工业产品表面缺陷检测算法
介绍
经典缺陷检测算法整理,包含PaDiM(2020ICPR)、PatchCore(2022CVPR)、SimpleNet(2023CVPR)、EfficientAD(2023)。
代码仓库:https://gitee.com/zhgn2020814/Defect_detection.git
文中部分图源见水印
1、PaDiM
问题:
- 异常检测:实际应用中缺乏异常样本,并且异常可能会有意想不到的模式,不能使用完全监督的方法训练模型,即训练数据集仅包含正常类的图像。
- 目前的单类别学习模式的异常检测模型要么需要训练深度神经网络,非常麻烦。要么测试阶段在整个训练集上使用K最近邻算法,KNN算法线性复杂度的特点导致随着训练集的增大,其时间和空间复杂度也随之增大。
创新:
PaDiM利用预训练好的CNN进行embedding提取,并且具有以下两个特点:(1)每个patch位置都用一个多元高斯分布来描述。(2)PaDiM考虑到了CNN不同语义层之间的关联。
此外,在测试阶段,它的时间和空间复杂度都比较小,且独立于训练集的大小,这非常有利于工业部署应用。对于异常检测和定位任务,在MVTec AD和ShanghaiTec Campus两个数据集上,PaDiM超越了现有SOTA方法(2020年本文提出时)。
详细:
- Embedding extraction(嵌入向量提取)
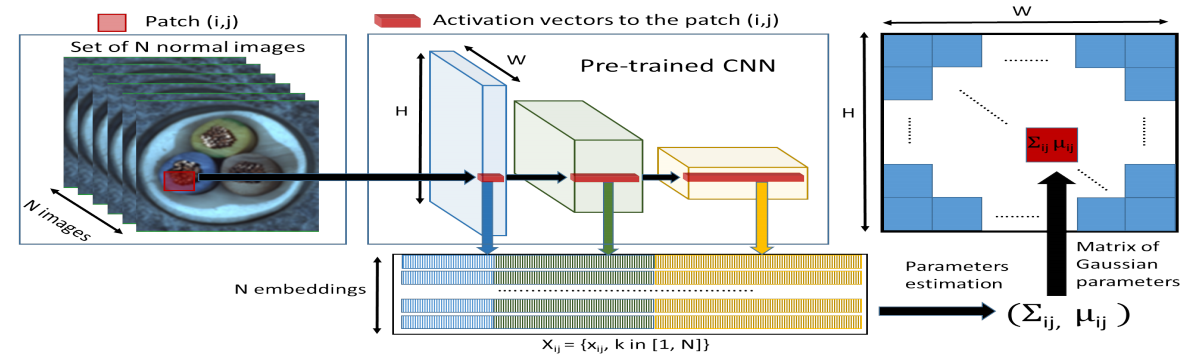
将预训练模型中三个不同层的feature map对应位置进行拼接得到embedding vector,这里分别取resnet18中layer1、layer2、layer3的最后一层,模型输入大小为224x224,这三层对应输出维度分别为(209,64,56,56)、(209,128,28,28)、(209,256,14,14),这里实现1中是通过将小特征图每个位置复制多份得到与大特征图同样的spatial size,然后再进行拼接。比如28x28的特征图中一个1x1的patch与56x56的特征图中对应位置的2x2的patch相对应,将该1x1的patch复制4份得到2x2大小patch后再与56x56对应位置的2x2 patch进行拼接
将三个不同语义层的特征图进行拼接后得到(209,448,56,56)大小的patch嵌入向量可能带有冗余信息,因此作者对其进行了降维,作者发现随机挑选某些维度的特征比PCA更有效,在保持sota性能的前提下降低了训练和测试的复杂度,文中维度选择100,因此输出为(209,100,56,56)
- Learning of the normality(正常特征学习)
为了学习正常图像在位置**(i,j)处的特征,我们首先计算N张正常训练图片在位置(i,j)处的嵌入向量集和 Xij= {xk ij, k ∈[[1, N]]}。为了整合这个set的信息假设,我们假设Xij**由多元高斯分布 N (μij, Σij)得到的,其中μij 是 Xij 的样本均值,样本协方差 Σij通过下式估计得到
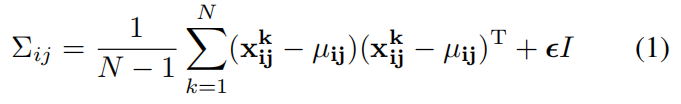
其中正则项 ?I 保证协方差矩阵时满秩且可逆的,如上图右所示,图像中每个位置都通过高斯参数矩阵与一个多元高斯分别相关联。
- Inference: computation of the anomaly map(推理:异常图的计算)
我们使用马氏距离**M (xij )给测试图像位置(i,j)**的 patch 一个异常分数。M (xij )可以解释为嵌入xij
与学习分布**N(μij,Σij )**之间的距离,计算公式如下:

- 损失函数
AUC:ROC(Receiver Operating Characteristic)曲线是以假正率(FPR)和真正率(TPR)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
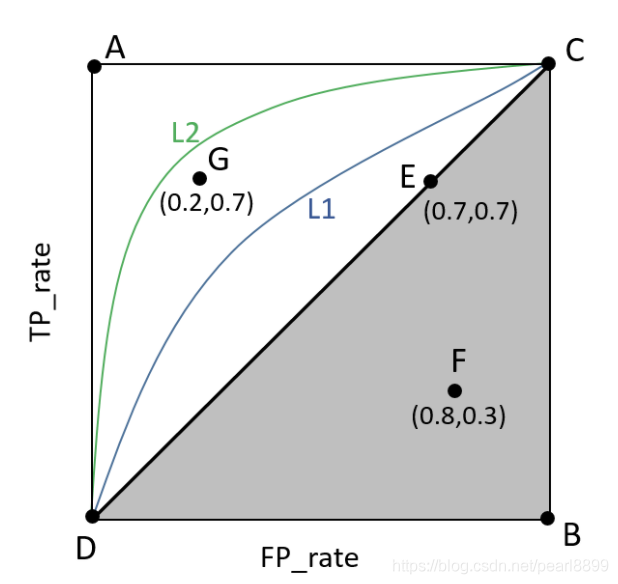
真正例率 TPR = TP / (TP + FN) 表示,预测为正例且真实情况为正例的,占所有真实情况中正例的比率。 假正例率 FPR = FP /(TN + FP)表示的,预测为正例但真实情况为反例的,占所有真实情况中反例的比率。 TPR越大,则表示挑出的越有可能(是正确的);FPR越大,则表示越不可能(在挑选过程中,再挑新的出来,即再挑认为是正确的出来,越有可能挑的是错误的)
2、PatchCore
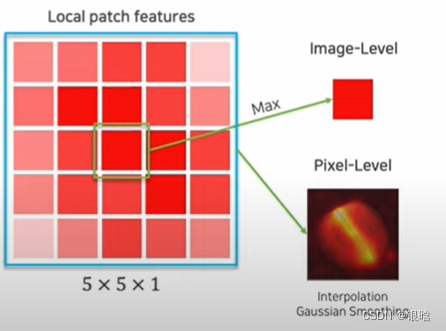
PatchCore 作为一种异常检测技术于2021年推出,旨在在工业应用中实现全面召回。如下图所示,PatchCore 有2个主要步骤。==首先,它从正常图像块中提取局部感知特征。之后,它应用子采样技术(核心集)来近似这些特征并构建一组描述正常模式的补丁特征。在测试时,为测试样本提取补丁特征,并使用最近邻方法计算异常分数。

问题
- 冷启动问题:在训练集中都是正常的图片,模型很容易捕获到正常图像的特征,但是很难捕获到异常缺陷的样本
- 分布漂移。正常图像和异常图像分布是不一样的,模型学习的是正常图像的数据分布,而异常图像的数据分布和正常图像不一样
详细
-
使用中间 ResNet 表示
采用ResNet-50/ WideResNet-50进行特征提取,由4个残差块组成。一般来说,获取提取的特征是在ResNet最后一层获取,但是存在两个问题
- 损失太多的信息
- 深度抽象的特征对当前的分类任务存在较大的偏差,因为冷启动带来的问题,缺陷特征很少,很难推测出来
解决:
- 创建一个存储块:memory bank,存储patch features(可理解为块特征)
- 不从Resnet最后一层获取特征,而是从中间获取:

- 为了不损失空间的分辨率和有用的特征,采用局部邻居聚合的方法来增加感受野,然后合并特征
-
使用核心集构建内存库

流程解释:
-
M是我们需要的特征集,整个特征集不能太大(放在内存里面的),尽可能小的coreset能代表绝大多数的数据特征
-
遍历所有的图像,获得经过ResNet提取后的特征,还是太多,得优化
-
l是设定的coreset的特征子集个数,是个超参数
-
关键:如果选才能满足1中的要求? 就是,每次选一个coresset(Mc)中的点,在M中找一个最近又最远(贪心策略)的点,抽出来
-
解释一下什么是最近又最远:在最近的范围内找到最远的点,也就是在局部找到一个最远的点,即最优解。如果不这样,搜索计算量巨大NP难的问题
- 用PatchCore进行异常检测
测试集的数据进来,进行最近邻搜索

- 每个query进来,首先找最近距离最近的领域质心(蓝色标记,非数据点)

- 找到距离query最近的质心后,锁定该领域
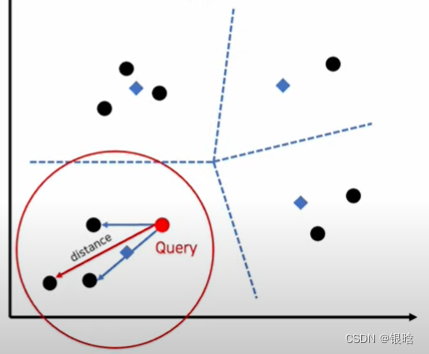
- 然后在该领域内计算距离最远的数据点,用该距离计算anomaly score,判断是否异常,得到结果
3、PaDiM和PatchCore对比
- PatchCore与PaDiM对比: patchcore 使用高效的patch-feature memory bank,在测试时所有patch都可以访问该内存库。 PaDiM 是针对每个 patch 的马氏距离度量。 相比之下, PatchCore对图像对齐的依赖性降低。
- 特征提取:特征表示为何不选择网络特征层次的最后一级:(1)会丢失更多的局部正常样本信息;(2)深层特征具有更强的语义信息,偏向于分类任务。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 非小米电脑安装小米电脑管家
- ssm基于SSM的个人事务管理系统的设计和实现论文
- WebSocket与JavaScript:实现实时获取位置
- Kafka Avro序列化之三:使用Schema Register实现
- 转换海盗王lua脚本ICU多语言的golang代码
- 异步非阻塞事件驱动架构的具体流程解析
- Go 语言为什么不支持并发读写 map
- Mybatis 和 Mybatis-Plus时间范围查询,亲测有效
- 从濒临破产到玩具行业天花板,乐高怎么做到的?
- 速盾cdn:高防cdn防ddos攻击