大模型实战营Day6 OpenCompass 大模型评测
发布时间:2024年01月20日
为什么需要评测?模型选型 模型能力提升 真实应用场景效果评测
我们需要测什么?知识推理语言 长文本智能体多轮对话 情感认知价值观
怎么样测试大语言模型?自动化客观评测 人机交互评测 基于大模型的大模型评测

普通用户: 了解诶模型的特色能力和实际效果
开发者:监控模型能力变化,指导优化模型生产
管理机构:减少大模型带来的社会风险
产业界:找出最适合产业应用的模型,赋能真是场景

客观评测
主观评测

提示词工程:问题的不同问法

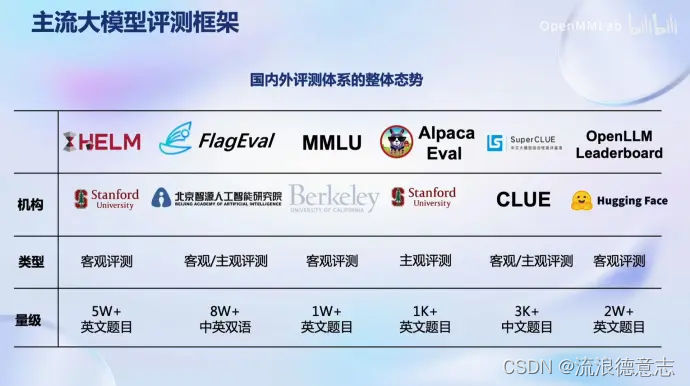
主流大模型评测框架
OpenCompass能力框架

Meta官方推荐

平台架构

100+数据集
任意模型
任务切分
多种输出方案

前沿探索MMBench

垂直领域 ?法律 医疗

挑战

文章来源:https://blog.csdn.net/li4692625/article/details/135711683
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- lodash源码分析每日一练 - 数组 - flatten / flattenDeep / flattenDepth
- Elasticsearch实现全文搜索的步骤和实现原理
- ipv6-ipv4隧道和bgp全网通小实验
- LeetCode——1954. 收集足够苹果的最小花园周长
- 盘点那些好用的抠图神器让你轻松完成抠出人像换背景
- 全球日光地图分布地图数据
- ChatGPT和文心一言哪个更好用?
- 百模大战中AI行业发展有何新趋势?AI角度与普通人的角度
- IIC协议24c02存储花样灯程序(IIC协议程序)
- TypeScript