深入理解奥运会大数据架构方案
背景
某网作为某电视台在互联网上的大型门户入口,某一年成为某奥运会中国大陆地区的特权转播商,独家全程直播了某奥运会全部的赛事,积累了庞大稳定的用户群,这些用户在使用各类服务过程中产生了大量数据,对这些海量数据进行分析与挖掘,将会对节目的传播及商业模式变现起到重要的作用。
该奥运期间需要对增量数据在当日概览和赛事回顾两个层面上进行分析。
其中,当日概览模块需要秒级刷新直播在线人数、网站的综合浏览量、 页面停留时间、视频的播放次数和平均播放时间等千万级数据量的实时信息,而传统的分布式架构采用重新计算的方式分析实时数据在不扩充以往集群规模的情况下,无法在几秒内分析出重要的信息。
赛事回顾模块需要展现自定义时间段内的历史最高在线人数、逐日播放走势、直播最高在线人数和点播视频排行等海量数据的统计信息,由于该奥运期间产生的数据通常不需要被经常索引、更新,因此要求采用不可变方式存储所有的历史数据,以保证历史数据的准确性。
设计思路
当日概览模块采用流处理方式实现实时计算,在几秒内分析出重要的信息。
赛事回顾模块采用批处理方式实现复杂数据分析,采用不可变方式存储所有的历史数据,以保证历史数据的准确性。
架构图
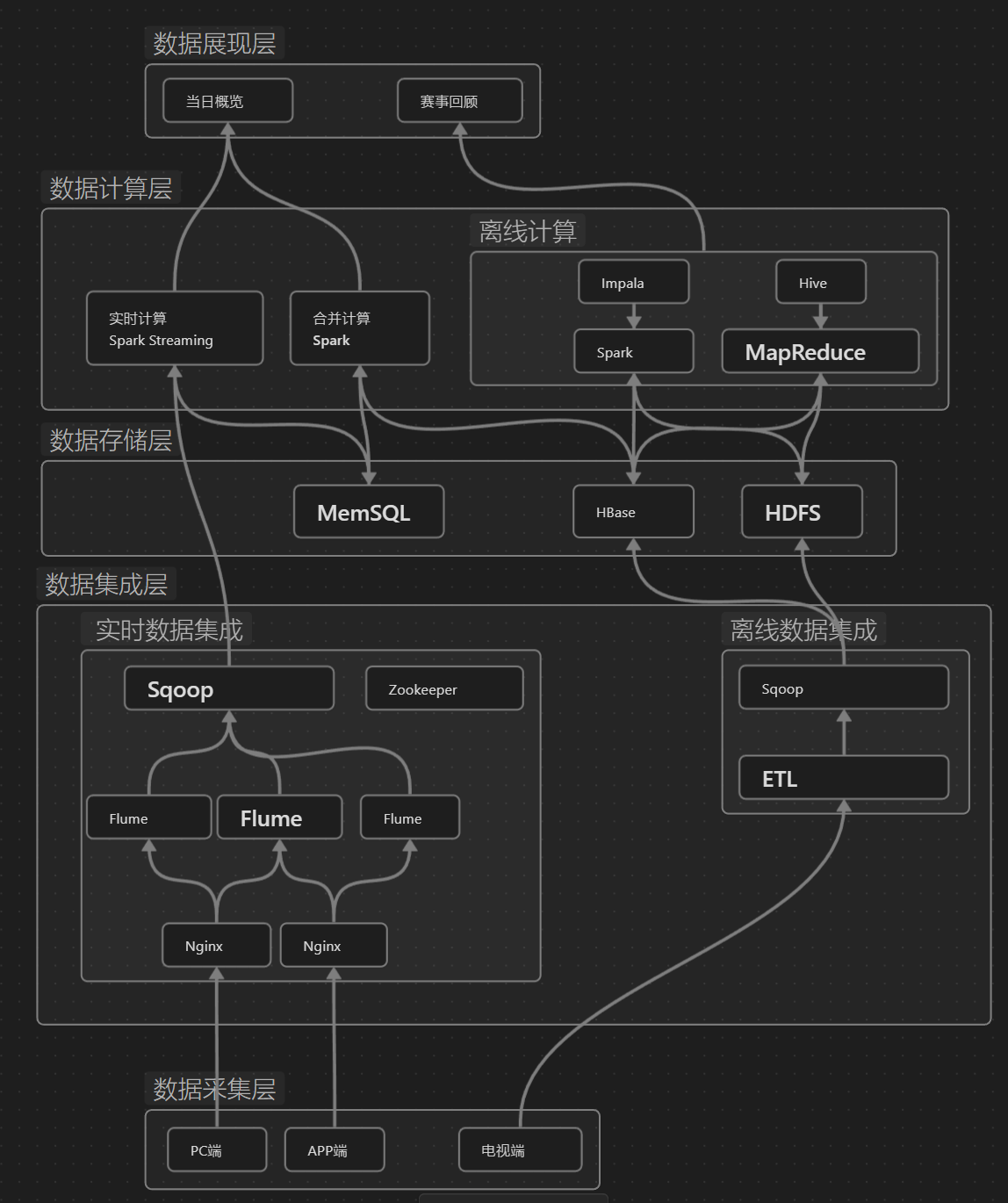
这张图是一个大数据技术栈的架构图,它展示了不同的大数据组件及其之间的关系。下面是这张图的解析:
数据采集层
- 实时数据采集
-
Flume:用于收集、聚合和传输大量日志数据。
-
- 批量数据采集
-
ETL:提取转换加载。
-
数据存储层
-
HDFS:Hadoop分布式文件系统,用于存储大数据。 -
HBase:基于Hadoop的非关系型分布式数据库。 -
MemSQL:内存优化的分布式关系数据库,支持实时分析。
数据计算层
- 批处理计算
-
Hive:建立在Hadoop之上的数据仓库,提供SQL查询功能。 -
Impala:用于Hadoop的开源即席查询引擎。
-
- 流处理计算
-
Spark Streaming:开源的分布式计算系统,提供批处理和流处理的计算模型。
-
这个架构图表明,数据从不同的终端(PC端、APP端、电视端)被采集,通过实时或批量的方式进入数据采集层,然后存储在数据存储层的不同系统中。数据计算层负责处理这些数据,无论是批处理还是流处理。数据管理层提供必要的服务来协调这些计算任务。最后,数据通过ETL流程被处理,并供最终用户在不同的终端消费。
技术栈
-
Zookeeper 是一个分布式协调服务,存储和同步分布式系统的配置信息,提供分布式锁和同步机制。
-
Sqoop 是一个传输数据的工具。可以将大量数据从关系数据库导入到Hadoop的HDFS中。
-
Flume 是一个用于收集、聚合和移动大量日志数据的分布式系统。
-
Nginx 是一个高性能的HTTP和反向代理服务器。
-
MemSQL 是一个内存中的分布式数据库,它将内存存储和SQL查询结合起来,提供实时分析处理能力。
-
HBase 是建立在Hadoop之上的一个分布式、可扩展、支持海量数据存储的NoSQL数据库。
-
HDFS (Hadoop Distributed File System)是Hadoop的核心组件之一,是一个分布式文件系统,专为存储大数据而设计。
-
Spark Streaming 是基于Apache Spark的实时数据流处理框架。它扩展了Spark的RDD(弹性分布式数据集)模型,以处理实时数据流。
-
Impala 是一个开源的大数据查询引擎,由Cloudera开发。Impala设计用于在存储于Hadoop文件系统中的大数据上进行快速、低延迟的查询。
-
Hive 是一个基于Hadoop的数据仓库工具,用于处理大量的数据。Hive定义了一种类SQL查询语言,称为HQL(Hive Query Language),它将SQL语句转换成MapReduce任务执行。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PADS9.5 : 元件库绘制
- 在React中实现好看的动画Framer Motion(案例:滚动进度条)
- RHCE9学习指南 第12章 ssh远程登录系统和远程拷贝
- CSS超链接伪类
- ThinkPHP5.0.0~5.0.23路由控制不严谨导致的RCE
- 服务异步通讯——springcloud
- XTU-OJ-1452-完全平方数-笔记
- 推动行业未来的八个数字化转型趋势
- 全面开花!聚铭网络入选《ISC 2023数字安全创新能力全景图谱》10大细分领域
- JavaScript中alert、prompt 和 confirm区别及使用【通俗易懂】