K-means聚类算法
发布时间:2024年01月04日
聚类,是指有一堆数据,不知道他们应该怎么分类,用算法将他们聚到一起进行分类。
K-means聚类算法是聚类算法中最基础的一个算法,虽然基础,但由于其出色的性能和相对较好的效果,至今依然是主流的聚类算法之一。
K-means原理
首先,我们有一堆数据,如下图:

我们能看出来数据大概能分成如下三组,在聚类中称为“簇”
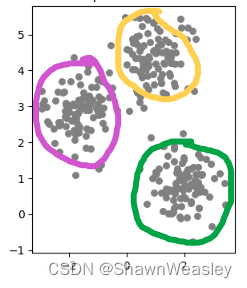
具体如何分呢?
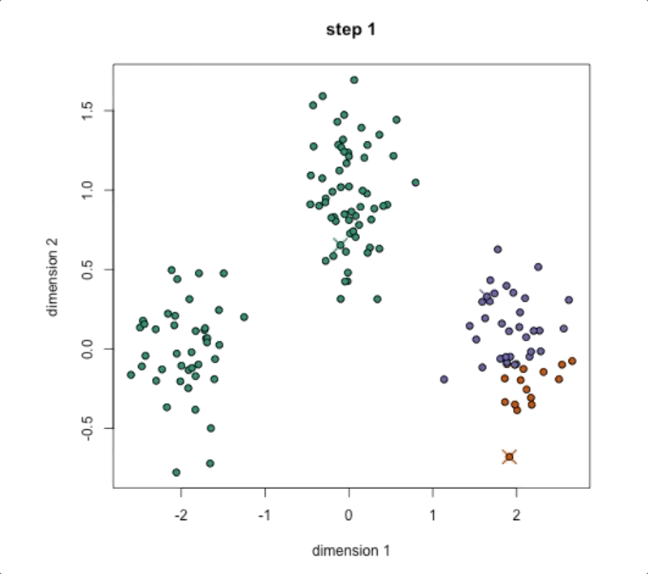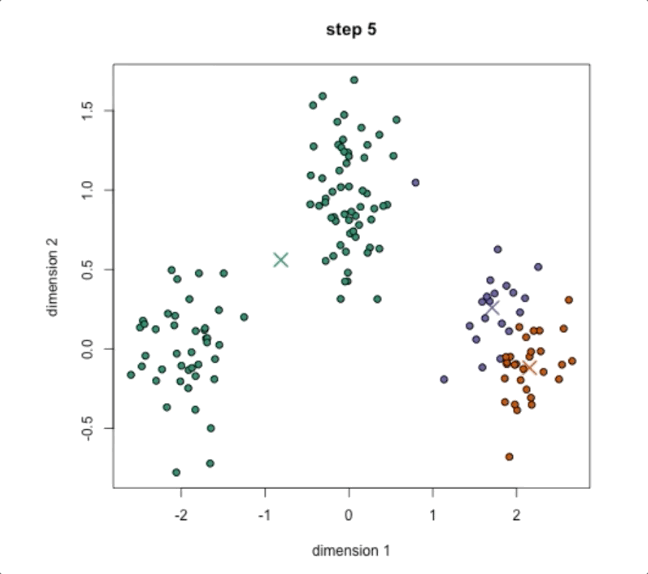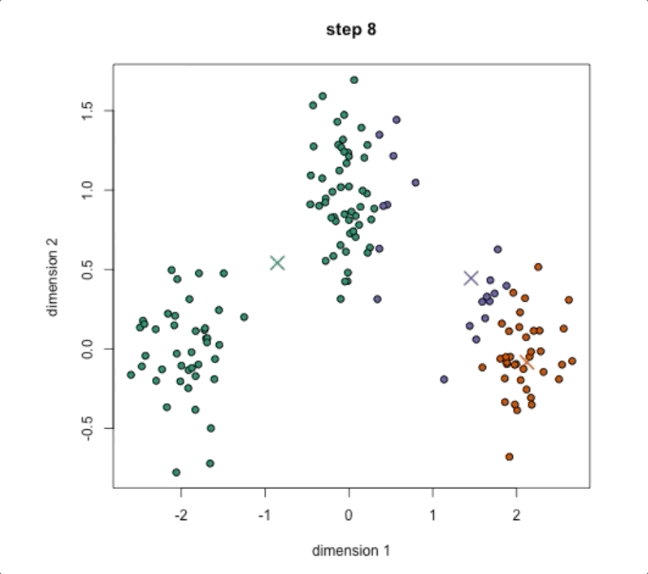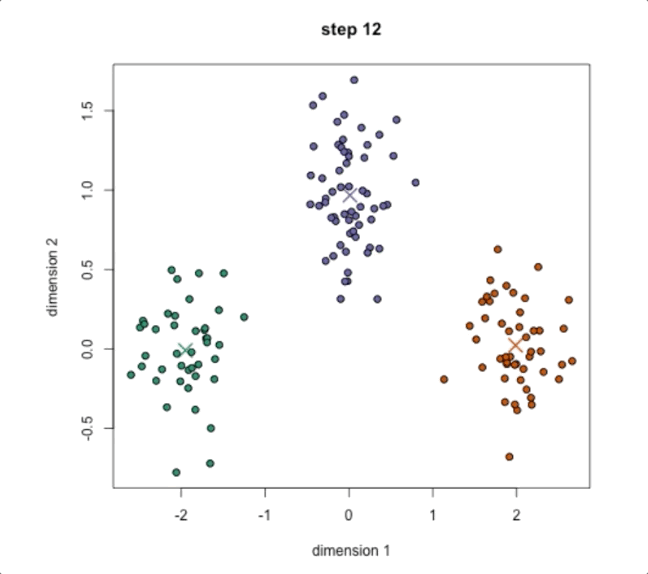
Step1:随机选择K个数据点作为初始聚类中心,比如我们想把这个数据分成3类,就先随机找三个点作为中心
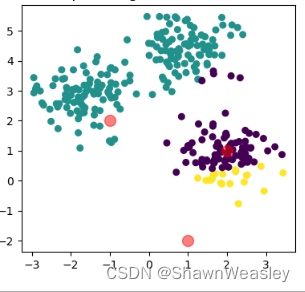
Step2:然后将每个数据点分配给最近的聚类中心,从而形成3个簇,就是上图中的绿色、紫色、黄色三个簇
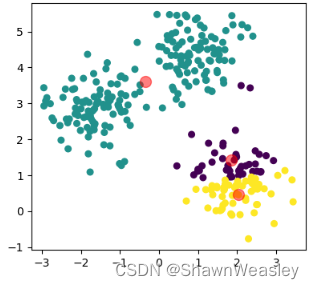
Step3:基于当前的簇,重新计算每个簇的中心。这通常通过计算每个簇内所有点的均值来完成。再将我们的中心移动到计算出来的簇的中心,如下图
Step4:不断重复步骤2和3直到结果收敛,不发生变化,如下图
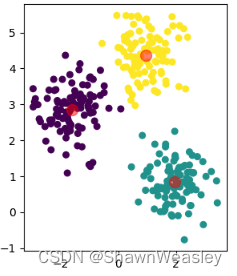
这样我们就完成了算法,实现了聚类,可以看到结果和我们初始期望的结果非常符合。
很容易理解的是:K-means是一种无监督学习算法,因为我们没有告诉它任何点应该是哪个分类,它只是将数据实现了分割,但不理解每个簇的意义。
我们用基础的鸢尾花数据集使用K-means进行分类,结果达到了0.893的正确率,说明鸢尾花的数据集彼此之间的特征比较紧密才会获得这么高的分数,但通常情况下K-means不用于预测正确率,因为它不是为了预测已知标签而设计的,聚类算法仅仅是将特征接近的数据聚到一起而已。
from sklearn import datasets
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score
from scipy.stats import mode
import numpy as np
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
# 应用K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)
# 真实标签
labels_true = iris.target
# 将预测的标签与真实的标签对齐
labels_pred = np.zeros_like(y_kmeans)
for i in range(3):
mask = (y_kmeans == i)
labels_pred[mask] = mode(labels_true[mask])[0]
# 计算正确率
accuracy = accuracy_score(labels_true, labels_pred)
print(accuracy)
在使用K-means聚类算法过程中有几个需要注意的点:
- 初始中心的选择可能对最终结果有很大影响。有时,不同的初始化会导致不同的聚类结果。为了减少这种影响,可以多次运行聚类算法,并从中选择最好的结果。
- 在不了解K(簇的数量设定)的情况下,通常使用诸如肘部方法(Elbow Method)或轮廓系数(Silhouette Coefficient)等技术来估计最佳的簇数K。
- 通常在应用K-means之前,需要对数据进行预处理(如标准化或归一化),特别是当不同特征的尺度相差很大时。
整体可视化过程如下
文章来源:https://blog.csdn.net/eevee_1/article/details/135388072
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 八个理由:从java8升级到Java17
- .NET Core NPOI导出复杂Excel
- Unity中URP下的SimpleLit的 Lambert漫反射计算
- 2024年【烟花爆竹经营单位主要负责人】考试题库及烟花爆竹经营单位主要负责人最新解析
- vp与vs联合开发-加载block工具
- 多传感器融合SLAM数学学习历程
- 西门子博途PLC程序加密的一种方法(密钥授权管理程序)
- mac PyCharm 上传文件到远程服务器+远程服务器下载到本地
- InnoDB的Buffer Pool
- 12.31_黑马数据结构与算法笔记Java