undo日志的理解
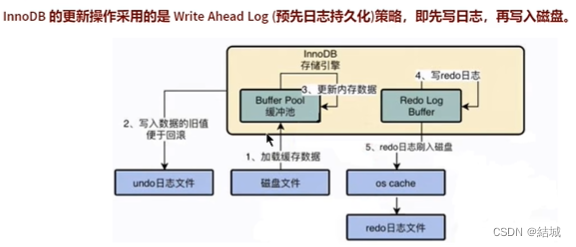
对比redo日志是持久性的保证,undo日志保障的是事物的原子性。
事务在更新数据之前要先写一个undo_log
事务需要保证原子性,也就是事务中的操作要么全部完成,要么什么也不做。但有时候事务执行到一半会出现一些情况,比如:
●情况一:事务执行过程中可能遇到各种错误,比如服务器本身的错误,操作系统错误,甚至是突然断电导致的错误。
●情况二:程序员可以在事务执行过程中手动输入ROLLBACK语句结束当前事务的执行。
以上情况出现,我们需要把数据改回原先的样子,这个过程称之为回滚,这样就可以造成一个假象:这个事务看起来什么都没做,所以符合原子性要求。
每当我们要对一条记录做改动时(这里的改动可以指INSERT. DELETE. UPDATE) ,都需要"留一手"–把回滚时所需的东西记下来。比如:
●你插入一条记录时,至少要把这条记录的主键值记下来,之后回滚的时候只需要把这个主键值对应的记录刚掉就好了。(对于每个INSERT, InnoDB存储引擎会完成-个DELETE)
●你删除了一条记录,至少要把这条记录中的内容都记下来,这样之后回滚时再把由这些内容组成的记录插入到表中就好了,(对于每个DELETE, InnoDB存储引擎 会执行一个INSERT)
●你修改了一条记录,至少要把修改这条记录前的旧值都记录下来,这样之后回滚时再把这条记录更新为旧值就好了。(对于每个UPDATE, InnoDB存储引擎会执行一个相反的UPDATE, 将修改前的行放回去)
MySQL把这些为了回滚而记录的这些内容称之为撒销日志或者回滚日志(即undo_log) .注意,由于查询操作(SELECT)并不会修改任何用户记录,所以在查询操作执行时,并不需要记录相应的undo日志。
此外,undo log会产生redo log ,也就是undo log的产生会伴随着redo log的产生,这是因为undo log也需要持久性的保护。
那undo log作用是啥?
回滚数据
用户对undo日志可能有误解: undo用于将数据库物理地恢复到执行语句或事务之前的样子。但事实并非如此。undo是逻辑日志,因此只是将数据库逻辑地恢复到原来的样子。所有修改都被逻辑地取消了,但是数据结构和页本身在回滚之后可能大不相同。
这是因为在多用户并发系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要任务就是协调对数据记录的并发访问。比如,一个事务在修改当前一个页中某几条记录,同时还有别的事务在对同一个页中另几条记录进行修改。因此,不能将一个页回滚到事务开始的样子,因为这样会影响其他事务正在进行的工作。
MVCC
undo的另一个作用是MVCC,即在InnoDB存储引擎中MVCC的实现是通过undo来完成。 当用户读取一行记录时,若该记录已经被其他事务占用,当前事务可以通过undo读取之前的行版本信息,以此实现非锁定读取。
执行情况
start transaction;
记录A = 1到undo 1og;
update A = 3:
记录A = 3到redo 1og:
记录B = 2到undo 1og:
update B = 4:
记录B = 4到redo 1og:
将redo 1og刷新到磁盘
commit
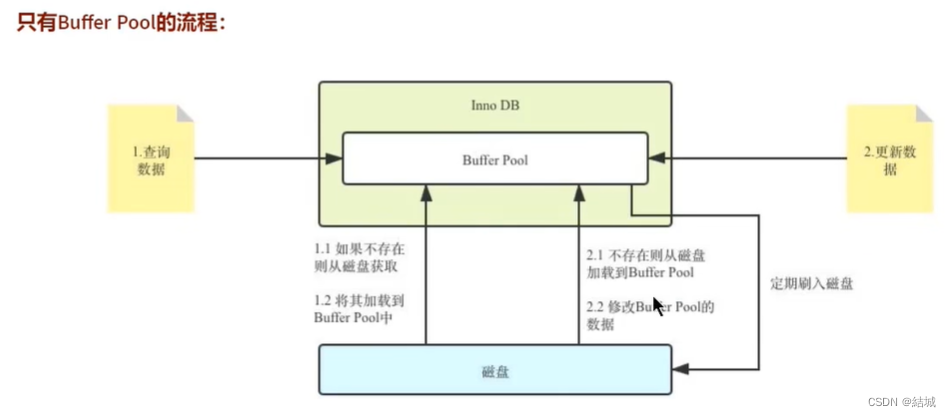
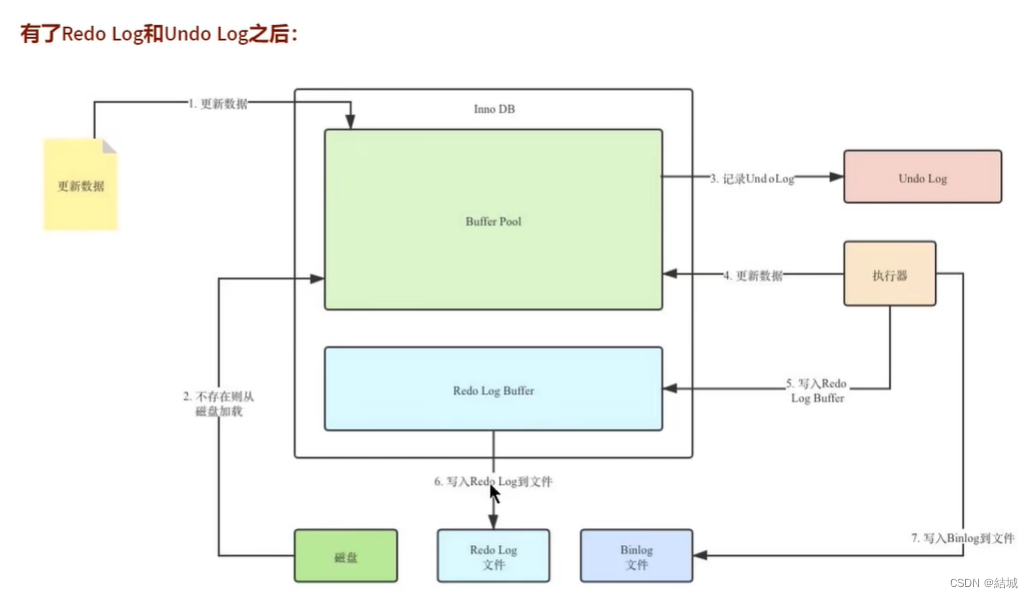
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 蓝牙BLE基础知识
- 科技感十足界面模板
- 找不到xinput1_3.dll怎么办呢?找不到xinput1_3.dll的5种不同修复方法
- 一文2500字Robot Framework自动化测试框架超强教程
- Java经典框架之Shiro
- 做跨境电商,为什么要建独立站,2024年的机会在哪里?一次性讲清楚...
- 绿色制造的行业标杆OEKO-TEX STeP认证
- 渗透测试 | 信息收集常用方法总结
- 122. 买卖股票的最佳时机 II - 力扣(LeetCode)
- 建一个外贸网站一年大概需要多少钱?