实时嵌入式Linux设备基准测试快速入门4测试和测量
本章将介绍主要测试方案及其具体配置和结果。在介绍实际测量结果之前,将尽可能总结被测设备的特性。最后,将对结果进行分析,并概述由于高速缓存一致性问题造成的延迟方面的主要瓶颈,提出减少延迟的解决方案,并解释用于发现和缓解问题的方法。
设备
用于智能设备的 SABRE 板
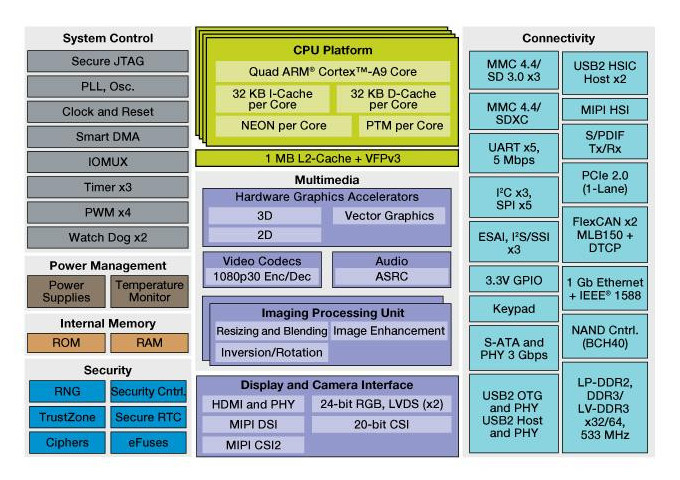
实际参与所有测试和分析的主要设备是用于智能设备的恩智浦快速工程智能应用蓝图(SABRE)板:它是基于i.MX6四核处理器的开发板,具有低功耗特性、多媒体和图形功能的多核处理器。其主要特点:
- 四核 ARM Cortex-A9 (2 CPU)
- 多级内存系统
- 动态电压和频率缩放
- 强大的图形加速
- 接口灵活性
- 整个设备的集成电源管理
- 先进的硬件支持的安全性
SABRE板提供了低成本开发平台,包括i.MX6处理器的所有主要功能以及高速接口和存储器。它的硬件设计文件和许多附件板都很容易获得,这些附件板可与SABRE板配合使用,提供额外的功能,如多点触摸显示和Wi-Fi连接。
此外,作为恩智浦(NXP)社区支持的SABRE板,还提供针对Android和Linux的优化BSP以及优化的视频、语音和音频编解码器。具体来说,还提供了与Yocto项目一起使用的BSP层,可用于获得工作和优化的 Linux 发行版。
SABRE板为智能设备提供的主要功能包括
- i.MX6 QuadPlus 1 GHz 应用处理器
- 1 GB DDR3,533 MHz
- 8 GB eMMC NAND
- 两个 SD 卡插槽
- 串行高级技术附件 (SATA) 22 针连接器
- HDMI 连接器
- 两个低压差分信号 (LVDS) 连接器
- 液晶显示器 (LCD) 扩展端口连接器
- 串行摄像头连接器
- 两个 3.5 毫米音频端口(立体声 HP 和麦克风)
- USB On-The-Go (OTG) 连接器
- 通过 USB uAB 设备连接器调试输出
- 千兆以太网连接器
- 联合测试行动组 (JTAG Joint Test Action Group) 10 针连接器
- mPCIe 连接器
- 3 轴加速计
- 数字罗盘
商业设备
测试过程中也使用了商业设备。虽然不会指明供应商名称,但下文将介绍主要设备特性,从现在开始,参与基准测试的这两款设备将被称为 SBC-1 和 SBC-2。
SBC-1
i.MX6 QuadPlus 800 MHz 应用处理器
2 GB DDR3
8 GB eMMC NAND
SD 卡插槽
2 个 USB 接口
触摸屏
通过通用异步收发器(UART)进行调试
3 个千兆以太网连接器
SBC-2
i.MX6 QuadPlus 1 GHz 应用处理器
1 GB DDR3
8 GB eMMC NAND
SD 卡插槽
1 个 USB 接口
触摸屏
通过 UART 调试
2 个千兆以太网接口
测试方案和结果
测量Linux实时系统的性能时,可以采用不同的方法。最直接的方法是在系统运行将在最终产品中执行的实际应用程序时测量实时延迟。当然,采用这种方法可以获得最可靠的结果,反映真实系统的运行情况。
然而,由于各种原因,并非总能遵循这种方法。事实上,可能会出现这样的情况:没有最终的应用程序,或者最终的应用程序无法发布用于测试。
当最终应用程序无法用于测试时,可使用合成基准来估计系统在不同负载情况下的表现。按照这种方法,要测试系统的实时性能,最重要的步骤之一是定义基准结构,确定正确的 测试场景。
事实上,在没有实际最终应用程序的情况下,确定由设备执行的正确基准很重要,因为在基准测试套件方面有许多选项。有时,如果要制作验收测试套件,主要目的是评估不同供应商提供的不同硬件平台,那么创建易于重现的测试用例是非常有用的,这样当某些功能与预期不符时,供应商就可以执行相同的测试。
在这项工作中,可重复性是开发各种基准的关键概念。因此,所有使用的测试程序都选择了开放源代码,以便轻松重复所有测试用例。
本节将详细介绍主要的测试场景、使用的软件及其配置。然后,将对获得的结果进行介绍和分析。
值得注意的是,为了简单起见,将只报告最有意义的结果,但这并不意味着信息的丢失,因为所制作的汇总图包含了所有有用的数据。
实时任务
围绕主要目标(即测试实时系统性能),为有效测试设备,需要一个能够测量调度延迟的实时任务。Linux 实时系统中最常用的调度延迟测量程序是Cyclictest。因此,在测试执行期间,所有情况下都使用 Cyclictest模拟了实时进程,除了模拟实时进程外,Cyclictest还帮助收集了本章将要报告的所有延迟信息。
Cyclictest提供了许多可用于创建不同测试场景的选项,但在几乎所有测试案例中,其选项都保持不变。
具体来说,Cyclictest 的执行命令如下
cyclictest -S -l "loops" -m -p 90 -i "interval" -q -h400 > output
- 1
Cyclictest 选项
-S选项
在所有线程中保持指定的优先级相同。
设置线程数等于可用 CPU 数。
将每个线程分配给特定处理器(亲和性)。
使用 clock_nanosleep 代替 POSIX 间隔计时器。
-l 要执行的循环次数。
-m 锁定当前和未来的内存分配,防止内存被分页到交换区。
p 90 设置线程优先级。
-i "时间间隔 "设置线程的基本时间间隔,单位为微秒。
-q 安静运行测试,退出时打印摘要。
-h 400 将延迟直方图输出到 stdout,400是以微秒为单位的最大跟踪时间。
通常,当实时应用程序必须在目标硬件上运行时,它的特点是有明确的周期。但是,如果我们有兴趣执行未完全定性的合成基准,比如本例中的情况,那么了解实时应用程序在不同时间段内的系统运行情况可能会很有趣。
因此,所有执行的测试都重复了多次,每次都对实时任务施加了不同的周期。更详细地说,所有测试都重复执行了三次,将实时任务设置为以下周期:
? 100μs
? 1ms
? 10ms
当然,实时任务周期可以通过 Cyclictest -i "interval"选项轻松设置。
选项可以轻松设置实时任务周期,因此只需运行三次带有不同"interval"值的命令即可。
CPU 几乎处于空闲状态
第一种测试情形,顾名思义,其特点是只运行实时任务,而没有任何其他特定的CPU负载。事实上,在没有任何负载的情况下运行 Cyclictest 只能提供延迟的下限。
不过,运行Cyclictest可以帮助了解系统是否运行正常,系统设置是否正确。事实上,正如下面的测试案例所示,如果被测系统设置不当,即使 CPU 处于空闲状态,也会出现明显的调度延迟。
现代Vanilla Linux内核提供了三种主要的抢占选项,以改善系统延迟:
config_preempt_none: 无强制抢占(通常用于服务器)
CONFIG_PREEMPT_VOLUNTARY:自愿内核抢占(通常用于台式机)
config_preempt: 可抢占的内核(通常用于低延迟桌面)
除了标准Vanilla内核提供的功能外,如果系统需要更多的实时功能,最常用的改进Linux实时功能的策略是在内核源代码中打上PREEMPT_RT的补丁集,使其更具有抢占式功能。因此,使用PREEMPT_RT补丁的内核会在内核抢占选项中增加一个额外选项,即PREEMPT_RT_FULL或完全抢占内核(RT Fully Preemptible Kernel)。
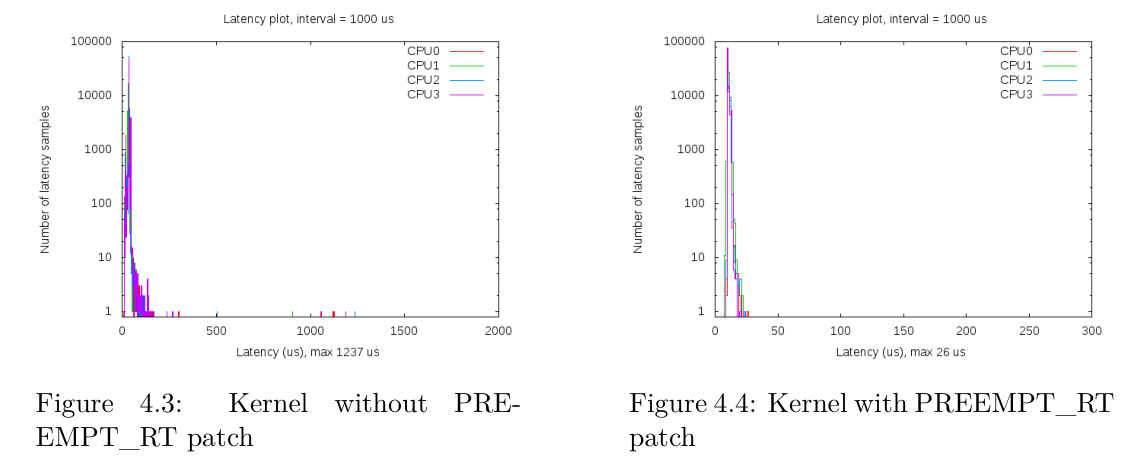
为了了解配置了PREEMPT_RT_FULL的内核所带来的主要改进,我们编译了Sabre主板的基本内核版本,并收集了在该内核上运行的 Cyclictest 的结果。
从下图可以看出,在无PREEMPT_RT_FULL内核上运行的Cyclictest的最大延迟时间为1.2ms,而在完全抢占式内核(RT)上运行的 Cyclictest 的最大延迟时间仅为 26μs。
测试中使用的不带PREEMPT_RT_FULL选项的内核已被配置为CONFIG_PREEMPT,即使用标准Linux内核提供的最抢占式选项。
在 4.2 中报告了使用的两个内核版本,第一个版本指的是启用了CONFIG_PREEMPT的标准内核,而后者是使用 PREEMPT_RT 和激活了完全抢占式内核 (RT) 选项的内核。
root@imx6qdlsabresd :~# uname -a
Linux imx6qdlsabresd 4.1.44 - fslc+g6c1ad49 #1 SMP PREEMPT Thu Jul
19 15:16:14 UTC 2018 armv7l GNU/Linux
root@imx6qdlsabresd :~# uname -a
Linux imx6qdlsabresd 4.1.38 - rt45 -fslc+gee67fc7 #1 SMP PREEMPT RT
Mon Mar 19 22:27:10 CET 2018 armv7l GNU/Linux
回到实际的内核配置,即启用PREEMPT_RT_FULL的内核,也就是提供最佳实时功能的内核,其他被测设备也在使用该内核。
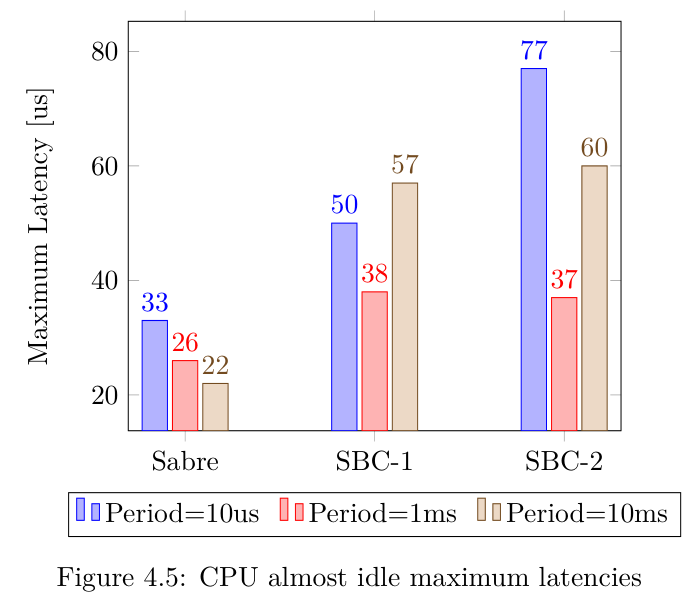
下图显示了所有内核的最大延迟值。该条形图是根据上图所示的延迟图绘制的,并考虑了所有内核中的最大延迟值。事实上,在处理实时系统时,最大值通常能提供更多信息,即系统是否会错过最后期限。
在第一种情况下Sabre电路板的性能略高于其他设备。造成这种性能差异的原因有很多,例如:硬件配置不同、内核版本不同等等。最后,考虑到不同的线程间隔,即实时时间段(100μs、1ms、10ms 和100ms),Sabre主板显然在线程间隔增加时取得了更好的延迟结果。最后一点可能是合理的,因为当线程间隔增加时,系统的压力应该较小。
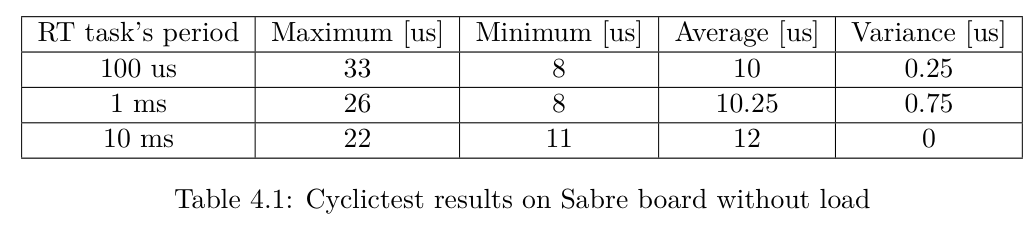
下表提供了有关平均延迟、最小延迟和方差的其他信息,为简单起见,这些信息仅指 Sabre板,因为它代表了主要的被测设备。
IPC压力
测量空闲系统的实时延迟用处不大,因为CPU只需处理实时(RT)应用程序。因此,在第二种情况下对CPU施加压力,以获得更真实的结果。
正如已经分析过的,rt-tests 套件也提供了适用于这种情况的工具,特别是Hackbench实用程序可用作CPU 压力源来模拟某种系统负载。当然,这种情况遵循了合成基准的理念,创建了更真实的情况,即使用Hackbench来模拟系统负载。基本上,该测试用例使用实时应用程序来测量延迟,而Hackbench则对内核施加压力。更详细地说,测试条件是通过执行以下命令创建的:
$ hackbench -P -g 15 -f 25 -l 200 -s 512 \&
$ cyclictest -S -l "loops" -m -p 90 -i "interval" -q -h400 > output
- 1
- 2
? - P 表示使用进程作为发送方和接收方。
? -g 15 创建 15 组发送方/接收方。
? -f 25 规定每个发送方和接收方应使用25个文件描述符。
? -l 200 规定每个发送方/接收方必须发送200条信息。
? -s 512 设置每条信息的发送数据量为512字节。
总之,使用Hackbench和所述选项,Linux内核必须管理15组进程,这些进程使用25x2=50个文件描述符发送 200条信息,每条信息512字节。当然,这种测试情况会导致CPU利用率很高,使系统压力很大。下图显示了所有内核和不同线程周期的最大延迟。
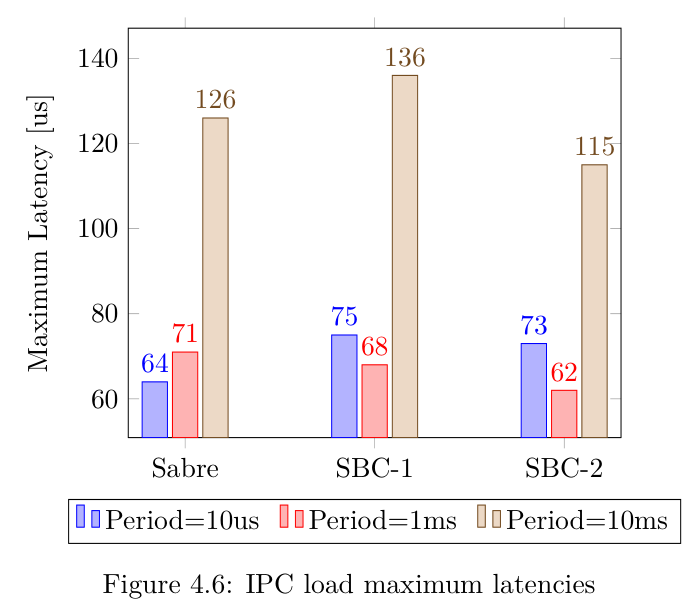
同样在这种情况下,平均而言,Sabre板的性能略高于其他单板计算机。当然,第二个测试案例更加真实,因为使用 Hackbench 模拟了系统负载并达到了较高的 CPU 利用率。
分析所获得的结果,在这种情况下发生了一些非常"奇怪"的事情,事实上,间隔时间较短的线程比间隔时间较长的线程表现更好,也就是说,唤醒频率较低的线程获得了更高的延迟。由于这种"奇怪"的在这种情况下,看看下图中 Sabre 板的延迟图可能会很有趣。
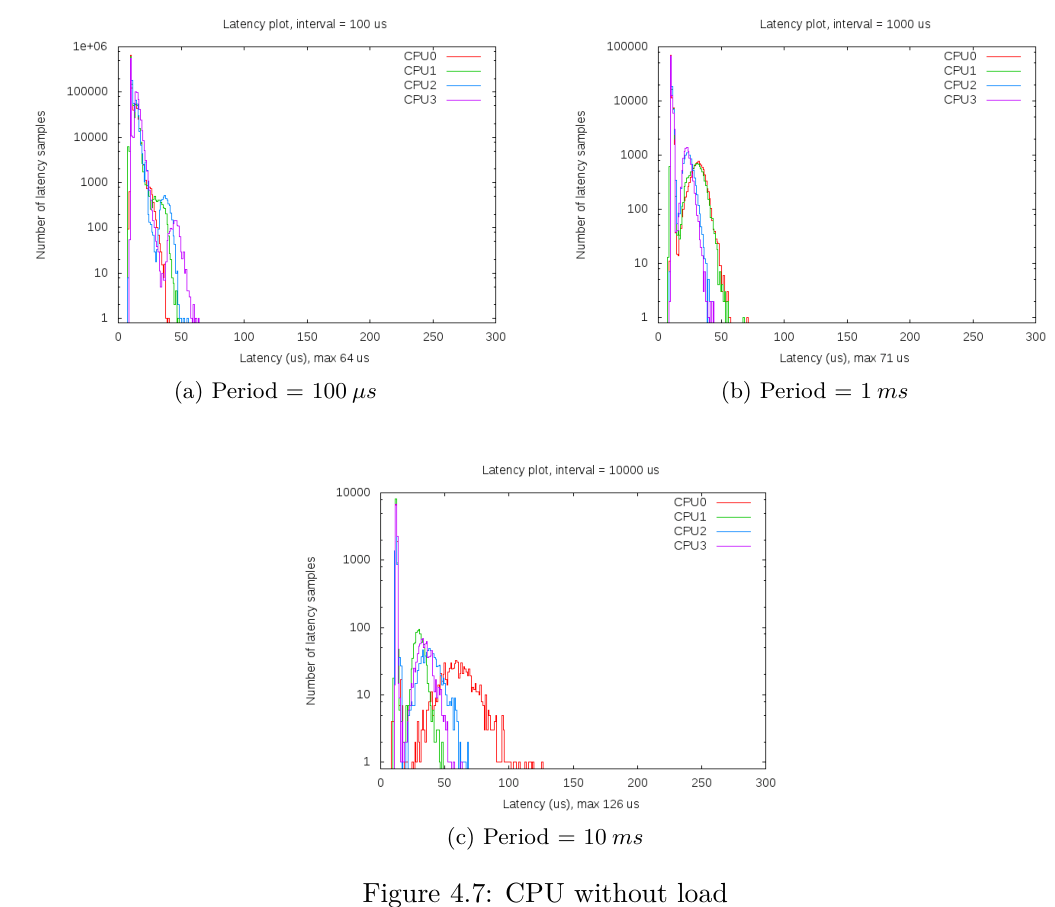
观察图4.7b和图4.7c之间的差异,在最大延迟和可变性方面,所获得的行为并不容易解释。事实上,乍一看,当线程的时间间隔较大时,我们可能会期望获得较低的延迟,也就是说,由于线程的时间间隔较大,CPU 的压力较小,其性能应该更好。
然而,得到的结果与我们的预期完全相反,经过一番调查和分析,我们找到了这种"奇怪"行为的原因,实际动机将在第4.3.1节中解释。目前,我们认为造成这种行为的可能原因是缓存丢失问题。事实上,如果实时线程的执行频率较低,而其他进程(Hackbench或内核本身)被允许在中间执行,那么当实时线程应该被执行时,可能会出现缓存未命中的情况,因为中间执行的其他进程已经替换了一些缓存行。
参考资料
软件测试精品书籍文档下载持续更新 https://github.com/china-testing/python-testing-examples 请点赞,谢谢!
本文涉及的python测试开发库 谢谢点赞! https://github.com/china-
testing/python_cn_resouce
python精品书籍下载 https://github.com/china-
testing/python_cn_resouce/blob/main/python_good_books.md
Linux精品书籍下载 https://www.cnblogs.com/testing-/p/17438558.html
网络压力
由于现在几乎所有设备都有网络连接,因此研究一下系统在网络负载下的表现可能会很有意义。
当然,系统需要管理网络连接的情况多种多样,为此,我们定义并分析了不同的测试用例:具体来说,我们定义了两个主要基准,每个基准都概括了不同的情况,并将在下文中介绍。
Ping
第一个概述的场景涉及网络连接,使用著名的Ping网络实用工具作为背景系统负载。
Ping是一种软件工具,广泛用于测试互联网协议(IP)网络中主机的可达性。Ping使用互联网控制消息协议(ICMP)回波请求来检查另一台目标主机的可达性。
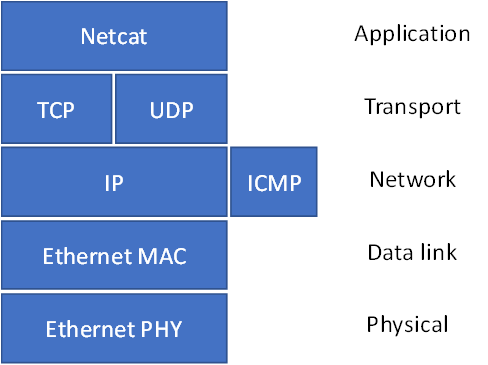
下图显示了国际标准化组织开放系统互连 (ISO/OSI) 模型,从中不难看出,ICMP 可被视为使用 IP 和以太网帧的第三级协议,具体来说,它具有以下特性:
- 不是传输协议。
- 不用于在设备间交换数据。
- 与传输协议相比,它产生的内核开销较低。
- 与使用原始IP数据包几乎相同。
总之,Ping 的特性在某种程度上可以用来模拟原始网络流量,如处理Ethercat、Modbus等网络协议时产生的网络流量。
执行以下命令创建实际网络负载:
$ ping -l 65500
? - 是设备地址。
? -l 65500 设置 ICMP 报文的最大字节数。
Ping命令与Cyclictest一起执行,以测量实时延迟,下图报告了所有内核的最大延迟值。分析结果表明,网络负载对实时性能影响不大,SBC-2设备的最大延迟时间约为70us。SBC-2的性能比其他设备差,但仍然获得了可以接受的延迟值。
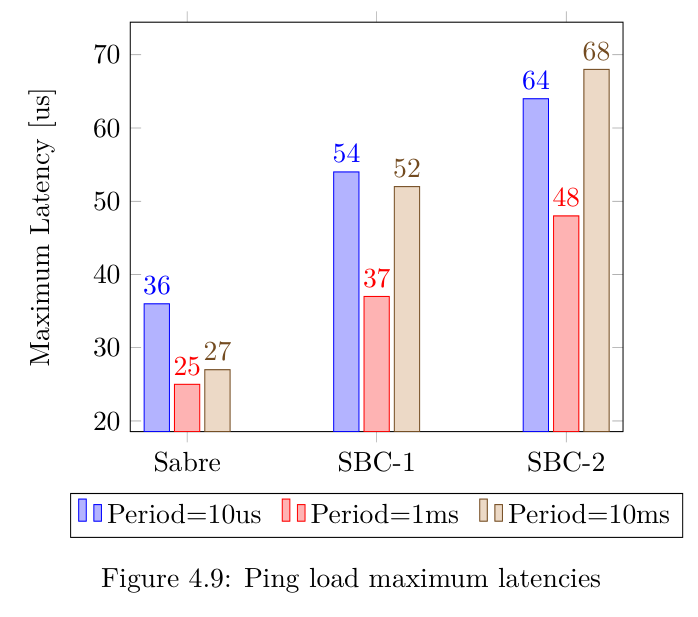
Netcat和磁盘操作
对网络能力的要求越来越高,为了模拟这种系统负载,使用了实用程序Netcat。它可以使用TCP或用户数据报协议 (UDP) 通过网络连接进行读写,Netcat 工具还可用于传输要保存在存储设备上的文件。
利用这一功能还进行了其他一些测试,以了解系统在处理网络负载和磁盘存储操作带来的额外压力时的性能。更详细地说,嵌入式设备被要求每秒接收并存储1Mb的数据,但在这种情况下,系统并不被要求立即存储接收到的数据,而是让Linux内核缓存即将到来的数据,并自动管理数据存储过程。
下图显示了所有内核的最大延迟时间,从中可以看出Sabre电路板的性能优于其他设备,在这种情况下,SBC-1的延迟时间最差。
此外,从图4.9和图4.10之间的差异可以看出,SBC-2设备的结果比简单Ping负载情况下的结果要好,但这并不容易解释。当然,许多参数都会影响这些结果,但由于延迟时间没有超过100μs,因此无需进行额外分析即可接受这些结果。

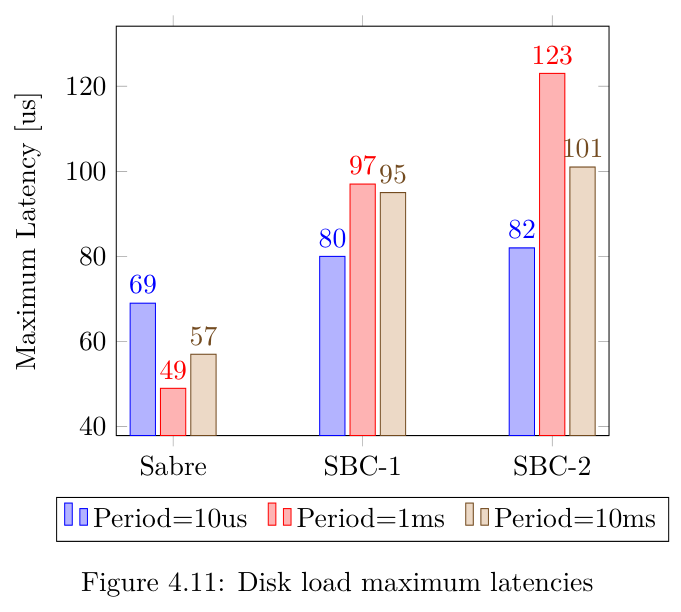
4.2.5 磁盘压力
尽管Netcat测试已经写入了磁盘,但本测试案例的主要想法是对存储能力进行高强度的压力测试。
事实上,在对Linux内核如何管理存储设备进行分析后,本节创建的测试通过写入1Mb的数据块来执行,并提交每个数据块以确保其确实写入磁盘设备。
分析得到的结果:通常情况下,Sabre主板的结果最好,最大延迟约为70us,而SBC-2的延迟值最差,最大延迟为123us,最后,SBC-1没有超过100 us的调度延迟,在前面提到的两种设备中处于中间位置。
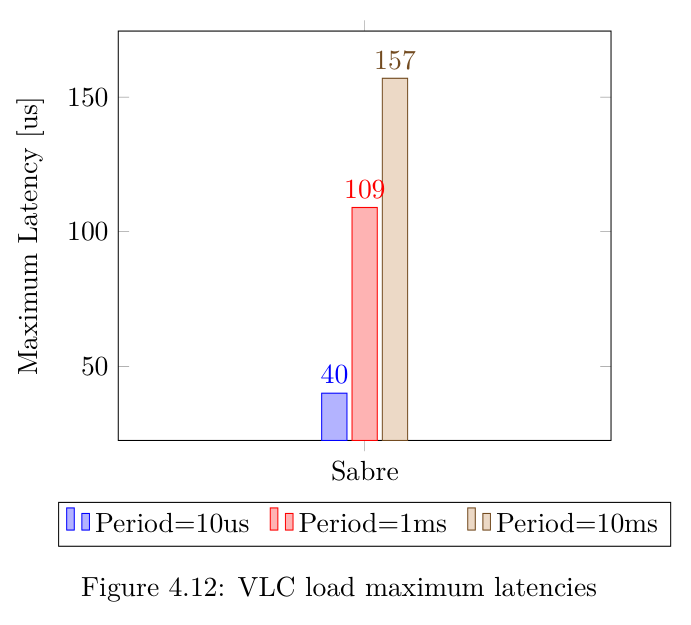
4.2.6 VLC视频
最后一个测试场景试图涵盖设备必须与实时应用程序一起管理视频流的使用情况。使用著名的VLC媒体播放器播放分辨率为720x480的MPEG文件,VLC与Cyclictest 模拟的实时进程同时执行。
该测试场景仅在Sabre板上进行了测试,下图显示了最大延迟:可以看出,当实时线程的周期变大时,延迟会增加,就像 Hackbench 在系统负载时发生的情况一样。
4.3 测试分析
在看过各种测试场景及其结果后,可以说几乎在所有情况下,所分析的系统都能保证延迟不超过100us。然而,在某些情况下,系统会出现更大的延迟和"奇怪"的延迟。特别是当实时应用程序的周期较大时,会出现超过 100us 的延迟。
乍一看,这种情况不容易解释,因为当实时任务的周期较大时,系统的压力应该较小。然而,当系统需要处理其他任务时,才会出现较高的延迟时间,也就是说,当系统只需管理实时应用程序而无需处理其他任务时,就不会出现这种 "奇怪 "的行为。
正如预期的那样,为了更好地了解发生了什么以及为什么会出现这些 "奇怪 "的行为,我们使用了第 3.3 节中描述的剖析方法进行了额外的调查。下文将介绍这些进一步的分析,然后将介绍这些问题的一些解决方案,并将获得的新结果与 "奇怪 "的旧结果进行比较。
4.3.1 缓存一致性问题
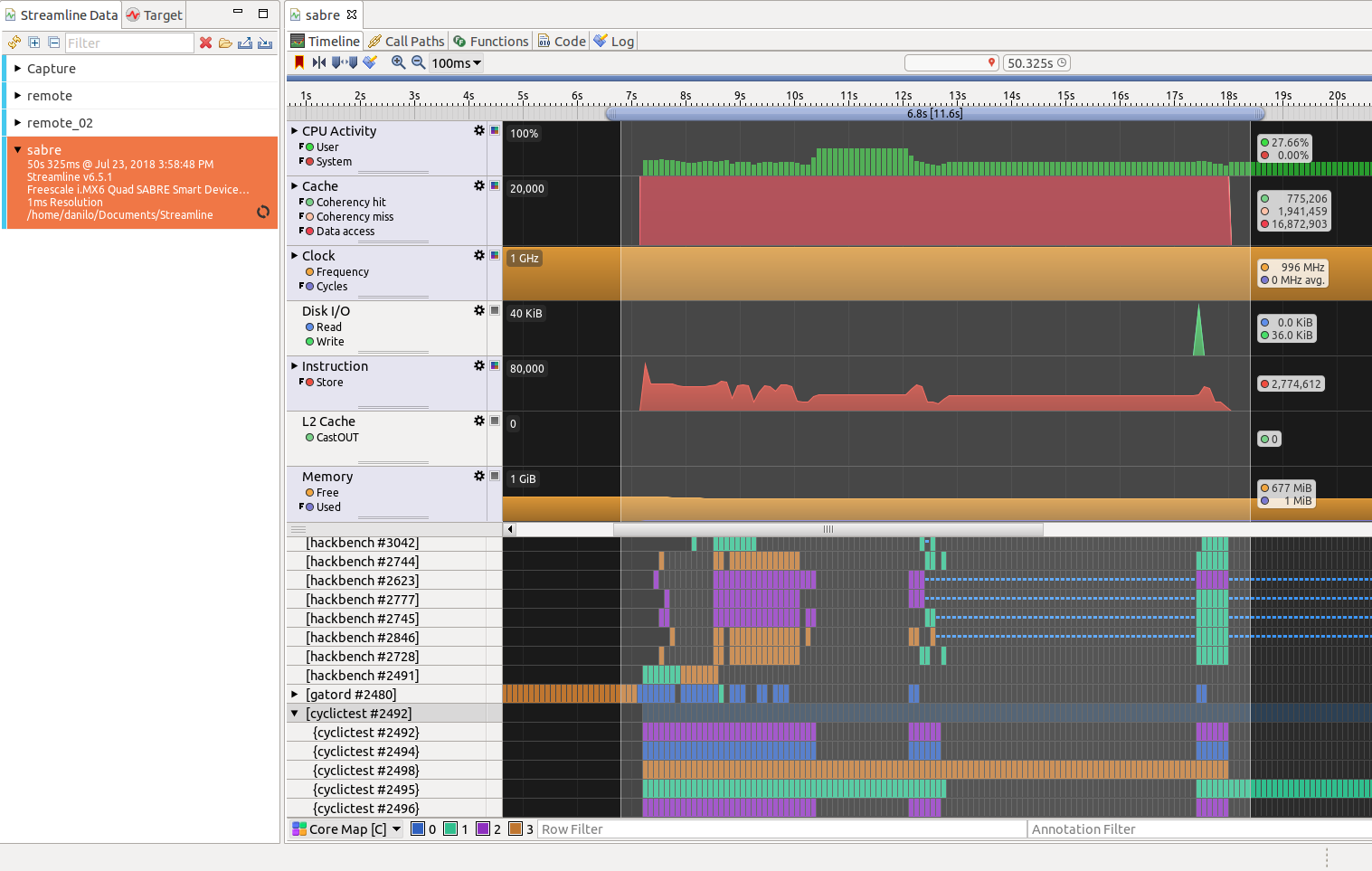
为了研究线程周期较长时出现的问题,之前的大多数测试都是在 DS-5 Streamline后台运行时重新执行的。
通过这种方式,在接受剖析工具带来的一些开销的情况下,可以收集到所有需要的信息,从而更好地了解发生了什么。基本上,在Streamline收集剖析信息时,测试已经运行了很多次。
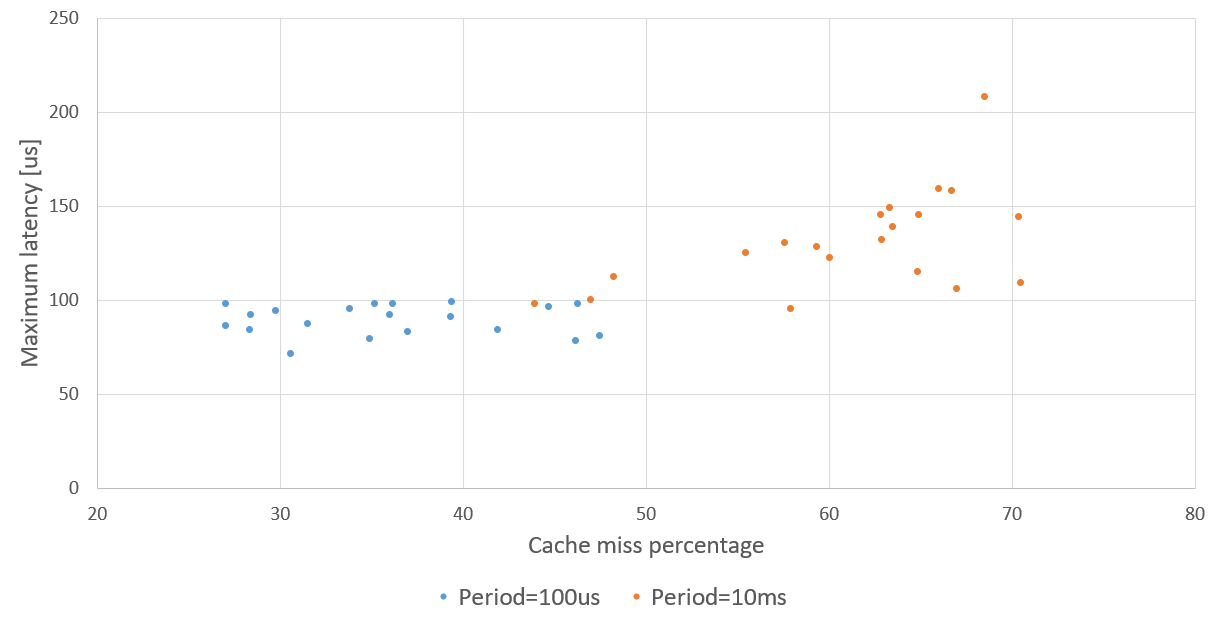
下图可以看到Streamline,从中可以提取与每个进程的缓存缺失相关的信息(见右上角)。多次运行测试并收集与高速缓存未命中和命中相关的信息,同时考虑到高速缓存的访问次数与实时时间段无关,因此可以得到图 4.14 所示的图形:它显示了延迟值与高速缓存未命中百分比的某种 关联。
总之,从图4.14中可以看出,当Cyclictest运行的周期越长,缓存丢失的百分比就越高,延迟也就越长。因此,当允许其他进程在两次 Cyclictest 执行中间运行时,缓存丢失的百分比会增加,延迟也会增大。
4.3.2 可能的解决方案
在前面的测试中,我们发现当实时线程的运行时间较长时,缓存丢失的比例会增加。
尽管所有测试都使用了Cyclictest,使每个线程始终在同一个内核上运行,以避免缓存出现更多问题,但还是出现了这种情况。
不过,即使Cyclictest的线程始终运行在同一个内核上,其他进程和Linux内核本身也可以在每个内核上不一致地运行。
最后一点可以用来改善延迟,方法是限制其他进程和Linux本身只在某些内核上运行,而将其他一些内核空出来,供实时进程使用。
在Linux提供的众多自定义选项中,还可以设置每个进程在哪个内核中运行。在运行系统中,可以使用taskset命令设置进程的亲缘性,并指出任务的进程标识符(PID)和亲缘性掩码,即进程ID和该进程可以运行的内核。
因此,乍一看,我们可以尝试创建一些shell脚本,使用taskset将所有进程分配到给定数量的内核上。然而,在使用 Streamline 对系统进行剖析后发现,一些内核线程并不受 taskset 的影响。
因此,经过进一步调查,我们发现了一种限制整个Linux内核在给定内核数上运行的替代方法。具体来说,要限制整个Linux内核只在指定的内核上运行,可以使用isolcpus启动参数。后者是内核启动参数之一,可将某些内核与内核调度隔离开来,也就是说,将某些内核从Linux系统中解放出来是非常有用的。
因此,为了了解如何让某些内核不受Linux系统的影响,我们重新执行了第4.2.3节中的测试(报告延迟超过 100us 和 "奇怪 "行为的测试),只让两个内核执行实时任务。更详细地说,在 Sabre 板的 u-boot 命令行中设置了以下内核参数:
setenv bootargs '.... isolcpus =2,3'
- 1
指定的参数允许内核只在核心0和核心1上运行,将其他核心留给实时任务。
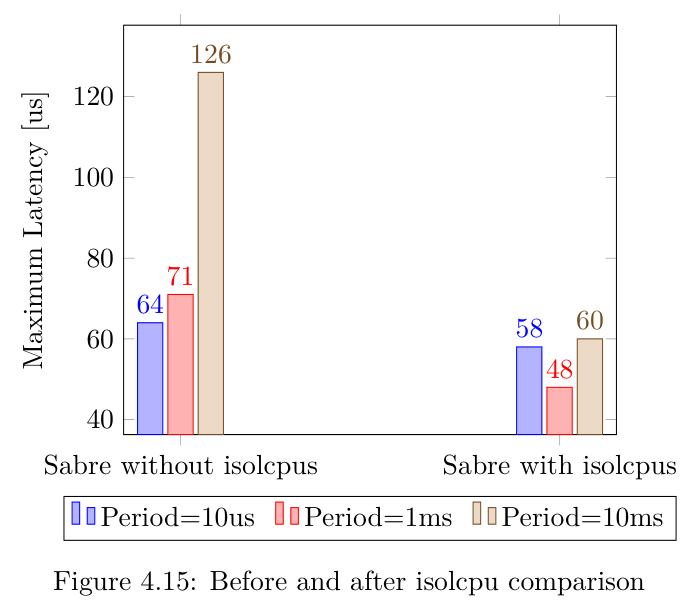
从图中可以看出,当Linux内核仅限于在内核0和内核1上运行时,获得的最大延迟值明显减少。事实上,涉及较大周期(1ms和10ms)实时任务的延迟也明显减少。
总结:
感谢每一个认真阅读我文章的人!!!
作为一位过来人也是希望大家少走一些弯路,如果你不想再体验一次学习时找不到资料,没人解答问题,坚持几天便放弃的感受的话,在这里我给大家分享一些自动化测试的学习资源,希望能给你前进的路上带来帮助。
-
文档获取方式: -
加入我的软件测试交流群:1007119548免费获取~(同行大佬一起学术交流,每晚都有大佬直播分享技术知识点)
这份文档,对于想从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!
以上均可以分享,只需要你搜索vx公众号:程序员雨果,即可免费领取
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- LeetCode刷题---字母异位词分组(哈希表)
- WEB前端人机交互导论实验-实训9 JavaScript
- transforms图像增强(二)
- 畅聊未来:低代码打造在线聊天系统
- Unity中URP下的半透明效果实现
- Unity3D代码混淆方案详解
- java并发编程十 原子累加器和Unsafe
- STM32中TIM定时器定时功能详解(适用基本,通用,高级定时器)
- 飞凌嵌入式T113-i开发板的调屏方法,就是这样简单
- 磁盘及文件系统(上)