1 pandas与NumPy比较
NumPy
NumPy是用python进行科学计算的一个基础库,因为它提供python基础包没有提供的数据结构和高性能函数。NumPy定义了一种专门用于科学计算的数据结构ndarray - 它是一种N纬数组。特点如下:
- 内存块风格
由于ndarray中的所有元素都是相同的,所以存储元素可连续,故在科学计算中,ndarray可以省掉很多循环语句。 - ndarray支持向量化运算。
- NumPy底层使用C语言编写,解除了GIL。效率远高于纯Python代码。
创建方法
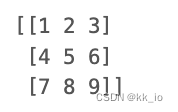
数组最常见的创建方法就是使用array()函数。
import numpy as np
e = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(e)
结果如下:
pandas 定义
pandas 来源于panel data,可见其要处理的数据是多维而非单纬度。Pandas经常和其他工具一起使用,如数值计算工具NumPy和SciPy分析库scikit-learn,以及数据可视化库matplotlib。其中NumPy则是构建Pandas的基础,后者大量借鉴了NumPy的编码风格。
pandas功能特性广泛,包含的函数类型也众多,数据结构有Series和DataFrame,函数类型有索引函数、汇总函数等
表格容器
Pandas的核心为两种数据结构:Series和DataFrame。
Pandas库的Series对象用来表示一维数据结构,跟数组类似。
DataFrame这种列表式数据结构跟工作表(最常见的Excel工作表)极为相似,其设计初衷是将Series的使用场景由一维扩展到多维。DataFrame是按一定顺序排列的多列数据组成,各列的数据类型可以有所不同(数值、字符串或布尔值等)。
pandas可以读取较多类型的文件格式,从简单的txt、csv、json到excel,hdf5、pickle再到sas、sql、stata等等文件格式都有得以支持。
至于pandas与数据库交互,它可以通过特定的第三方包实现将SQL Server、 PostgreSQL和MySQL数据库中的数据加载到DataFrame中,然后进行各种处理分析。
pandas自带的绘图函数较为简陋,只有简单的plot函数,不过Series或者DataFrame格式的数据可以与matplotlib以及seaborn等绘图工具结合以绘制各类精致的图例。
第三方包datetime与dateutil能够将识别与处理多种时间格式,pandas自身可以生成指定频率的DatetimeIndex,也可以处理时区信息。其移动窗口函数则是大大方便了时间序列分析,使得建立各种AR、MA、ARMA、ARIMA等等时间序列模型方便快捷,而这正是R语言的领地。
pandas与NumPy比较
NumPy除了在相当程度上优化了Python计算过程,其自身还有较多的高级特性,如指定数组存储的行优先或者列优先、广播功能从而快速的对不同形状的矩阵进行计算、ufunc类型的函数可以使得我们丢开循环而编写出更为简洁也更有效率的代码、使用开源项目Numba编写快速的NumPy函数,而Numba则是可以利用GPU进行运算的。
虽然NumPy有着以上的种种出色的特性,其本身则难以独支数据分析这座大厦,这是一方面是由于NumPy几乎仅专注于数组处理,另一方面则是数据分析牵涉到的数据特性众多,需要处理各种表格和混杂数据,远非纯粹的数组(NumPy)方便解决的,而这就是pandas发力的地方。
pandas 这个名称来源于panel data(面板数据),从而可见其要处理的数据是多维度的而非单维度。pandas 含有使数据清洗和分析工作变得更快更简单的数据结构与操作工具。经常是和其他工具一起使用,如数值计算工具NumPy和SciPy,分析库statsmodels与scikit-learn,以及数据可视化库matplotlib。其中NumPy则是构建pandas的基础,后者大量借鉴了NumPy编码风格。
pandas功能特性广泛,其包含的函数类型也众多,数据结构有Series与DataFrame,函数类型有索引函数、汇总函数、加载以及保存众多文件格式函数、与数据库交互函数、字符串处理函数、缺失数据处理函数、合并重塑轴向旋转表格型数据函数、简单的绘图函数、数据聚合(groupby)分组运算(apply)函数、透视表交叉表函数以及时间序列处理方面的各种函数。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!