【SAM系列】Segment Anything--prompt具体如何起作用
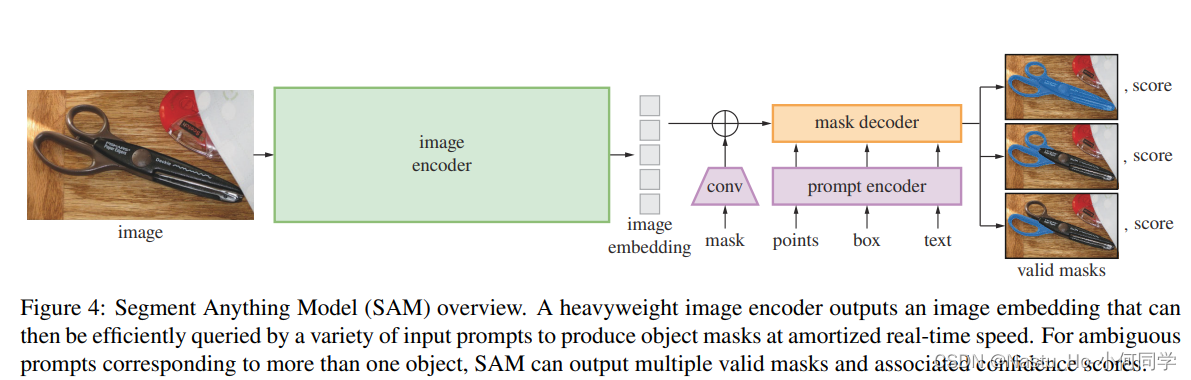
prompt具体如何起作用
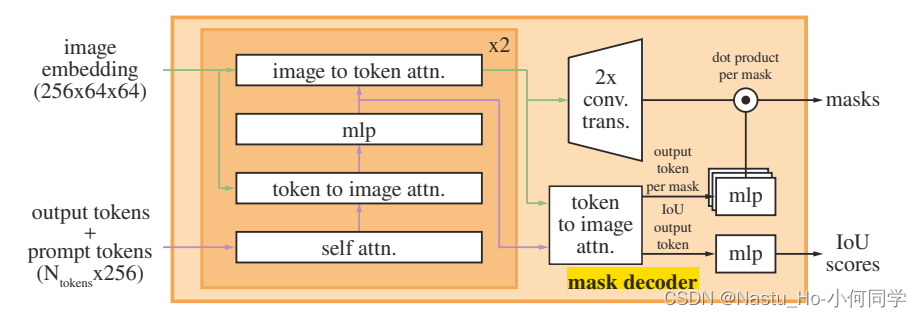
class TwoWayAttentionBlock(nn.Module):
def __init__(
self,
embedding_dim: int,
num_heads: int,
mlp_dim: int = 2048,
activation: Type[nn.Module] = nn.ReLU,
attention_downsample_rate: int = 2,
skip_first_layer_pe: bool = False,
) -> None:
"""
A transformer block with four layers: (1) self-attention of sparse
inputs, (2) cross attention of sparse inputs to dense inputs, (3) mlp
block on sparse inputs, and (4) cross attention of dense inputs to sparse
inputs.
Arguments:
embedding_dim (int): the channel dimension of the embeddings
num_heads (int): the number of heads in the attention layers
mlp_dim (int): the hidden dimension of the mlp block
activation (nn.Module): the activation of the mlp block
skip_first_layer_pe (bool): skip the PE on the first layer
"""
super().__init__()
self.self_attn = Attention(embedding_dim, num_heads)
self.norm1 = nn.LayerNorm(embedding_dim)
self.cross_attn_token_to_image = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.norm2 = nn.LayerNorm(embedding_dim)
self.mlp = MLPBlock(embedding_dim, mlp_dim, activation)
self.norm3 = nn.LayerNorm(embedding_dim)
self.norm4 = nn.LayerNorm(embedding_dim)
self.cross_attn_image_to_token = Attention(
embedding_dim, num_heads, downsample_rate=attention_downsample_rate
)
self.skip_first_layer_pe = skip_first_layer_pe
def forward(
self, queries: Tensor, keys: Tensor, query_pe: Tensor, key_pe: Tensor
) -> Tuple[Tensor, Tensor]:
# Self attention block
if self.skip_first_layer_pe:
queries = self.self_attn(q=queries, k=queries, v=queries)
else:
q = queries + query_pe
attn_out = self.self_attn(q=q, k=q, v=queries)
queries = queries + attn_out
queries = self.norm1(queries)
# Cross attention block, tokens attending to image embedding
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_token_to_image(q=q, k=k, v=keys)
queries = queries + attn_out
queries = self.norm2(queries)
# MLP block
mlp_out = self.mlp(queries)
queries = queries + mlp_out
queries = self.norm3(queries)
# Cross attention block, image embedding attending to tokens
q = queries + query_pe
k = keys + key_pe
attn_out = self.cross_attn_image_to_token(q=k, k=q, v=queries)
keys = keys + attn_out
keys = self.norm4(keys)
return queries, keys
4 steps:
(1) self-attention on the tokens (prompt tokens)
(2) cross-attention from tokens (as queries) to the image embedding
(3) a point-wise MLP updates each token (prompt token)
(4) cross-attention from the image embedding (as queries) to tokens (prompt tokens)
???This last step updates the image embedding with prompt information
To ensure the decoder has access to critical geometric information,the positional encodings are added to the image embedding whenever they participate in an attention layer.
Additionally, the entire original prompt tokens (including their positional encodings) are re-added to the updated tokens whenever they participate in an attention layer. This allows for a strong dependence on both the prompt token’s geometric location and type
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 厂务设备设施中如何使用工具实现预测性维护(PdM)
- 声明式管理方法(yaml文件)
- 依赖注入实现原理
- 代码随想录补|leetcode78 子集问题
- 如果您在 Ubuntu 上完成了交叉编译,并希望将程序部署到目标设备上运
- Mixtral-8x7B 超炫的开源“sparse model”(稀疏模型)
- 什么是堡垒机
- 计算机网络(2)
- iOS和iPadOS设备启动到打开App
- openssl3.2 - 官方demo学习 - digest - EVP_MD_demo.c