Dubbo架构设计解析
大话RPC和Dubbo
Dubbo是阿里巴巴在2012年开源的分布式服务治理框架,不仅是阿里巴巴在开源领域最出名的项目,也应该算称得上是国内影响力最大的开源大作。可是大家有所不知,阿里内部实际上都在使用另一个RPC框架叫HSF(Dubbo和HSF的开发团队是同一拨人马,造轮子狂热症患者),Dubbo这些年浮浮沉沉,也曾经一度停止了更新,而随着18年Dubbo3.0的强势推进,相信这个大版本中Dubbo会充分借鉴HSF在超高并发场景下积累的经验。
在服务治理领域的泰山北斗是RPC和HTTP两派,据我观察,国内公司更偏爱基于RPC的微服务解决方案,国外公司则是偏爱SpringCloud全家桶,不光是在服务治理的技术选型上有这种国内、国外的差别,很多开源组件的选型上都有这种地域色彩(拿持久层框架来说,国内偏爱使用iBatis/MyBatis,国外更偏爱ORM框架)
我个人偏向来说是建议使用SpringCloud,并不是说SpringCloud在服务治理领域做得比Dubbo更好,而是更看好SpringCloud的体系构建能力。毕竟不是所有公司都有阿里这样的技术背景,可以为了追求极致造各种轮子,大部分公司需要的其实是SpringCloud这样的微服务全套解决方案。就像盖房子一样,SpringCloud作为一家供应商,提供了应有尽有的各种建筑原材料,不用再为每个环节去费心选材。
Dubbo的特性
Dubbo是一款轻量级+高性能的RPC框架,所谓天下武学殊途同归,Dubbo的很多理念和Spring Cloud中的组件都差不多。我们就来看一下Dubbo的几个核心特性,顺带和SpringCloud中的组件关联对比一下
基于接口+动态代理的远程方法调用
Dubbo对开发者屏蔽了底层的调用细节,在实际代码中调用远程服务就像调用一个本地接口类一样方便。这个功能和Feign很类似,但是Dubbo用起来比Feign还要简单很多,Feign有时还要独立声明一个新接口,而Dubbo真的就是拿到公共接口类后直接就能用。
负载均衡
Dubbo内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。这部分功能和Ribbon十分接近,但是Dubbo的负载均衡策略不如Ribbon的多,而且Dubbo的负载均衡能力只能供自己享用,而Ribbon可以赋能给SpringCloud里的各个组件。
集群容错
Dubbo提供了一个Cluster组件专门用来做集群容错,它其实并不是Hystrix这类降级组件。
服务治理
支持多种注册中心服务,服务实例上下线实时感知。这里面的功能相信大家都能猜个八九不离十,就是服务注册、服务发现、服务下线之类的流程,这些功能和Eureka里的概念是一样一样的,只是实现方式却大有不同。比如Dubbo在服务下线后会主动将可用服务列表下发到各个服务节点,送货上门服务周到,而Eureka每次都等着服务节点自己上注册中心来拿数据,不给包邮的。
除了上面几个核心特性以外,还有诸如运行期流量调度(灰度、路由规则等)和可视化服务治理(运维工具,数据统计)等功能,我们就不一一介绍了。
可以这么说,Dubbo的技能加点比较专一,全点在了服务治理系,单就服务治理来看的话确实做得比Eureka要细致一些的。但是要论体系的话,还是不可能和Spring Cloud相提并论的。
Dubbo架构
我们先来认识下Dubbo中的五个基础组件,下面图里的紫色线条代表了组件初始化的路径,蓝色虚线是异步通知流程,蓝色实线则是同步阻塞调用。
上图中出现的五个组件分别对应如下功能
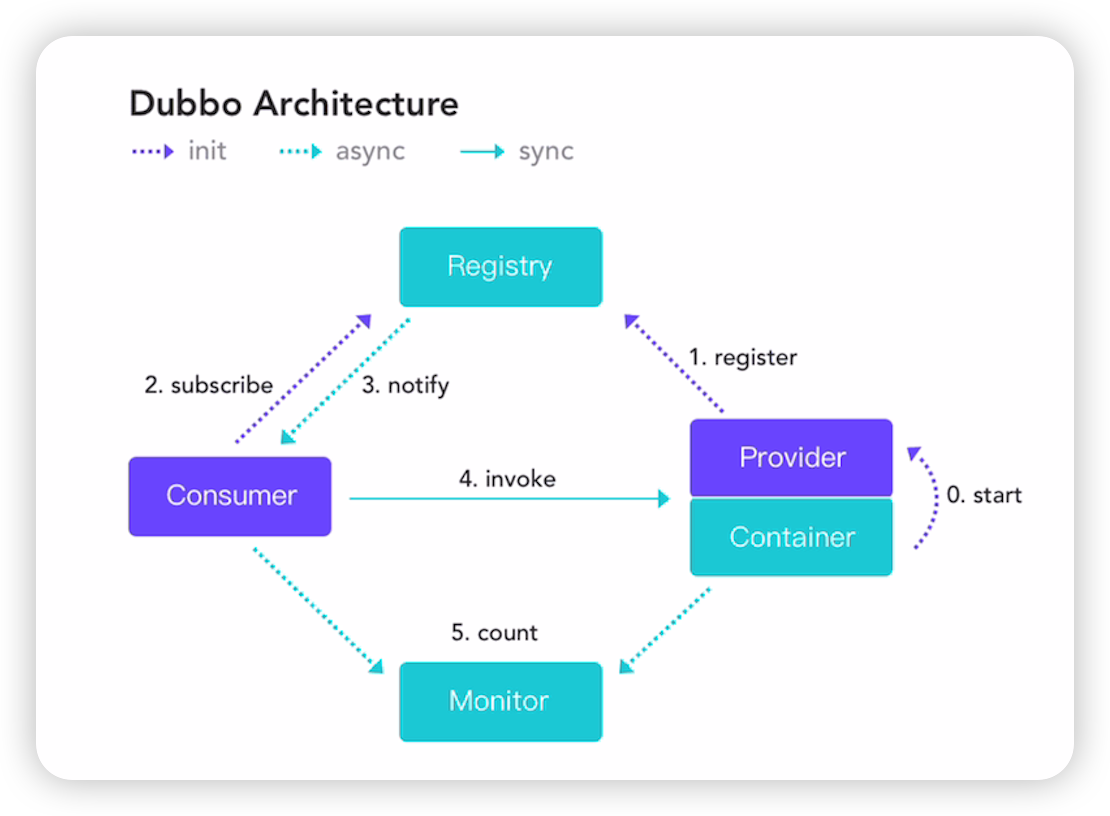
上图中出现的五个组件分别对应如下功能
| 组件名称 | 说明 |
|---|---|
| Registry | 注册中心 |
| Provider | 服务提供方 |
| Consumer | 向Provider发起远程调用的消费者 |
| Monitor | 监控中心,用来统计服务调用的频率和响应时间 |
| Container | 运行服务的容器 |
我们弄清楚了谁是谁之后,来捋一捋RPC调用的来龙去脉。我们就顺着图中的步骤标号,从0到5挨个说一下:
- Start 服务容器启动后初始化服务提供者
- Register 服务提供者在启动的过程中,向注册中心发起注册,这个步骤和Eureka的流程很像
- Subscribe 服务消费者在启动的同时,向注册中心订阅所需的服务。这一个流程就和Eureka就大不相同了,Eureka是Consumer主动到服务中心去拉取数据,而Dubbo采用了一种Pu b/Sub模式,也就是发布订阅模型
- Notify 注册中心将Provier地址列表发送给消费者,对于服务下线之类的变更,注册中心会主动推送变更数据到Consumer(建立在长连接之上)
- Invoke 服务消费者发起远程调用,这个过程会使用负载均衡算法挑选目标服务器
- Count Consumer和Provider每隔一段时间将统计信息发送到监控中心,平时这些信息就暂存于内存当中
Dubbo和Eureka中服务发现的不同
服务发现应该是Dubbo和Eureka最大的一个不同之处。
Dubbo里的注册中心、Provider和Consumer三者之间都是 长连接,借助于Zookeeper的高吞吐量,实现基于服务端的服务发现机制。因此Dubbo利用Zookeeper+发布订阅模型可以很快将服务节点的上线和下线同步到Consumer集群。如果服务提供者宕机,那么注册中心的长连接会立马感知到这个事件,并且立即推送通知到消费者。
在服务发现的做法,上Dubbo和Eureka有很大的不同,Eureka使用客户端的服务发现机制,因此对服务列表的变动响应会稍慢,比如在某台机器下线以后,在一段时间内可能还会陆续有服务请求发过来,当然这些请求会收到Service Unavailable的异常,需要借助Ribbon或Hystrix实现重试或者降级措施。
对于注册中心宕机的情况,Dubbo和Eureka的处理方 式相同,这两个框架的服务节点都在本地缓存了服务提供者的列表,因此仍然可以发起调用,但服务提供者列表无法被更新,因此可能导致本地缓存的服务状态与实际情况有别。
本文已收录至我的个人网站:程序员波特,主要记录Java相关技术系列教程,共享电子书、Java学习路线、视频教程、简历模板和面试题等学习资源,让想要学习的你,不再迷茫。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 分割数组的最大差值 - 华为OD统一考试
- Docker:docker exec命令简介
- 助力智能人群检测计数,基于YOLOv3开发构建通用场景下人群检测计数识别系统
- Leetcode—216.组合总和III【中等】
- netty源码:(29)ChannelInboundHandlerAdapter
- EasyExcel 写Excel超过限制自动切换sheet
- 海量并发场景下,如何实现分布式事务
- kubeadm快速部署Kubernetes 1.29.0版本集群
- 在Multisim中定位555芯片的方法及操作步骤解析
- SpringBoot 创建定时任务(配合数据库动态执行)