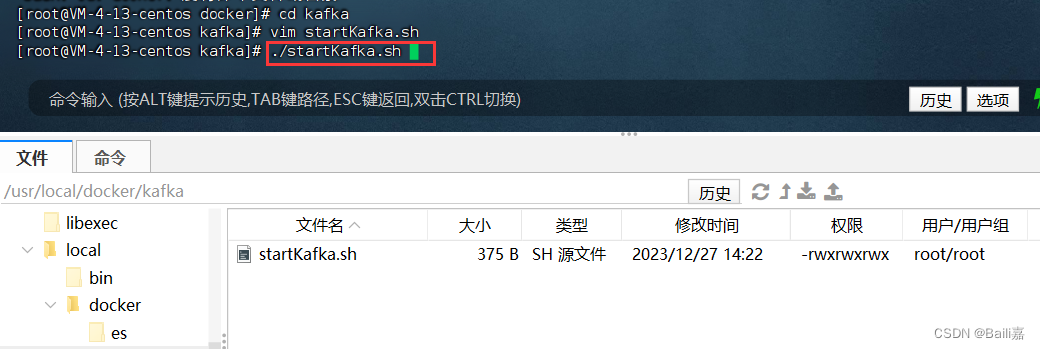
docker ps -a 查看
ok了

文章来源:https://blog.csdn.net/weixin_58639087/article/details/135246120
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!