【大厂面试】之 美团(一面经含答案)
美团
一面
-
tcp三次握手,四次挥手。time-wait、close-wait状态。MSL代表什么?为什么time-wait是2MSL,可不可以更长?如果不设置time-wait有什么影响
- time-wait是主动关闭方的一个状态;close-wait是被动关闭方的一个状态。
- a FIN b(第一次挥手),b ACK a(第二次挥手,此时主动关闭方->被动关闭方连接断开),同时b向上层应用报备关闭连接,上层应用准备好后,b进入close-wait状态,此时 b FIN a(第三次挥手),a接收到FIN后进入time-wait状态,但a无法确定自己接下来的ack是否被b收到,所以time_wait还是会持续2MSL。下来会有两种情况:
- b接收a发送的ACK(第四次挥手,被动方->主动方连接断开)
- b没有接收到ACK,此时b在此发送FIN给a,a接收到后重新方ACK
- MSL(Maximum Segment Lifetime,最长报文段寿命)是指任何报文在网络上存在的最长的最长时间,超过这个时间报文将被丢弃。1MSL=2min
- time-wait是2MSL主要是为了保证客户端发送的最后一个ACK能够到达服务器。是2MSL的原因是服务器发客户端一个FIN需要等MSL,客户端在发给服务器一个ACK也需要一个MSL,一共需要2个MSL。更长不利于网络的传输,因为开启通道会占用服务器的资源,如线程会进入阻塞。
- 不设置time-wait,若客户端最后一个ACK丢失,此时服务器到客户端之间的连接无法断开。
-
TCP如何保证可靠性传输?ARQ重传什么时候会重传?超时计时器时间如何设置?(其实就是问拥塞控制)?TCP如何进行快速重传
- 三次握手、四次挥手、分包编号、校验和、去重、流控、拥塞控制、ARQ重传。
- 当发送发发出一个数据包时,超时计时器开始计时,若到0,还没有收到接收端发来的ACK会重传。
- 超时计时器时间是根据发端和收端的情况(如距离)动态变化的。
- 拥塞控制:当网络状态不好时,减少数据的发送。拥塞控制其实就是TCP丢包的情况。即由接收窗口来控制发送窗口的传输效率。拥塞控制算法有:慢开始、拥塞避免、快速重传与恢复。
- 慢开始:慢开始的思想是一开始不知道网络的状况,不能一下子发送大量数据包到网络,可能会引起网络阻塞。慢开始是由小到大逐渐增大发送窗口,也就是从小到大增加拥塞窗口的数值。cwnd初值为1,每经过一轮,cwnd加倍。
- 拥塞避免:让拥塞窗口缓慢增大,每经过一个往返时间RTT(即数据发送时刻到接收到确认的时刻的差值),就把发送放的cwnd加1
- 快速重传与恢复(FRR):在TCP/IP协议中,FRR是拥塞控制算法,能够快速恢复丢失的数据包。若没有FRR,数据包丢失了,TCP只能根据超时定时器来进行重传。若有FRR,如果接收方接收到一个不按顺序的数据段,它会立即给发送方发送一个重复确认。如果发送方接收到三个重复确认,它会假定确认件指出的数据段丢失了,并立即重传这些丢失的数据段。当有单独的数据包丢失时,FRR能最有效地工作。当有多个数据信息包在某一段很短的时间内丢失时,它则不能很有效地工作。
-
HTTP为什么是无状态协议?Cookie和Session?Session保存在哪里?Session共享?
-
如何判断对象是否死亡?引用计数器有什么缺点?可达性分析算法能否解决A引用B,B引用A的情况(循环引用)?什么适合做GC Roots?
-
使用引用计数器,若出现A引用B,B引用A的情景,A、B对象永远不会被回收。
-
使用可达性分析算法,若出现A引用B,B引用A的情景,C是可达的,此时AB间存在关系,但是是不可达的。可以回收

-
适合做GC Roots的对象(两栈两方法)
- 虚拟机栈中引?的对象
- 本地?法栈中引?的对象
- ?法区中类静态变量引?的对象
- ?法区中常量引?的对象
-
-
强引用、弱引用、软引用、虚引用?
-
ThreadLocal?
-
线程的生命周期?(Block、Time waiting状态的区别)
- NEW:新建状态。创建线程的方式:Thread类、Runnable接口、Callable接口、线程池
- RUNABLE:运行状态。java线程的Runnable状态包含了就绪态Ready和运行态Running
- WAITING:等待状态。由wait()和join()方法进入WAITING状态。需要由其它线程通知notify()来进入RUNABLE态
- TIME-WAITING:超时等待态。由sleep(long)、wait(long)、join(long)进入,即设置了等待时间,不需要其它线程通知,时间到了后自动进入RUNABLE态
- BLOCKED:阻塞状态。多线程执行同步方法,没有获取到锁的线程进入BLOCKED态,获取到了锁后进入RUNABLE态
- TERMINATED:终止态。线程死亡
-
可重入锁和不可重入锁的区别?synchronized是可重入锁?一个线程是否可以重复获取一个锁?
-
不可重入锁:同一个线程只能获取一次该资源的锁
public class Lock{ private boolean isLocked = false; public synchronized void lock() throws InterruptedException{ //不可重入锁只用判断当前锁的状态,如果是true表示锁已被获取,就进入WAITING态 while(isLocked){ wait(); } isLocked = true; } //不可重入锁解锁只用将标记设置为false,然后通知其它WAITING线程 public synchronized void unlock(){ isLocked = false; notify(); } } -
可重入锁:同一个线程可以多次获取同一个资源的锁。可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
public class Lock{ boolean isLocked = false; Thread lockedBy = null; int lockedCount = 0; public synchronized void lock() throws InterruptedException{ Thread thread = Thread.currentThread(); //可重入锁还要判断当前申请锁的线程是否是拥有锁的线程,如果不是,进入WAITING态,保证该资源的互斥条件 while(isLocked && lockedBy != thread){ wait(); } //如果 获取锁的线程就是当前申请锁的线程,该线程在此获取该资源的锁,计数器++ isLocked = true; lockedCount++; lockedBy = thread; } //可重入锁解锁:只有当前线程是拥有锁的线程,让锁计数器--,如果锁计数器为0表示锁没有被任何线程占有,将其状态更新并通知其它WAITING线程 public synchronized void unlock(){ if(Thread.currentThread() == this.lockedBy){ lockedCount--; if(lockedCount == 0){ isLocked = false; notify(); } } } } -
如调用A方法需要获取资源1的锁,A中调用B方法,B中也要获取资源1的锁。若是不可重入锁,会发生死锁;若是可重入锁,A、B方法是同一个线程调用,该线程获取重复获取资源1的锁,会判断申请该锁的线程是否是拥有该锁的线程,如果是,可以获取锁,LockCount++。可重入强调对单个线程执行时重新进入同一个子程序仍然是安全的。
public class Test{ Lock lock = new Lock(); public void methodA(){ lock.lock(); ...........; methodB(); ...........; lock.unlock(); } public void methodB(){ lock.lock(); ...........; lock.unlock(); } } -
synchronized是可重入锁(递归锁)。即synchronized方法递归调用不会发生死锁,说明其是可重入锁
public class Main{ public static void main(String[] args) throws CloneNotSupportedException { Main m = new Main(); m.main1(); } public synchronized void main1(){ System.out.println("main1 exec..."); main2(); } private synchronized void main2() { System.out.println("main2 exec..."); main3(); } private synchronized void main3() { System.out.println("main3 exec..."); } } //不会死锁,说明synchronized是可重入锁 main1 exec... main2 exec... main3 exec...
-
-
悲观锁和乐观锁?CAS?ABA问题如何解决?
- CAS(CompareAndSwap):A、V、B,A是旧值,V是地址,B是新值。只有A==B时,才会跳出死循环。
- ABA:一个线程把数据A变成了B,然后又重新变成了A,此时另一个线程读取该数据的时候,发现A没有变化,就误认为是原来的那个A,但是此时A的一些属性或状态已经发生过变化。
- 解决ABA用AtomicStampedReference类进行版本号控制。
-
线程池的7个参数?饱和策略?线程池原理?是否可以先创建线程再添加到工作队列中?
- 线程池原理:
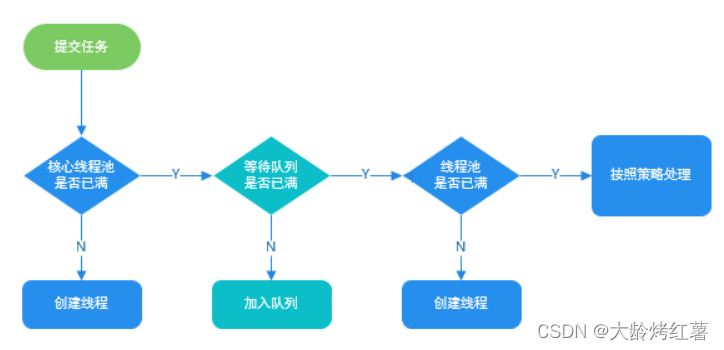
- 不可以先创建线程,再加入队列。这是因为创建线程所需资源比加入队列要大。从系统开销思考。
-
重量级锁是否一定比轻量级锁耗费资源?
- 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态与内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
- 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
-
MySQL索引的数据结构?b+索引的时间复杂度?
- b+索引是通过二分查找的,它的时间复杂度是b+树的高度。
-
事务并发存在的问题?事务的隔离级别?
-
当前读和快照读的区别?MVCC是如何实现读已提交和可重复读的?
-
组合索引?select * from T where a = 1 and b < 10 and c = 2;走那些索引?
- 为何要使用组合索引呢
- 效率高,减少查询开销,索引列越多,通过索引筛选出的数据越少
- 覆盖索引,MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操
index(a,b,c) where a=3 只使用了a where a=3 and b=5 使用了a,b where a=3 and b=5 and c=4 使用了a,b,c where b=3 or where c=4 没有使用索引 where a=3 and c=4 仅使用了a where a=3 and b>10 and c=7 使用了a,b。这是因为走a索引后,查出来的b是有序的,b也会走索引,而b是范围查找,查出来的c是无序的不走索引 where a=3 and b like 'xx%' and c=7 使用了a,b - 为何要使用组合索引呢
-
场景:在海量数据中如何精确匹配到某个值?
- 布隆过滤器。bitmap
-
如何在1万个数据中找到最大的top999?
- 堆排序,堆中元素只有100个,建小顶堆,堆顶元素最小,每来一个值与顶堆元素比较,如果比他小,那么肯定是top999里的。 - 求最大topK建小顶堆,反之,求最小topK建大顶堆 - 堆中元素个数为K - 如在1万个数据中找到最大的top999,从10000个数中任取999个建小顶堆,此时堆顶元素是最小的。然后遍历10000个数剩余元素,每一个元素与堆顶元素进行比较,若比堆顶元素大,将堆顶元素置为该值`arr[0] = nums[k]`,然后`heapify(arr, n, 0),此时的结果是将可能是top999中的数放到堆中`;若比堆顶元素小,遍历下一个元素,直到nums遍历结束。此时堆中元素就是topK -
算法:连续子数组的最大和
-
反问:工作业务与技术栈
- 业务:B端和C端
- 技术栈:微服务,分布式,springboot
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!