Linux开发工具及其安装
文章目录
Linux软件包管理器yum
在Linux下安装软件,一个常用的办法是先下载程序的源代码,然后编译就可以得到可执行程序。还有一种更为常用的方法就是利用软件包直接安装,软件包是由一些人把常用的软件提前编译好做成的,类似于App,而yum则是Linux下的软件包管理器,类似于应用商店。yum的默认软件来源是base源(基础软件源),如果需要,用户也可以将软件来源改为epel(拓展软件源)。当epel中的某些软件经过检验没有问题时,就会被加入base中。
查找软件:
yum list | grep gcc//搜索软件gcc

软件安装:
sudo yum install gcc //安装软件gcc
yum安装软件时只能安装完一个才能再进行下一个软件的安装,否则会出错。
软件卸载:
sudo yum remove gcc//卸载软件gcc
Linux开发工具
集代码编写、编译、运行、调试于一体的开发环境称为集成开发环境,如VS,Linux下这些功能是分开用不同的工具完成的:用vim编写代码,用gcc/g++进行编译,用gdb进行调试,用make/makefile来维护项目。
Linux编辑器-vim
vim一共有12种模式,我们先掌握3种常用的模式:命令模式、插入模式、末行模式,我们使用vim时,默认是处于命令模式。
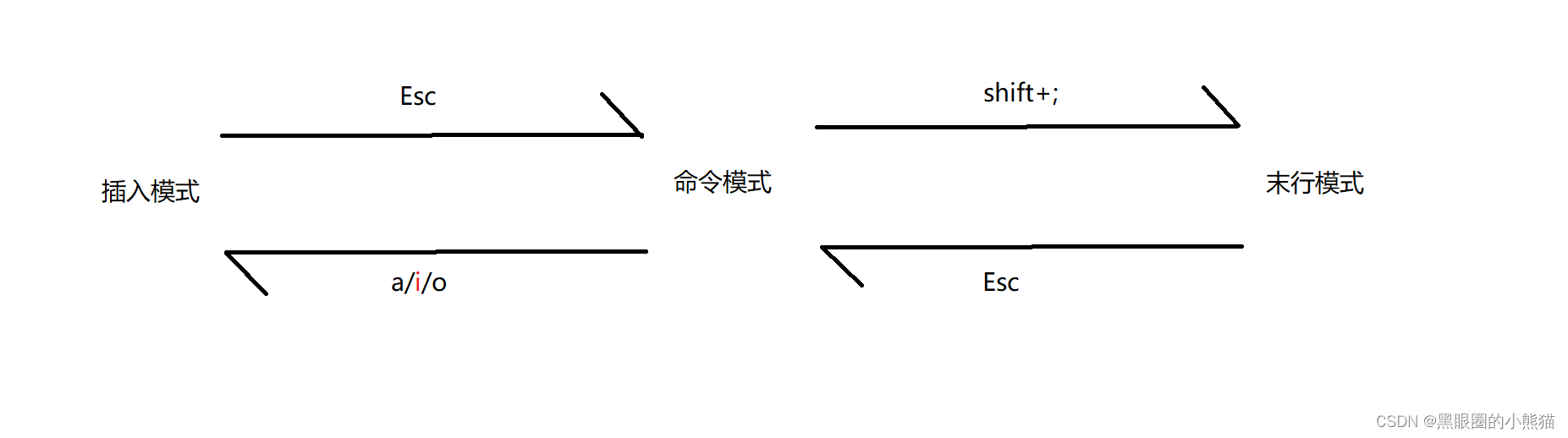
命令模式
命令模式也称为正常模式、普通模式,在该模式下,所有的输入都被当做命令看待,无法使用鼠标,用于控制屏幕光标的移动,字符、字或行的删除,移动或复制某区段以及进入插入模式或末行模式。
正常模式的命令集如下:
一、移动光标:
h:光标左移一格
k:光标上移一格
j:光标下移一格
l:光标右移一格
G:光标移动到文本的末尾
gg:光标移动到文本的开头
num+shift+g:光标移动到第num行的行首
$:光标移动到所在行的行尾
^:光标移动到所在行的行首
num+l:光标移动到该行的第num列
Ctrl+f:光标移动到下一页
Ctrl+b:光标移动到上一页
Ctrl+u:光标往上移动半页
Ctrl+d:光标往下移动半页
b:光标跳到上个字的开头
e:光标跳到下个字的末尾
w:光标跳到下个字的开头
二、删除文字:
x:删除光标当前所在位置的一个字符
num+x:删除光标所在位置后面(包括自己在内)的num个字符
X:删除光标所在位置前面一个字符
num+X:删除光标所在位置前面num个字符
dd:删除光标所在的行
num+dd:删除从光标开始所在行的num行(其实是将其剪切掉)
三、复制粘贴:
yy:复制光标所在的行
num+yy:复制光标所在行后面(包括自己在内)的num行
p:将字符粘贴到光标所在位置
num+p:粘贴num次
四、操作撤销:
u:恢复到上一次操作
Ctrl+r:撤销u操作
五、替换:
r:替换光标所在位置的一个字符
R:替换光标所到之处的字符,直到按下Esc(其实是进入了替换模式)
六、其他:
1、批量注释步骤:
①Ctrl+v
②使用hjkl选择区域
③shift+i
④//
⑤Esc
2、去除批量注释步骤:
①Ctrl+v
②使用hjkl选择区域
③d
3、多窗口编辑时按下Ctrl+ww将光标从一个窗口移动到另一个窗口
插入模式
在该模式下,可以进行文本的编辑工作,从命令模式进入插入模式有3个按键:
①a:进入插入模式,并将后移一格
②i:直接进入插入模式,不移动光标
③o:进入插入模式,同时新增一行并将光标移动到该行
一般我们使用i即可
末行模式
该模式一般用于进行文件的保存和退出工作,也可以进行文本替换、查找字符串、列出行号等工作,其常用命令如下:
w:保存当前文件
wq:保存当前文件并退出vim编辑
q!:强制退出vim编辑,不保存
!+指令:先执行该指令,不退出vim
set nu:显示行号
set nonu:去除行号
vs filename:创建新文件
/+关键字:往后查找,按n再查找下一个
?+关键字:往前查找,按n再查找前一个
简单的vim配置
vim提供的文本编辑方式可能不符合用户的编辑习惯,如缩进的间隔大小、括号的匹配等等,用户都可以根据自己的喜好进行调整,只需要修改vim配置文件即可。
在目录/etc/下的vimrc文件,是属于系统中公共的vim配置文件,修改该文件,对所有用户都有效,而在用户的家目录下,也有个名为.vimrc的vim配置文件,修改该文件,只对当前用户有效。
我们只需要在该文件里面写入或删除某条指令选项,就可以增加或去除某项编辑功能,常用的配置选项网上自行搜索即可。
Linux编译器-gcc/g++
gcc可以编译c语言,g++可以编译c语言、c++,gcc与g++提供的选项是一样的。
以gcc为例,其编译过程如下:
在预处理阶段,主要进行宏定义的替换,头文件的包含,条件编译,去除注释等,一般用以.i为后缀的文件表示已经预处理过的c原始程序。
在编译阶段,gcc会检查代码的规范性、是否有语法错误等,检查无误后,将代码翻译成汇编语言,即生成汇编代码,一般用以.s为后缀的文件表示经过编译的文件。
在汇编阶段,主要是将编译阶段生成的汇编代码转成二进制代码,生成以.o为后缀的目标文件,但此时该二进制文件还不能被执行。
在链接阶段,会进行各种函数库的链接,gcc会按照系统默认的搜索路径/usr/lib查找函数库并链接(如果是自己写的函数库在链接时要指明路径)。
这里谈一下函数库,平台要支持开发,就要提前在系统中安装好语言的头文件和库文件,函数库一般分为动态库和静态库。如果使用静态库,那么在编译链接时,会把库文件的代码全部加入到可执行文件中,因此生成的可执行文件比较大,但运行时就可以不再依赖静态库了;如果使用动态库,那么在编译链接时不会把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,gcc在编译时默认采用的是动态库。在Linux下,动态库文件名后缀为.so,静态库文件后缀为.a,在Windows下,动态库文件名后缀为.dil,静态库文件名后缀为.lib。因此动态库的优点是节省资源(包括磁盘、内存、网络(下载时)等),其缺点是对库的依赖性太强,一旦库出现问题,使用这个库的程序也会出问题,同时库调用时也会有一定的效率消耗;静态库的优点是编译完后不再依赖于库,在同类型平台下程序可以直接运行使用,其缺点是可执行程序非常大,十分浪费资源。
gcc选项:
-E:只进行预处理阶段,暂停编译(该选项不生成文件,需要手动重定向到一个输出文件里)
-S:进行编译阶段,暂停汇编过程(该选项不生成文件,需要手动重定向到一个输出文件里)
-c:进行汇编阶段,暂停链接阶段
-o:输出到文件中
-static:生成的文件采用静态链接
-g:生成调试信息
-w:不生成任何警告信息
-Wall:生成所有警告信息
简记成:ESc,iso
gcc -E test.c -o test.i//预处理
gcc -S test.i -o test.s//编译
gcc -c test.s -o test.o//汇编
Linux调试器-gdb
程序的发布方式有两种:debug模式和release模式,debug模式会添加各种调试信息,体积较大,供开发者使用,release模式则去除了各种调试信息,体积较小,共用户使用。gcc和g++生成的二进制程序默认是release模式,因此如果要使用gdb进行调试,在源代码生成二进制程序时,要加上-g选项。
gcc -g test.c -o test//生成可调试的文件test
调试命令:
l:显示要调试文件的源代码,从上次位置一次往下列10行
l 函数名:列出该函数的源代码
r/run:运行程序
n/next:单条执行
s/step:进入函数调用
c/continue:从当前位置开始连续而非单步执行
b/break num:在num行设置断点
b/break 函数名:在某个函数开头设置断点
i/info b/break:查看断点信息(y表示断点启用,n表示断点禁用)
p/print 表达式:打印表达式结果(p &n:打印n的地址)
set var:修改变量的值
d/(delete breakpoints):删除所有断点
d/(delete breakpoints) num:删除序号为num的断点
disable breakpoints:禁用所有断点
disable breakpoints num:禁用序号为num的断点
enable breakpoints:启用所有断点
enable breakpoints num:启用序号为num的断点
display 变量名:跟踪查看某一个变量,每次停下都显示该变量的值
undiaplay 变量名:取消对某个变量的跟踪
until 表达式:当表达式为真时,程序暂停
q/quit:退出gdb调试
Linux项目自动化构建工具-make/makefile
make是一个命令,makefile是一个文件,在一个工程中,源文件数量众多,其会按类型、功能、模块放在若干个目录下,makefile文件则定义了一系列规则来指定哪些文件先编译,哪些文件后面编译,哪些文件要重新编译以及进行一些更复杂的操作,再通过make命令工具解释makefile中的指令,从而完成项目的自动化构建。
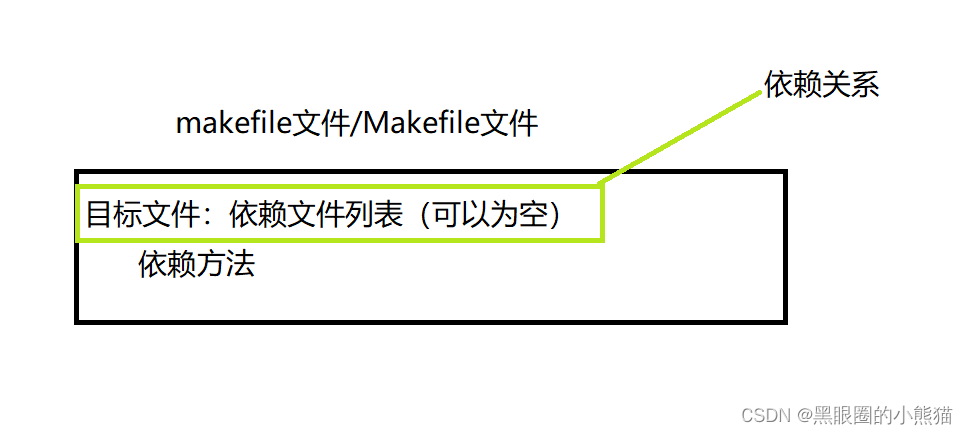
test:test.o
gcc test.o -o test
test.o:test.s
gcc -c test.s -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
make自上而下推导依赖关系,自下而上执行依赖方法,其默认工作方式如下:
①make在当前目录下寻找到名为makefile或者Makefile的文件
②找第一个依赖关系的目标文件作为最终目标文件,如上面的test文件
③如果最终目标文件test不存在或者test文件的依赖文件test.o的修改时间比test新,则根据test.o文件重新生成test文件
④后面的执行步骤与③类似,直到依赖文件存在,再由下往上生成目标文件
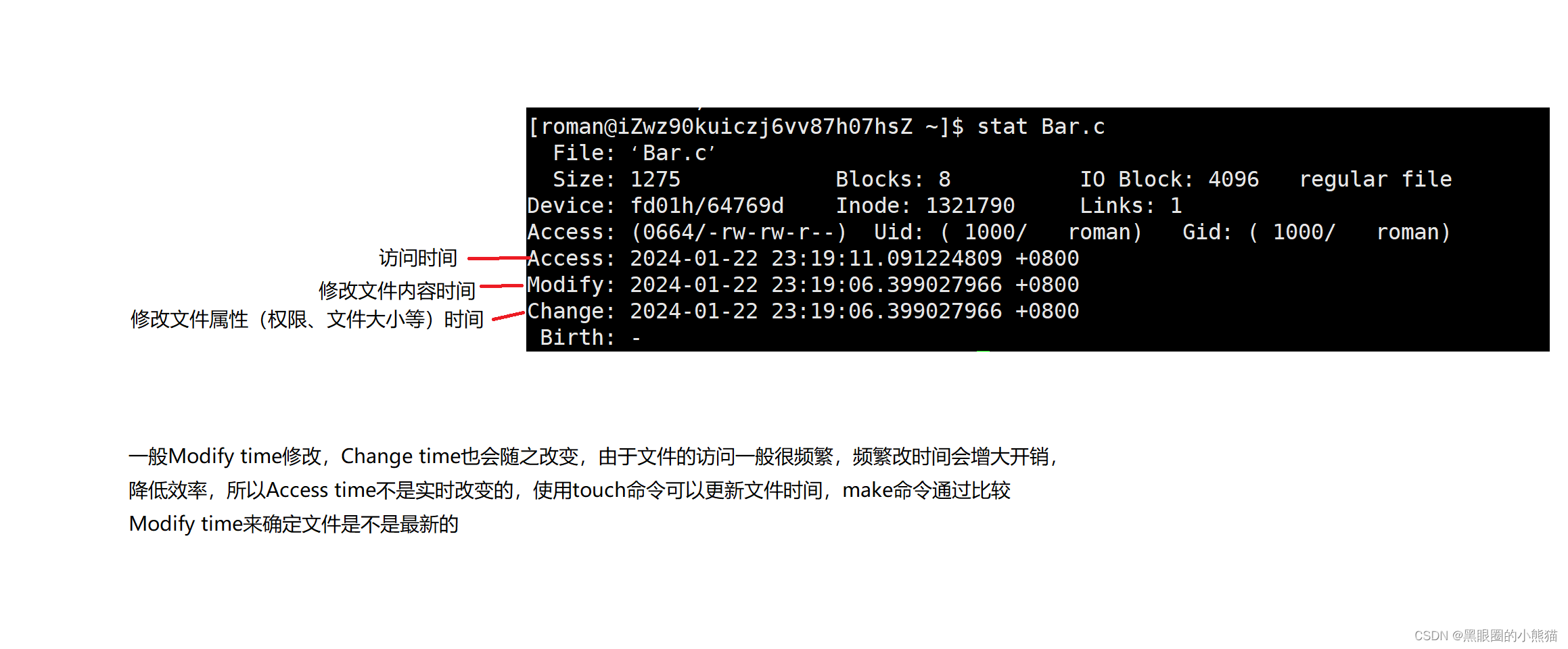
通过stat可以查看文件的修改时间
.PHONY : file
.PHONY修饰目标文件file为伪目标文件,该文件的依赖方法总要被执行,而不管改文件内容有没有改变,一般用于项目的清理工作。
.PHONY : clean
rm -f test.i test.s test.o
像clean这种文件并没有与最终目标文件test有直接或者间接关联,其后面的依赖方法不会被执行,不过我们可以显示的要make执行其命令,即
make clean。
由源文件生成目标文件可以简写成:
test : test.c
gcc -o $@ $^
这里的 $@表示目标文件名, $^表示所有依赖项列表,即编译目标所依赖的所有源文件。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux入门攻坚——13、实战软件安装-搭建Python3.8环境-1
- Python 简易单词拼写背诵代码
- 使用AI大模型增强图像清晰度
- 易点易动固定资产管理系统:集成飞书,助力企业全生命周期固定资产管理
- Vue3中的组件的name名
- java技术专家 【DDD(领域驱动设计)思想解读及优秀实践 06】|领域建模实践(下):领域建模还有什么其他技巧?
- getopt()函数详细解释!保证看明白
- Linux学习小结
- 【Java基础】BIO/NIO/AIO的详细介绍与比较区分
- 应用于股市的凯利公式讲解、推导与Python实现