Python 使用 openpyxl 读取表格
发布时间:2023年12月17日
当前环境:Win10 x64 + MS office 2016 + Python3.7 +?openpyxl=3.0.9
1 表格内容(Sheet1 和 Sheet2)

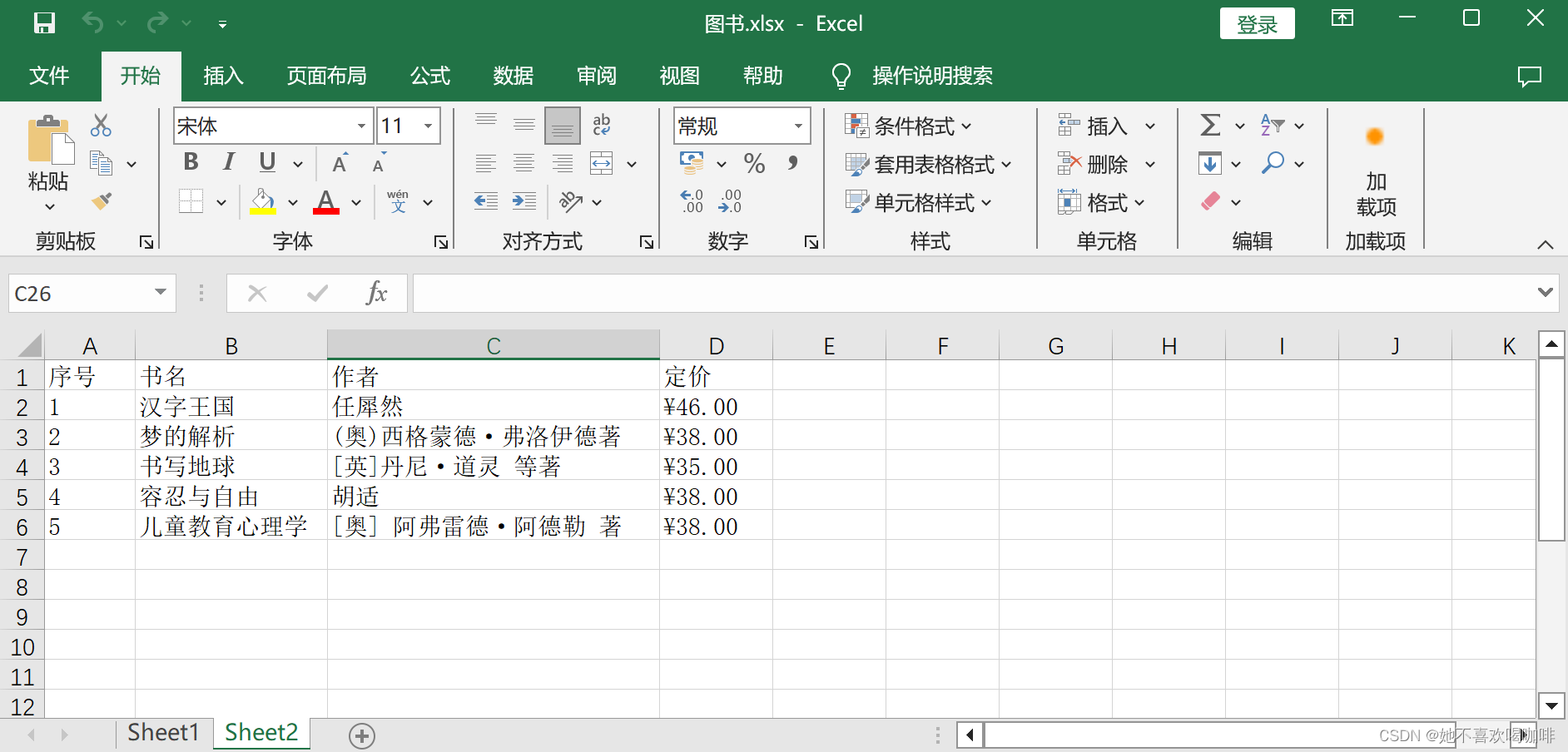
2 读取表格数据示例
from openpyxl import load_workbook
workbook = load_workbook(filename = r'图书.xlsx')
# 获取工作簿的所有工作表 ,返回列表类型
print(type(workbook.sheetnames),workbook.sheetnames)
'''
运行结果:
<class 'list'> ['Sheet1', 'Sheet2']
'''
# 通过索引获取表格,一个文件里可能有多个sheet
print(type(workbook.worksheets),workbook.worksheets)
'''
运行结果:
<class 'list'> [<Worksheet "Sheet1">, <Worksheet "Sheet2">]
'''
sheet = workbook.worksheets[0]
print(type(sheet.title),sheet.title)
'''
<class 'str'> Sheet1
'''
for sheet in workbook.sheetnames:
print(type(sheet.title),sheet.title)
'''
<class 'builtin_function_or_method'> <built-in method title of str object at 0x041126C0>
<class 'builtin_function_or_method'> <built-in method title of str object at 0x04112760>
'''
# 循环得到所有工作表
for sheet in workbook:
print(type(sheet.title),sheet.title)
'''
<class 'str'> Sheet1
<class 'str'> Sheet2
'''
# 获取表格 [active 当前活动的表格]
sheet = workbook.active
print(type(sheet),sheet,type(sheet.title),sheet.title)
'''
<class 'openpyxl.worksheet.worksheet.Worksheet'> <Worksheet "Sheet1"> <class 'str'> Sheet1
'''
# 获取表格 [通过名称 ]
sheet = workbook["Sheet2"]
print(type(sheet),sheet,type(sheet.title),sheet.title)
'''
<class 'openpyxl.worksheet.worksheet.Worksheet'> <Worksheet "Sheet2"> <class 'str'> Sheet2
'''
# 获取表格 [通过名称 ]
sheet = workbook[workbook.sheetnames[1]]
print(type(sheet),sheet,type(sheet.title),sheet.title)
'''
<class 'openpyxl.worksheet.worksheet.Worksheet'> <Worksheet "Sheet2"> <class 'str'> Sheet2
'''
# 获取表格 通过工作表名称
# sheet = workbook.get_sheet_by_name("Sheet1")
# print(type(sheet),sheet,type(sheet.title),sheet.title)
'''
运行结果:
<class 'openpyxl.worksheet.worksheet.Worksheet'> <Worksheet "Sheet1">
'''
# 获取表格尺寸大小 输出值为左上到右下的单元格名称
print(sheet.dimensions)
'''
运行结果:
A1:D6
'''
# 获取表格中某个单元格中的数据(示例:获取A1格子的数据)
# 方式一:
cell = sheet["A1"]
value = cell.value
print(type(value),value)
'''
<class 'str'> 序号
'''
# 方式二:
cell = sheet.cell(row = 1, column = 1)
value = cell.value
print(type(value),value)
'''
<class 'str'> 序号
'''
# 获取表格中某个单元格所在的行数、列数、坐标
cell = sheet["B2"]
value = cell.value
row = cell.row
column = cell.column
coordinate = cell.coordinate
print(type(value),value)
print(type(row),row)
print(type(column),column)
print(type(coordinate),coordinate)
'''
运行结果:
<class 'str'> 汉字王国
<class 'int'> 2
<class 'int'> 2
<class 'str'> B2
'''
# 获取表格中一系列格子
# 第一种方式:使用 sheet[]
cell = sheet["A1:C2"]
print(type(cell),cell)
'''
<class 'tuple'> ((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>), (<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>))'''
for i in cell:
print(type(i),i)
for j in i:
value = j.value
print(type(j),j,type(value),j.value)
'''
运行结果:
<class 'tuple'> (<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>)
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.A1> <class 'str'> 序号
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.B1> <class 'str'> 书名
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.C1> <class 'str'> 作者
<class 'tuple'> (<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>)
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.A2> <class 'int'> 1
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.B2> <class 'str'> 汉字王国
<class 'openpyxl.cell.cell.Cell'> <Cell 'Sheet2'.C2> <class 'str'> 任犀然
'''
# 获取 A 列的数据
cell = sheet["A"]
print(cell)
'''
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
'''
# 获取 A B C 三列的数据
cell = sheet["A:C"]
print(cell)
'''
((<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>), (<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>), (<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>))
'''
# 获取第 5 行的数据
cell = sheet[5]
print(cell)
'''
(<Cell 'Sheet2'.A5>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.D5>)
'''
# 第二种方式:使用
# 按行获取值,先行后列
for row in sheet.iter_rows(min_row=2, max_row=5, min_col=1, max_col=2):
for cell in row:
print(cell.value)
'''
1
汉字王国
2
梦的解析
3
书写地球
4
容忍与自由
'''
for col in sheet.iter_cols(min_row=2, max_row=5, min_col=1, max_col=2):
for cell in col:
print(cell.value)
'''
1
2
3
4
汉字王国
梦的解析
书写地球
容忍与自由
'''
# 获取所有行
for i in sheet.rows:
print(i)
'''
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.B1>, <Cell 'Sheet2'.C1>, <Cell 'Sheet2'.D1>)
(<Cell 'Sheet2'.A2>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.D2>)
(<Cell 'Sheet2'.A3>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.D3>)
(<Cell 'Sheet2'.A4>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.D4>)
(<Cell 'Sheet2'.A5>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.D5>)
(<Cell 'Sheet2'.A6>, <Cell 'Sheet2'.B6>, <Cell 'Sheet2'.C6>, <Cell 'Sheet2'.D6>)
'''
for i in sheet.columns:
print(i)
'''
(<Cell 'Sheet2'.A1>, <Cell 'Sheet2'.A2>, <Cell 'Sheet2'.A3>, <Cell 'Sheet2'.A4>, <Cell 'Sheet2'.A5>, <Cell 'Sheet2'.A6>)
(<Cell 'Sheet2'.B1>, <Cell 'Sheet2'.B2>, <Cell 'Sheet2'.B3>, <Cell 'Sheet2'.B4>, <Cell 'Sheet2'.B5>, <Cell 'Sheet2'.B6>)
(<Cell 'Sheet2'.C1>, <Cell 'Sheet2'.C2>, <Cell 'Sheet2'.C3>, <Cell 'Sheet2'.C4>, <Cell 'Sheet2'.C5>, <Cell 'Sheet2'.C6>)
(<Cell 'Sheet2'.D1>, <Cell 'Sheet2'.D2>, <Cell 'Sheet2'.D3>, <Cell 'Sheet2'.D4>, <Cell 'Sheet2'.D5>, <Cell 'Sheet2'.D6>)
'''
# 获取最大行、最大列
row = sheet.max_row
column = sheet.max_column
print(type(row),row)
print(type(column),column)
'''
<class 'int'> 6
<class 'int'> 4
'''
'''
# 说明:
load_workbook 函数:
load_workbook 除了参数 filename外为还有一些有用的参数:
read_only: 是否为只读模式,对于超大型文件,要提升效率有帮助
keep_vba :是否保留 vba 代码,即打开 Excel 文件时,开启并保留宏
guess_types:是否做在读取单元格数据类型时,做类型判断
data_only:? ? ?是否将公式转换为结果,即包含公式的单元格,是否显示最近的计算结果
keep_links:???是否保留外部链接
'''
'''
# 参考
https://www.jianshu.com/p/537ae962f3a0 (文章里有个更新的例子,感觉不做)
https://zhuanlan.zhihu.com/p/351998173
https://blog.csdn.net/fanlei_lianjia/article/details/78225857
https://blog.csdn.net/PMPWDF/article/details/101420576
https://blog.csdn.net/wmz19960227/article/details/117994478
https://www.jianshu.com/p/9a3639225a77
'''
文章来源:https://blog.csdn.net/yudiandian2014/article/details/134993482
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- RM3100 stm32驱动(硬件i2c)
- 【算法与数据结构】279、LeetCode完全平方数
- Vue中使用debugger在浏览器中不起作用解决方案
- 索引与优化原理(上)
- PMP+NPDP,实现越位思考!(项目、产品管理)
- 智能优化算法应用:基于黑寡妇算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- 详解gorm中DB对象的clone属性
- The Sandbox 线下联动|「友邦嘉年华」地主专享门票免费放送
- Goole上架年度总结(2023年)
- 洛谷P1168 中位数