linux磁盘总结
什么是page_cache
linux读写磁盘,如果都是采用directIO的话,效率太低,所以我们在读写磁盘上加了一层缓存,page_cache。读的话,如果page_cache有的话,就不用向磁盘发出请求。写的话,也直接写入的page_cache就行了,异步刷回磁盘(操作系统不crash,不会丢失)。
如果查看page_cache的大小:cat /proc/meminfo
 而SwapCached是在打开了Swap分区后,把Inactive(anon)+Active(anon)这两项里的匿名页给交换到磁盘(swap out),然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的Swap File还在,所以SwapCached也可以认为是File-backed page,即属于Page Cache
而SwapCached是在打开了Swap分区后,把Inactive(anon)+Active(anon)这两项里的匿名页给交换到磁盘(swap out),然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的Swap File还在,所以SwapCached也可以认为是File-backed page,即属于Page Cache
page_cache如何产生
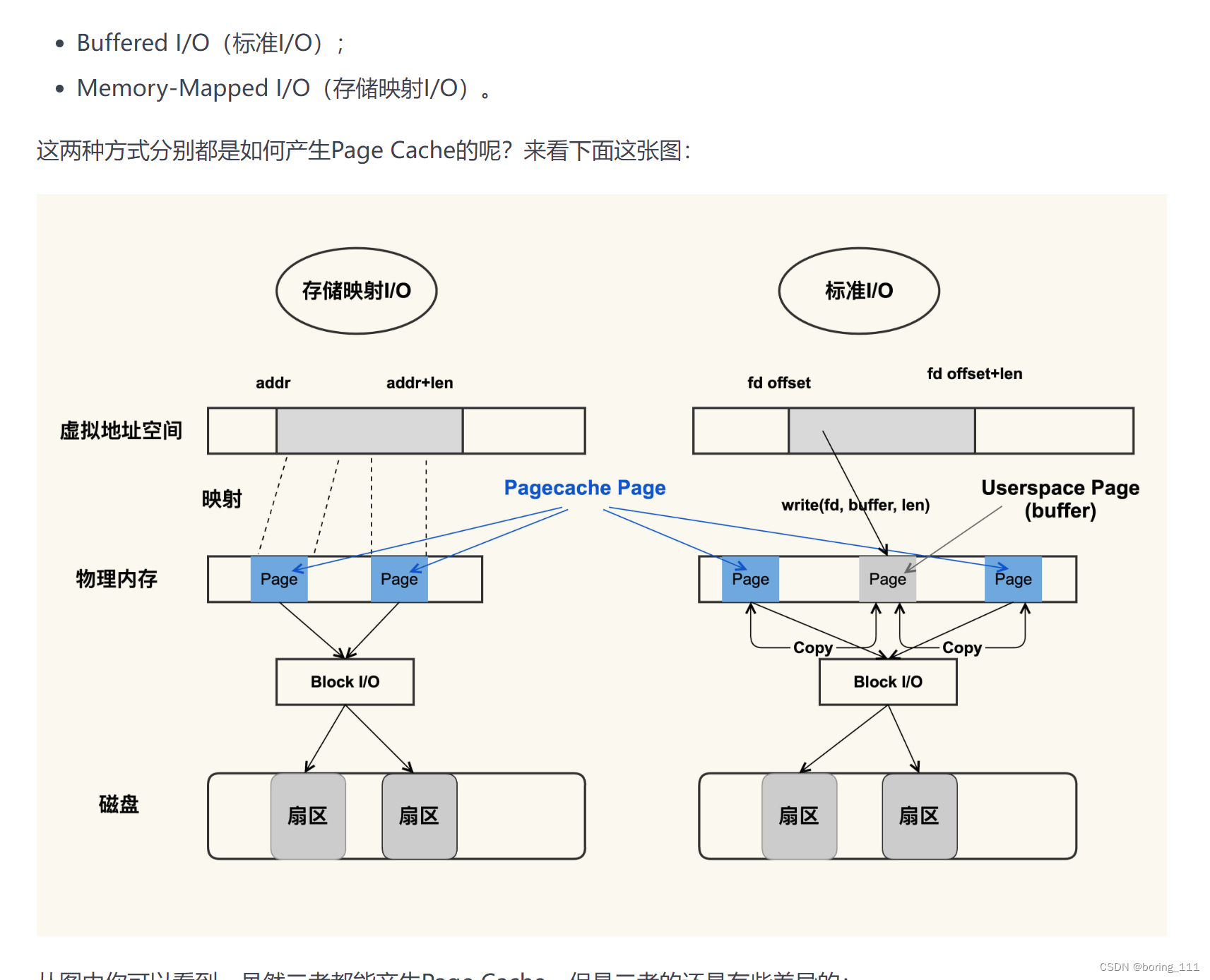 ?第一种比第二种更加高效,毕竟少了用户态和内核态的复制。
?第一种比第二种更加高效,毕竟少了用户态和内核态的复制。
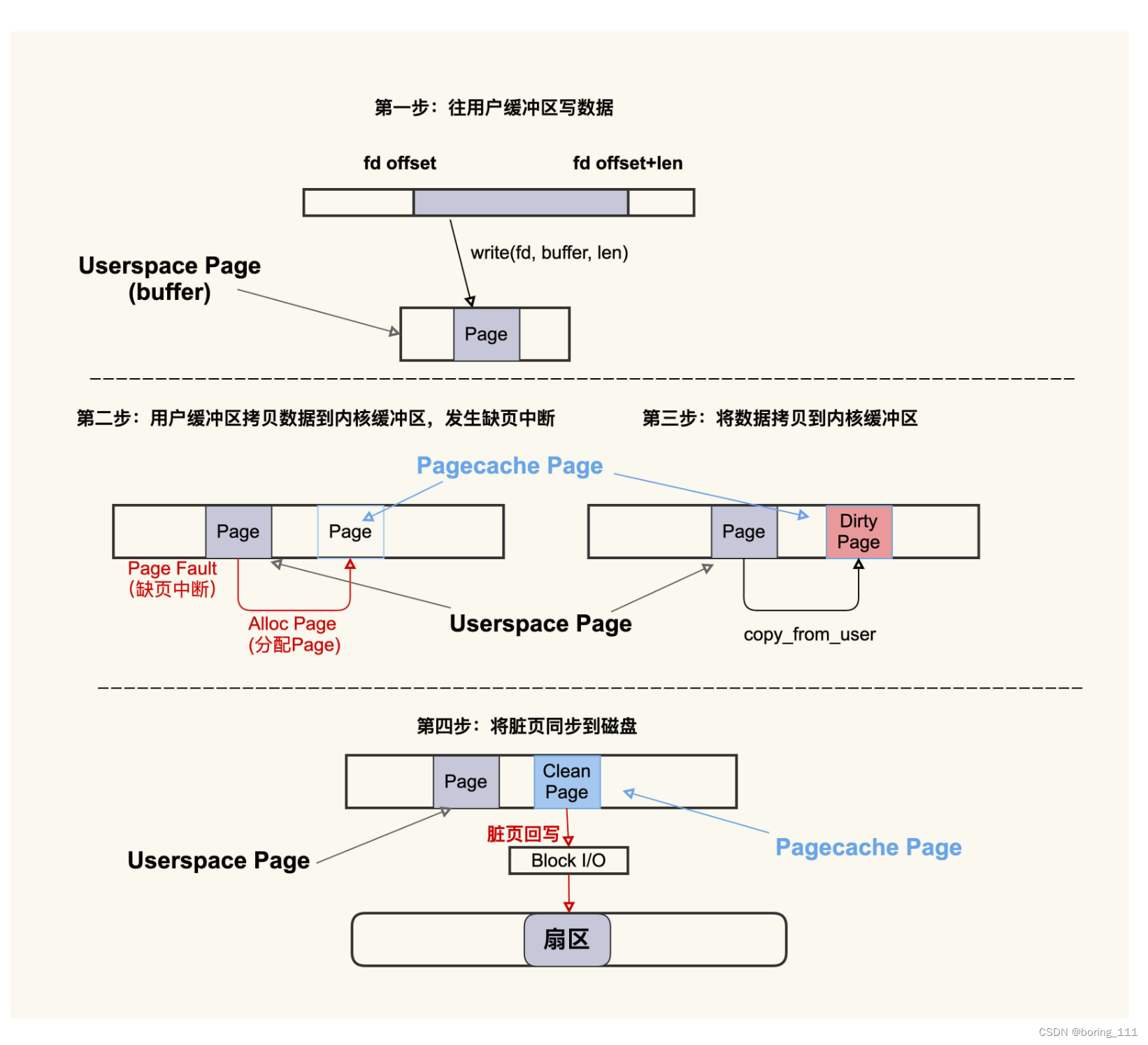
cat /proc/vmstat | egrep "dirty|writeback" 可以查看这个过程
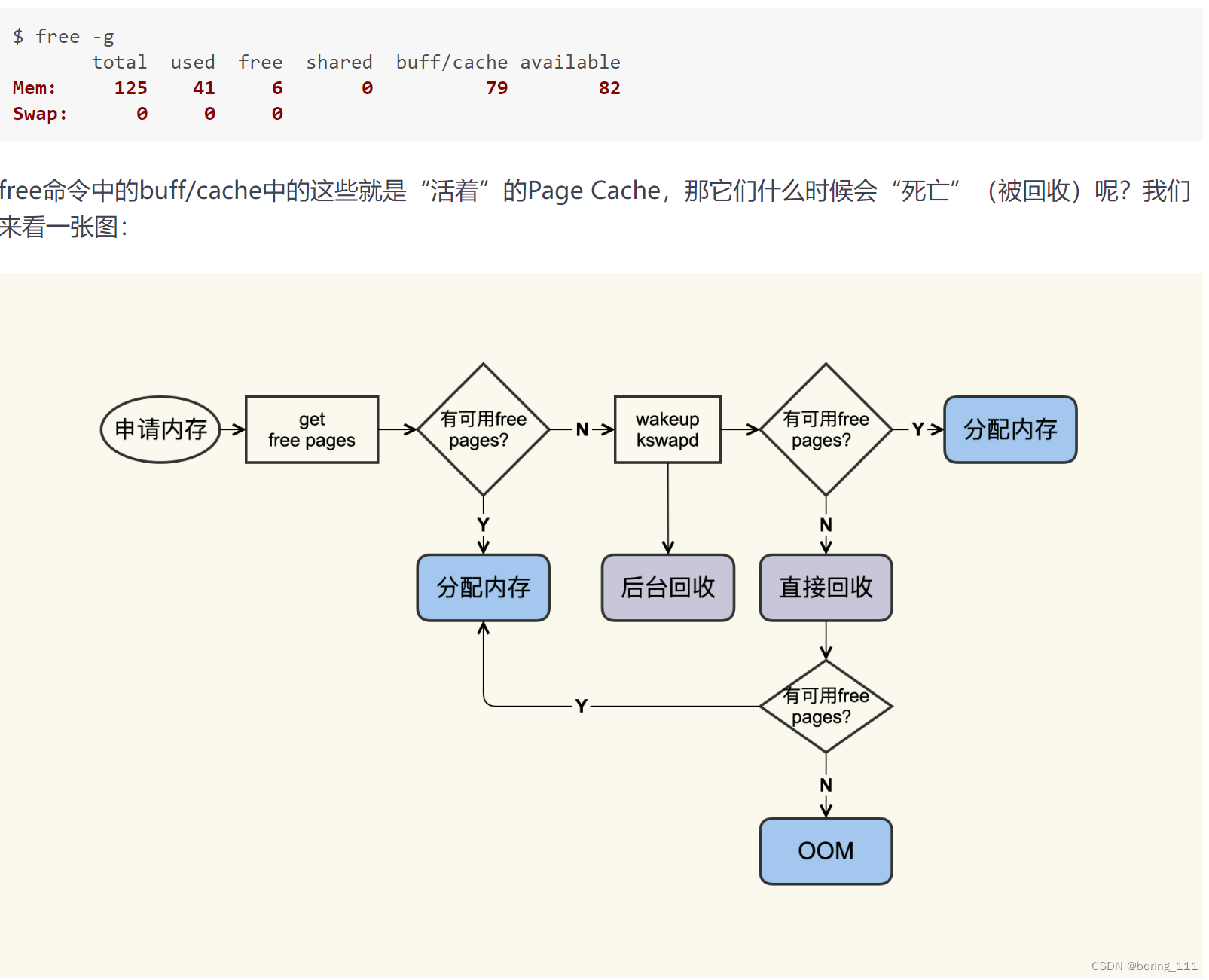
page_cache如何回收呢
 ?
?
回收内存时发生抖动是因为触达了慢速度路径
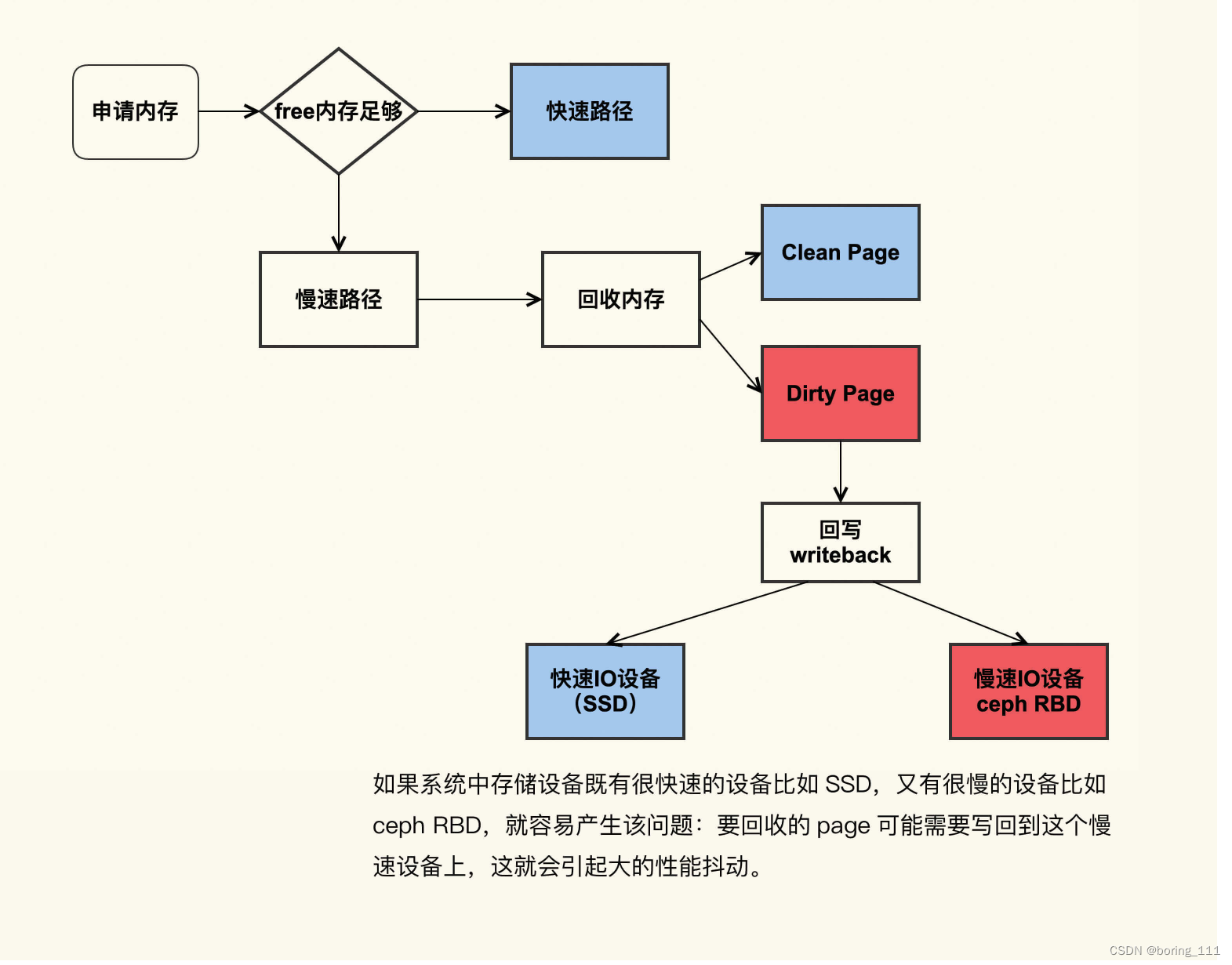
也可能是NUMA配置不佳。但相比内存回收的危害而言,NUMA带来的性能提升几乎可以忽略,所以配置为0,利远大于弊。
page_cache操作不对,对业务有影响
进程会通过inode来找到文件的地址空间(address_space),然后结合文件偏移(会转换成page index)来找具体的Page。理解为inode是Pagecache Page(页缓存的页)的宿主(host),如果inode不存在了,那么PageCache Page也就不存在了。
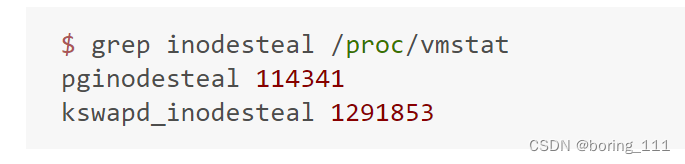
可以这样查看。
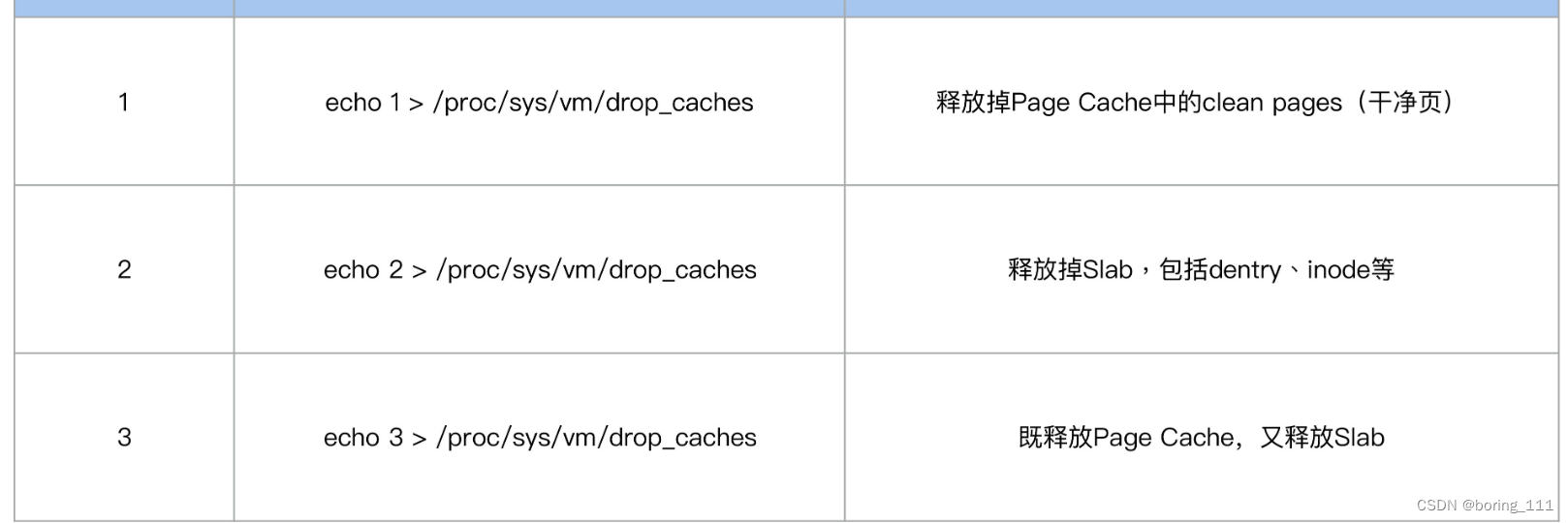
当我们执行echo 2来drop slab的时候,它也会把Page Cache给drop掉,很多运维人员都会忽视掉这一点。并且操作系统回收slab(innode)的memory时也同样可能发生这种情况。
解决办法
1.
2.是通过memory_cgroup来将他管理起来
memory cgroup提供了几个内存水位控制线memory.{min, low, high, max} 。
-
memory.max- 这是指memory cgroup内的进程最多能够分配的内存,如果不设置的话,就默认不做内存大小的限制。
-
memory.high- 如果设置了这一项,当memory cgroup内进程的内存使用量超过了该值后就会立即被回收掉,所以这一项的目的是为了尽快的回收掉不活跃的Page Cache。
-
memory.low- 这一项是用来保护重要数据的,当memory cgroup内进程的内存使用量低于了该值后,在内存紧张触发回收后就会先去回收不属于该memory cgroup的Page Cache,等到其他的Page Cache都被回收掉后再来回收这些Page Cache。
-
memory.min- 这一项同样是用来保护重要数据的,只不过与memoy.low有所不同的是,当memory cgroup内进程的内存使用量低于该值后,即使其他不在该memory cgroup内的Page Cache都被回收完了也不会去回收这些Page Cache,可以理解为这是用来保护最高优先级的数据的。
那么,如果你想要保护你的Page Cache不被回收,你就可以考虑将你的业务进程放在一个memory cgroup中,然后设置memory.{min,low} 来进行保护;与之相反,如果你想要尽快释放你的Page Cache,那你可以考虑设置memory.high来及时的释放掉不活跃的Page Cache。
定位方法论
当然这套分析方法论不仅仅适用于Page Cache引发的问题,对于系统其他层面引起的问题同样也适用。让我们再次回顾一下这些要点:
- 在观察Page Cache的行为时,你可以先从最简单易用的分析工具比如sar入手,来得到一个概况,然后再使用更加专业一些的工具比如tracepoint去做更细致的分析。这样你就能分析清楚Page Cache的详细行为,以及它为什么会产生问题;
- 对于很多的偶发性的问题,往往需要采集很多的信息才能抓取出来问题现场,这种场景下最好使用perf script来写一些自动化分析的工具来提升效率;
- 如果你担心分析工具会对生产环境产生性能影响,你可以把信息采集下来之后进行离线分析,或者使用ebpf来进行自动过滤分析,请注意ebpf需要高版本内核的支持。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【信息论与编码】习题-判断题-第三部分
- C++数据科学与机器学习基础
- CentOS7自动备份数据库到git
- LeetCode 每日一题 Day 37-43
- 【?电力电子在电力系统中的应用?】6 滞环电流控制的PWM整流器 + STATCOM整流器 + APF仿真
- 2023 X-GAME 大数据竞赛圆满落幕,和鲸连续四年助推新能源汽车产业发展
- 前端(二十)——Vite和Webpack:前端开发中常用的构建工具
- Spark 初级编程实践
- 短信平台搭建注意什么|网页版短信系统开发源码
- 【梅西迭代姊妹篇2】BCH码和m序列参数估计(梅西迭代算法求多项式的C语言实现)