[书生·浦语大模型实战营]——XTuner 大模型单卡低成本微调
1.Finetune简介
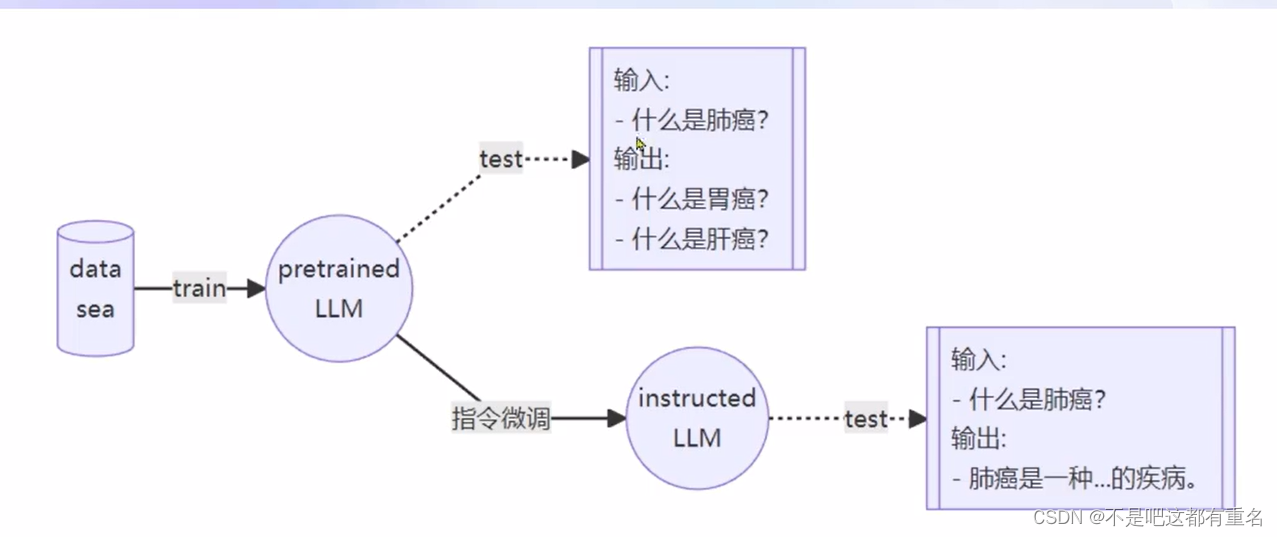
在未经过微调的pretrained LLM中,模型只会尽量去拟合你的输入,也就是说模型并没有意识到你在提问,因此需要微调来修正。
1.1常用的微调模式
LLM的下游应用中,增量预训练和指令跟随是经常会用到的两种的微调模式。
增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
训练数据:文章、书籍、代码等
指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话
训练数据:高质量的对话、问答数据
1.2具体实现
指令跟随微调
指令跟随微调是为了得到能够实际对话的LLM。介绍指令跟随微调前,需要先了解如何使用LLM进行对话。
在实际对话时,通常会有三种角色
System:给定一些上下文信息,比如“你是一个安全的AI助手"
User:实际用户,会提出一些问题,比如“世界第一高峰是?”
Assistant:根据 User 的输入,结合 System 的上下文信息,做出回答,比如“珠穆朗玛峰”
与增量预训练的区别在于,数据中会有Input和Ouput,希望模型学会的是答案(Output),而不是问题(Input),训练时只会对答案(Output)部分计算Loss。
增量预训练微调
输入的数据形式并不是问答的形式,而是只是陈述句。因此实际的模板如下:
System:“”
User:“”
Assistant:根据 User 的输入,结合 System 的上下文信息,做出回答,比如“珠穆朗玛峰”
1.3LoRA&QLoRA
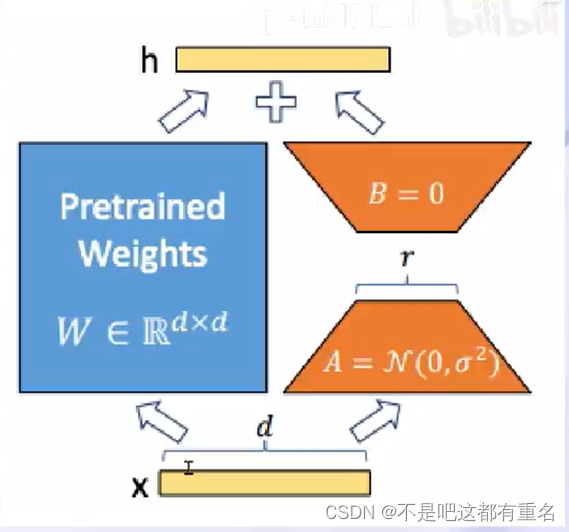
LoRA:LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
LLM的参数量主要集中在模型中的Linear中,训练这些参数会消耗大量显存。而LoRA通过在原本的Linear旁,新增一个支路,包含两个连续的小Linear,新增的这个支路通常叫做Adapter。而这个Adapter的参数量远远小于原本的Linear中的参数量,可以 大幅度降低训练的显存消耗。
QLoRA是LoRA的一种改进方法。

2.XTuner介绍
2.1 XTuner 简介
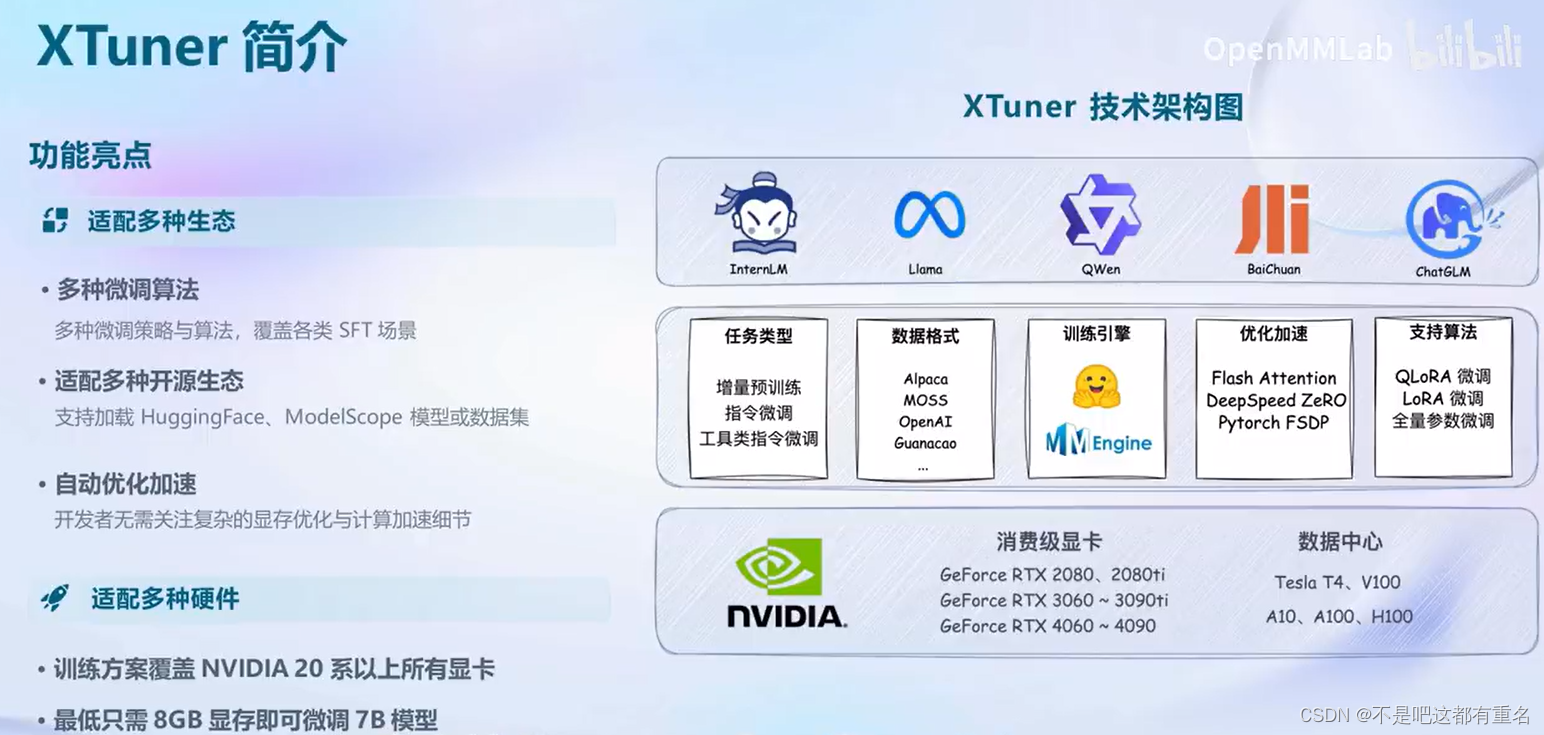
2.2 XTuner快速上手
1.安装
pip install xtuner
2.挑选配置模板
xtuner list-cfg -p internlm_20b
3.一键训练
xtuner trian interlm_20b_qlora_oasst1_512_e3
Config的命名规则:
 4.模型对话
4.模型对话
Float 16模型对话
xtuner chat internlm/internlm-chat-20b
或4bit模型对话
xtuner chat internlm/internlm-chat-20b --bits 4
加载Adapter模型对话
xtuner chat internlm/internlm-chat-20b --adapater $ADAPATER_DIR
5.工具类模型对话
XTuner还支持工具类模型的对话。
2.3 XTuner数据引擎
2.3.1 数据处理流程

同时支持多种热门数据集的映射函数和多种对话模板映射函数。使得开发者可以专注于数据内容,而不必花费精力处理复杂的数据格式。
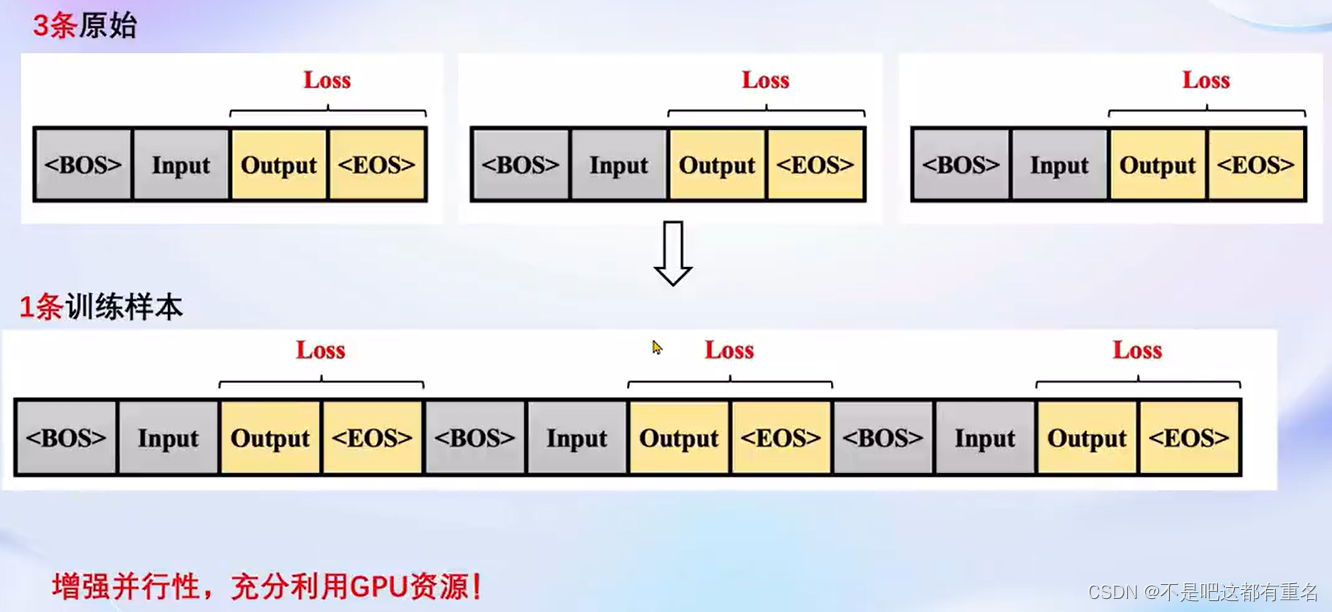
2.3.2 多数据样本拼接(Pack 0Dataset)
3.8GB显卡玩转LLM
3.1特色功能
下面提到的两个技巧都是XTuner中重要的两个优化技巧。
3.1.1 Flash Attention(默认开启)
Flash Attention 将Attention 计算并行化,避免了计算过程中Attention Score NxN的显存占用。
3.1.2 DeepSpeed ZeRO(非默认)
ZeRO优化,通过将训练过程中的参数、梯度和优化器状态切片保存,能够在多GPU训练时显著节省显存。除了将训练中间状态切片外, DeepSpeed训练时使用FP16的权重,相较于Pytorch的AMP(自动混合精度) 训练,在单 GPU 上也能大幅节省显存
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp使用u-search以及相关api
- 宝塔面板Linux服务器CentOS 7数据库mysql5.6升级至5.7版本教程
- 【C语言 | 指针】函数指针详解
- AcWing算法提高课-2.3.1矩阵距离
- WinSW使用-将jar包包装成windows服务
- 【教学类-42-03】20231225 X-Y 之间加法题判断题3.0(确保错误题有绝对错误的答案)
- sql server多表查询
- 前端进阶-可视化(echarts)
- 【华为机试】2023年真题B卷(python)-服务启动
- TiDB存储引擎的初步认识