服务案例|CIS数据库故障问题
一、告警通知
12月20日凌晨,平台收到某三甲医院告警通知,显示核心业务CIS系统数据库tempdb实例日志文件剩余空间不足。

查看告警详情页,显示tempbd日志文件使用率在凌晨1:30后异常增高。

一个小tip
tempdb是SQL Server实例的系统数据库,同时也是实例中的一个临时共享资源。当服务器重启,Tempdb将被重建,所以Tempdb是没有办法像其他数据库一样永久保存数据的。也就是说,Tempdb是一个临时的数据库,是为实例中的各种请求处理中间数据的,任务处理完会自动释放,不会占用内存。
二、问题处理
MOC通知现场工程师,告知SQL server的tempdb实例日志文件异常增长,使用率已达99%,即将满,可能会导致临时表无法创建或数据事务无法提交,需要联系数据工程师处理。
由于是tempdb日志文件问题,未引起数据工程师足够重视,并未及时处理,告警问题一直持续。
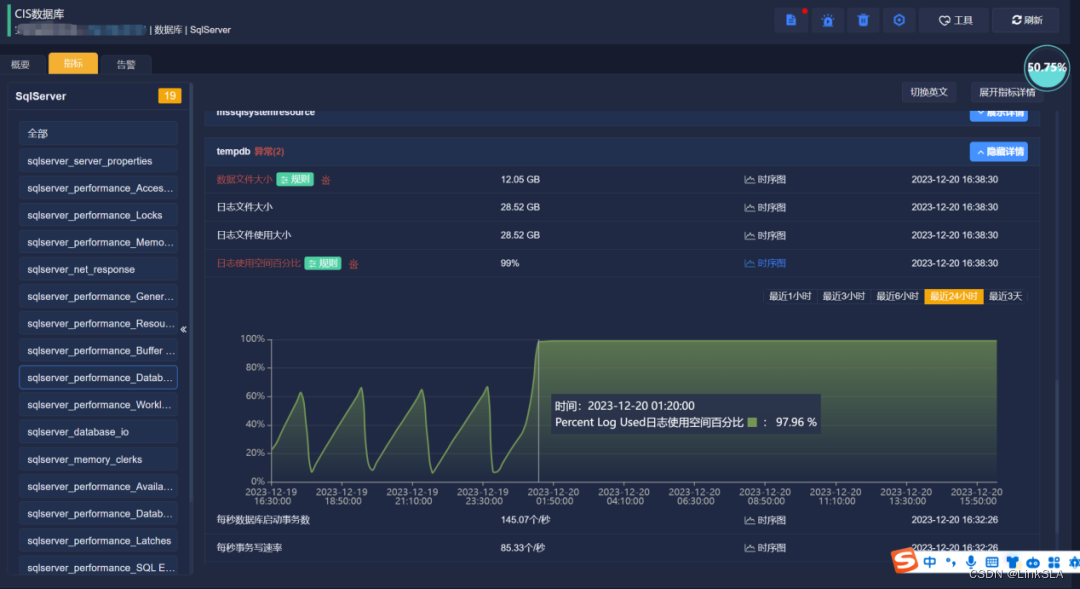
问题持续到下午16:30分,临近工程师下班点,MOC工程师观察到数据库服务器C盘数据量与tempdb的日志文件大小同步增加,tempdb的日志文件从0增长到28.52G, 无独有偶,服务器C盘可用空间从45G下降至12G。Tempdb的日志文件大小仍在增加,按照增长趋势估算,将在夜间23-24点,CIS服务器的C盘空间会满,可能会导致CIS系统瘫痪。CIS系统是医院的核心系统,一旦发生宕机现象,将造成难以估量的损失。
简言之,同步增长的数据将导致C盘爆满,以此趋势看,不出意外将在夜间凌晨发生宕机事件。


MOC沟通用户工程师,建议在下班前处理不断增长的tempdb日志文件数据。不是夜间宕机解决不了,而是现在处理更有性价比。
数据工程师得知夜间C盘将爆满,可能引发宕机事件,马上进行处理,停止了SQL server正在进行的作业任务,将tempdb日志文件大小进行收缩,释放C盘空间,告警问题解决。
三、问题小结
tempdb是一个临时的数据库,为实例中的各种请求处理中间数据。一般在任务处理完成后会自动释放,所以平台告警通知数据工程师后,并未引起足够重视。LinkSLA在线工程师持续跟进问题,发现tempdp日志文件数据持续不断增长,导致操作系统磁盘空间不足,在平台趋势测算下,夜间将会引发CIS系统瘫痪。
所谓善战者,无赫赫之功,运维就是如此,不担大风险,积小胜为大胜。在细节处着手,于萌芽处扼杀,不因低级别事件就不重视,小问题拖延或聚集,也会造成系统性宕机的大事件。
系统正常运行,是所有硬件资源在系统指令下协作完成,做到全面数据监控,实时自动巡检,能够及时地发现问题,积极响应问题,主动御防,精准解除。
LinkSLA管家式运维服务
LinkSLA智能运维管家不仅仅是工具,还实质性地参与用户主动式预防的运维过程。
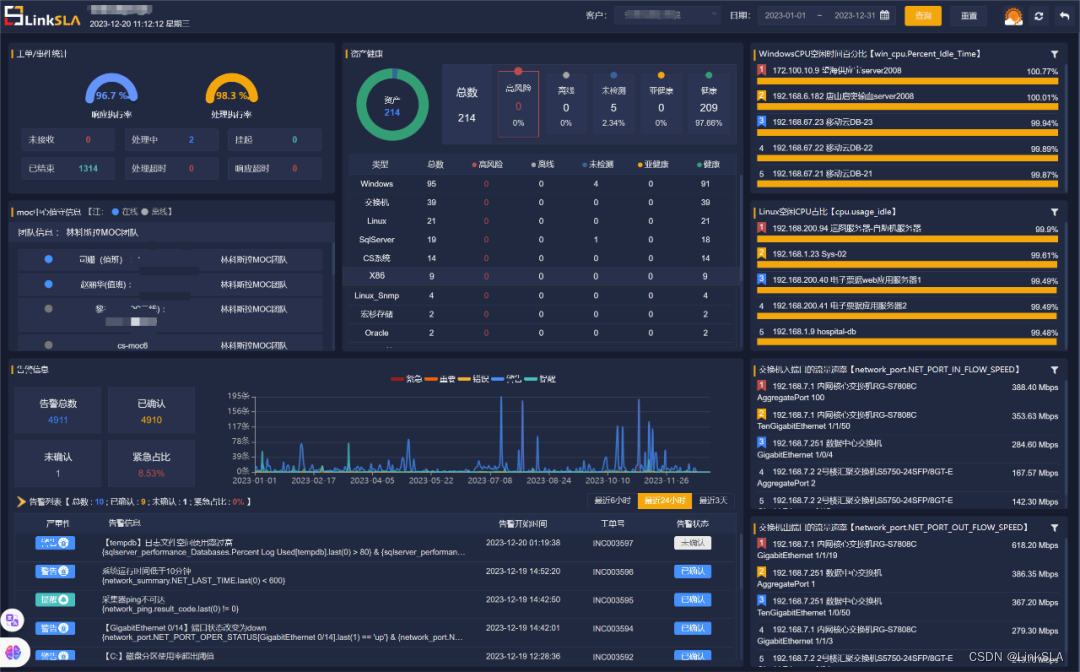
1、 7*24 在线值守
moc工程师实时在线监测平台告警信息,经过筛查和初步定位后生成工单通知用户工程师;工单处理闭环,既降低用户工程师的工作量,也过滤了无效告警和工单。

▲7*24在线,工单闭环
2、全栈监控
实现设备、系统软件、应用软件、安全日志的统一监控。
▲全栈监控
3、机器学习算法,实现精准告警。
区别于传统静态阈值的告警算法,机器学习算法经过历史数据训练,发现业务运行常态中的异常,大大提高告警准确性。
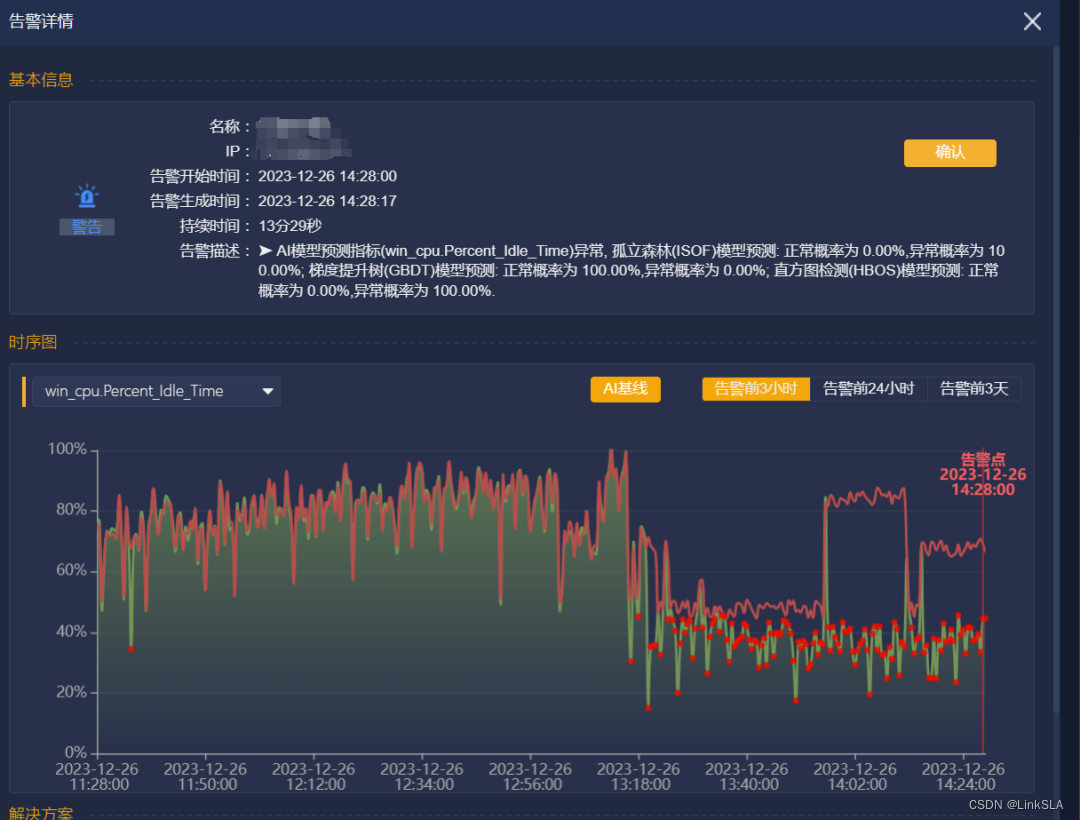
▲AI机器学习算法告警详情
4、实时巡检,精准探测系统实时状态。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!