机器学习(三) -- 特征工程(2)
系列文章目录
未完待续……
目录
2.5、皮尔逊相关系数(Pearson Correlation Coefficient)
前言
tips:这里只是总结,不是教程哈。
“***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。
此处以下所有内容均为暂定,因为我还没找到一个好的,让小白(我自己)也能容易理解(更系统、嗯应该是宏观)的讲解顺序与方式。
第一文主要简述了一下机器学习大致有哪些东西(当然远远不止这些),对大体框架有了一定了解。接着我们根据机器学习的流程一步步来学习吧,掐掉其他不太用得上我们的步骤,精练起来就4步(数据预处理,特征工程,训练模型,模型评估),其中训练模型则是我们的重头戏,基本上所有算法也都是这一步,so,这个最后写,先把其他三个讲了,然后,在结合这三步来进行算法的学习,兴许会好点(个人拙见)。
三、特征预处理
1、定义
通过一些转换函数,将特征数据转换成更适合算法模型的特征数据的过程。
1.1、无量纲化
也称为数据的规范化,是指不同指标之间由于存在量纲不同致其不具可比性,故首先需将指标进行无量纲化,消除量纲影响后再进行接下来的分析。
数值数据的无量纲化:主要有两种归一化、标准化
为什么要进行归一化/标准化?
特征的单位或者大小相差较大,或者某特征的方法相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征
特征预处理API
sklearn.preprocessing2、归一化
2.1、定义
将特征缩放到一个特定的范围,通常是[0, 1]。
2.2、分类和公式
2.2.1、线性归一化
这是最常用的归一化,也叫最大-最小归一化或最大-最小规范化。(后面也是用的这种哈)
2.2.1、***最大最小均值归一化
2.2.1、***最大绝对值归一化
2.3、API
sklearn.preprocessing.MinMaxScaler
导入:
from sklearn.preprocessing import MinMaxScaler
2.4、实例

# 2、实例化一个转换器类
transform = MinMaxScaler()
# transform = MinMaxScaler(feature_range=[2,3])
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)转换器中添加feature_range=[2,3]属性,将缩放范围变为[2,3]。

3、标准化
2.1、定义
将特征缩放为均值为0,标准差为1的分布。
2.2、公式
,其中μ是均值,S是标准差
2.3、API
sklearn.preprocessing.StandardScaler
导入:
from sklearn.preprocessing import StandardScaler
2.4、实例
# 2、实例化一个转换器类
transform = StandardScaler()
#transform = StandardScaler(feature_range=[2,3])
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new:\n", data_new)
四、特征降维
1、定义
降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程。
降维的两种方式:特征选择、主成分分析(可以理解一种特征提取的方式)
2、特征选择
2.1、定义
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
2.2、方法
Filter过滤式:
????????????????主要探究特征本身特点、特征与特征和目标值之间关联
????????方差选择法:低方差特征过滤
????????相关系数:特征与特征之间的相关程度
Embedded嵌入式:
????????????????算法自动选择特征(特征与目标值之间的关联)
????????决策树:信息熵、信息增益
????????正则化:L1,L2
????????深度学习:卷积等
2.3、API
sklearn.feature_selection2.4、低方差特征过滤
删除低方差的一些特征
- 特征方差小:某个特征大多样本的值比较相近
- 特征方差大:某个特征很多样本的值都有差别
API
sklearn.feature_selection.VarianceThreshold
导入:
from sklearn.feature_selection import VarianceThreshold

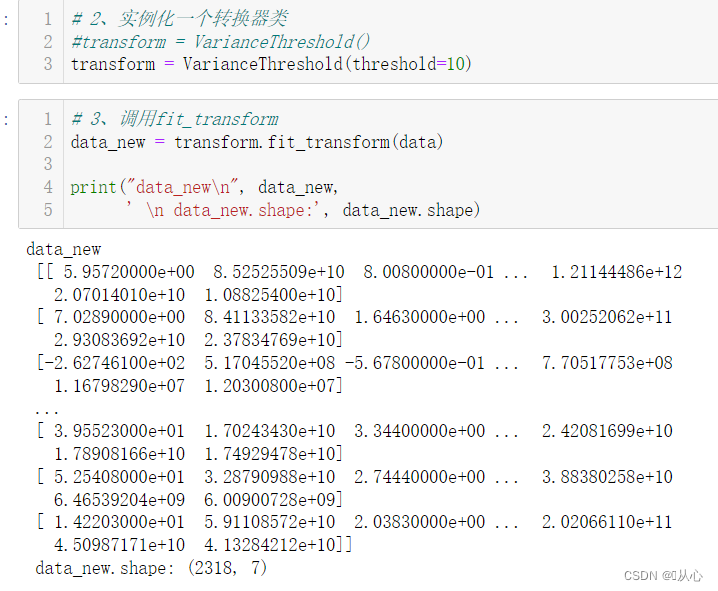
# 2、实例化一个转换器类
#transform = VarianceThreshold()
transform = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new,
' \n data_new.shape:', data_new.shape)?训练集差异低于threadshold的特征将被删除。默认值是保留非零方差特征,即删除所有样本中具有相同值的特征
2.5、皮尔逊相关系数(Pearson Correlation Coefficient)
反映变量之间相关关系密切程度的统计指标.
2.5.1、公式
相关系数的值介于-1与+1之间:
当r>0时,表示两变量正相关;
r<0时,两变量为负相关;
当|r|=1时,表示两变量为完全相关;
当r=0时,表示两变量间无相关关系;
当0<|r|<1时,表示两变量存在一定程度的相关。且|r|越接近1,两变量间线性关系越密切;|r|越接近0,表示两变量的线性相关越弱。
一般可按三级划分:|r|<0.4为低度相关;0.4<=|r|<0.7为显著相关;0.7<=|r|<1为高维线性相关
2.5.2、实例
API
from scipy.stats import pearsonr
from sklearn.feature_selection import VarianceThreshold
# 2、实例化一个转换器类
#transform = VarianceThreshold()
transform = VarianceThreshold(threshold=10)
# 3、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new,
' \n data_new.shape:', data_new.shape)
# 计算两个变量之间的相关系数
r = pearsonr(data["pe_ratio"],data["pb_ratio"])
print("相关系数:\n", r)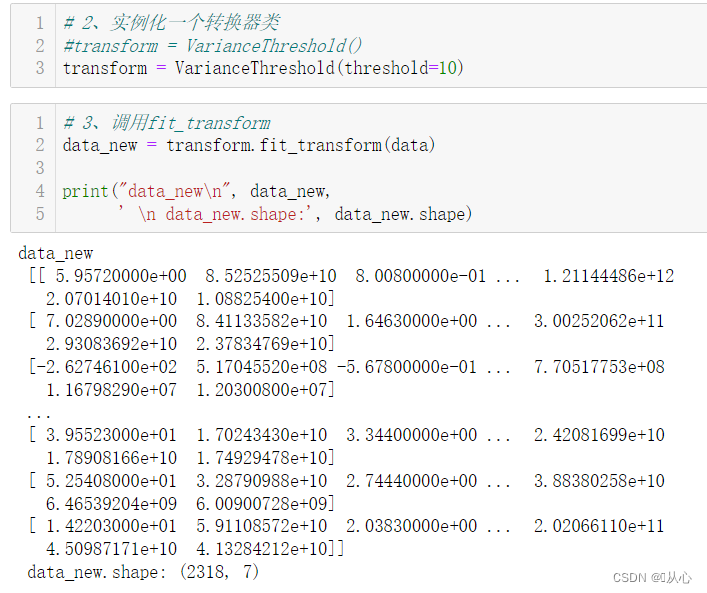
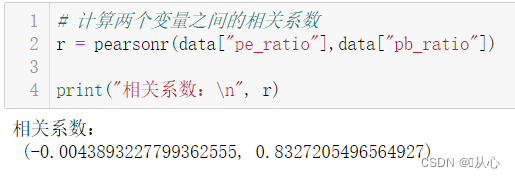
前面的数为相关系数。
3、主成分分析(PCA)
3.1、定义
旨在利用降维的思想,把多指标转化为少数几个综合指标(即主成分),其中每个主成分都能够反映原始变量的大部分信息,且所含信息互不重复。
作用:是数据维数的压缩,尽可能降低原数据的维数(复杂度),损失少量信息
3.2、实例
API
sklearn.decomposition.PCA
导入:
from sklearn.decomposition import PCA![]()

# 1、实例化一个转换器类
transform = PCA(n_components=2) # 4个特征降到2个特征
# 2、调用fit_transform
data_new = transform.fit_transform(data)
print("data_new\n", data_new)
# 1、实例化一个转换器类
transform2 = PCA(n_components=0.95) # 保留95%的信息
# 2、调用fit_transform
data_new2 = transform2.fit_transform(data)
print("data_new2\n", data_new2)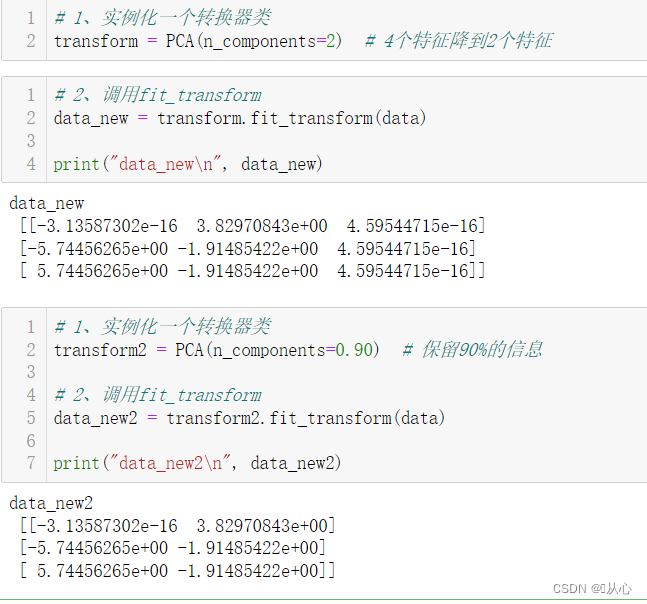
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- VStudio2022导出Qt项目在Linux的Qtcreator中运行修复错误记录
- mybatis-plus代码生成器的UI界面使用非常方便
- 使用哈希表(散列表)+顺序二叉树实现电话簿系统(手把手讲解)
- 安装、运行和控制AI apps在您的计算机上一键式
- 最新捕获!绿斑APT组织钓鱼攻击手法分析
- 【Java集合篇】HashMap的put方法是如何实现的?
- Vcast工程创建
- 超赞的进度条控件
- 数据库视图索引练习
- DQL-分组查询以及WHERE与HAVING的区别