为什么有些网址存在大量的百分号、字母和数字?
今天,我给一个朋友分享了我刚写的一篇文章的链接。在我的浏览器中,我看到的链接是这样的:
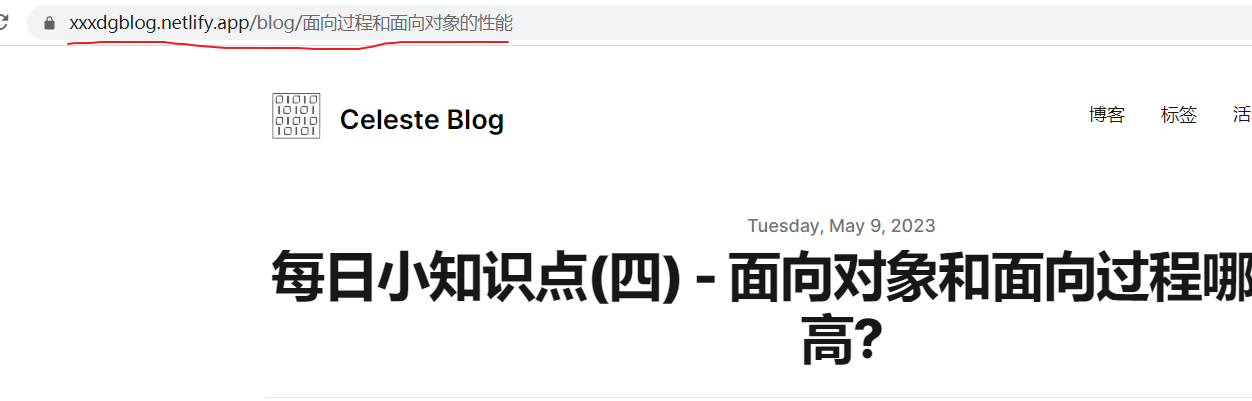
但是当我把这个链接复制给我的朋友时,我发现这个链接发生了巨大的变化:

为什么汉字变成了这么多的字母、数字和百分号?
原因在于 URL 中只能包含 ASCII 码(字符编码范围是 0 ~ 127)的字符,而汉字、特殊字符等非 ASCII 码字符是不能直接出现在 URL 中的,需要进行编码转换后才能在 URL 中使用。
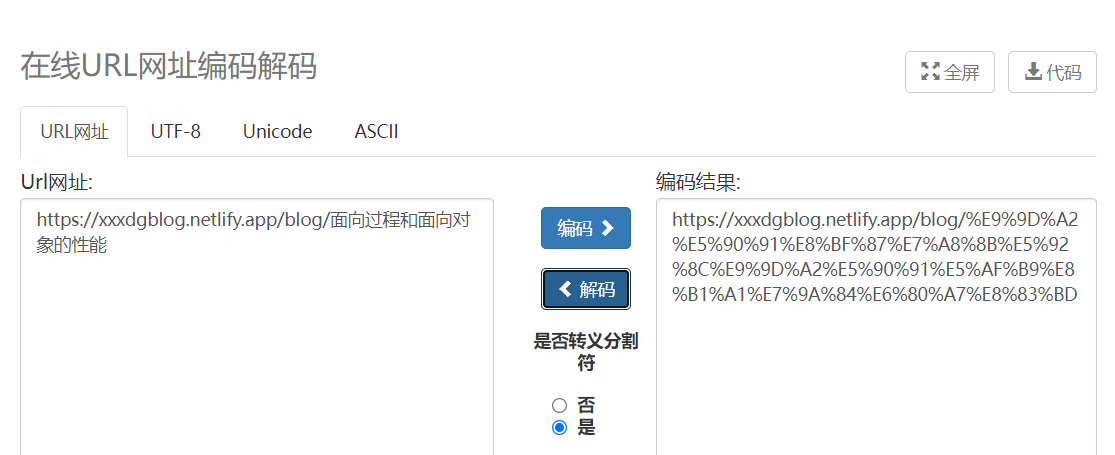
例如,对于汉字 “中”,它的 Unicode 编码是 U4E2D,对应着 UTF-8 编码是 E4 B8 AD。在 URL 中,需要将其转换为 %E4% B8%AD 的形式,其中“%”后面的两个十六进制数字表示该字符的 UTF-8 编码,即“E4B8AD”。这种编码方式被称为百分号编码(Percent-encoding)或 URL 编码(URL encoding),用于将 URL 中的非 ASCII 码字符转换为 ASCII 码字符序列。
- 汉字的 Unicode 表示:这四个汉字的 Unicode 表示如下:
- ‘面’ 的 Unicode 表示为 \u9762
- ‘向’ 的 Unicode 表示为 \u5411
- ‘过’ 的 Unicode 表示为 \u8FC7
- ‘程’ 的 Unicode 表示为 \u7A0B
- 汉字的 UTF-8 表示:这四个汉字的 UTF-8 表示如下:
- ‘面’ 的 UTF-8 表示为 E9 9D A2
- ‘向’ 的 UTF-8 表示为 E5 90 91
- ‘过’ 的 UTF-8 表示为 E8 BF 87
- ‘程’ 的 UTF-8 表示为 E7 A8 8B
注意,以上 UTF-8 表示是每个汉字各占用三个字节。
因此,在一些网址中会存在大量的百分号、字母和数字的形式,用于对 URL 进行编码转换。这样可以确保 URL 在网络传输过程中不会出现解析错误、乱码等问题,确保在不同的浏览器、操作系统、设备上都可以正常地打开。
最后,我又通过 在线工具 测试一下:
题外话:Unicode 和 UTF-8 的区别
Unicode 和 UTF-8 都是用于字符编码和字符集的标准。它们都是为了解决国际化和多语言编程的问题而产生的。
Unicode 是一个字符集标准,它定义了一种标准的字符集,并为字符分配了唯一的编码值。Unicode 中,每个字符都拥有一个唯一的代码点,代码点是一组数字,通常用 16 进制数表示。Unicode 能够表示全球范围内的所有字符,包括汉字、拉丁字母、希腊字母、日文字母等等。
UTF-8 是一种可变长度编码,它将 Unicode 字符集中的每个字符编码成一个字节序列。UTF-8 的编码方式与 ASCII 码兼容,符合规则的 ASCII 码使用一个字节编码,而非 ASCII 码的字符使用两个或多个字节编码。UTF-8 通过在编码时使用不同长度的字节序列来表示 Unicode 字符,这样能够表示所有的 Unicode 字符,并且可以处理二进制数据,适用于计算机系统内部和各种文件格式的存储和处理。
因此,Unicode 是一种字符编码标准,而 UTF-8 是一种字符编码实现。UTF-8 基于 Unicode 标准,使用了 Unicode 中的字符集和编码,扩展了 Unicode 的能力,并且具有向后兼容性,是目前使用最广泛的国际化字符编码方案。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!