kubeadm方式重置k8s集群
发布时间:2023年12月20日
以kubeadm方式部署的k8s,当出现问题,排查解决的难度会非常大,如果是实验环境,直接进行集群重置即可,如果是生产环境,如果集群已经崩掉了,而且短时间时间内无法定位原因的情况的下,建议先备份好ETCD的数据,然后对生产k8s集群进行重置,以期业务能快速恢复。
1.执行重置
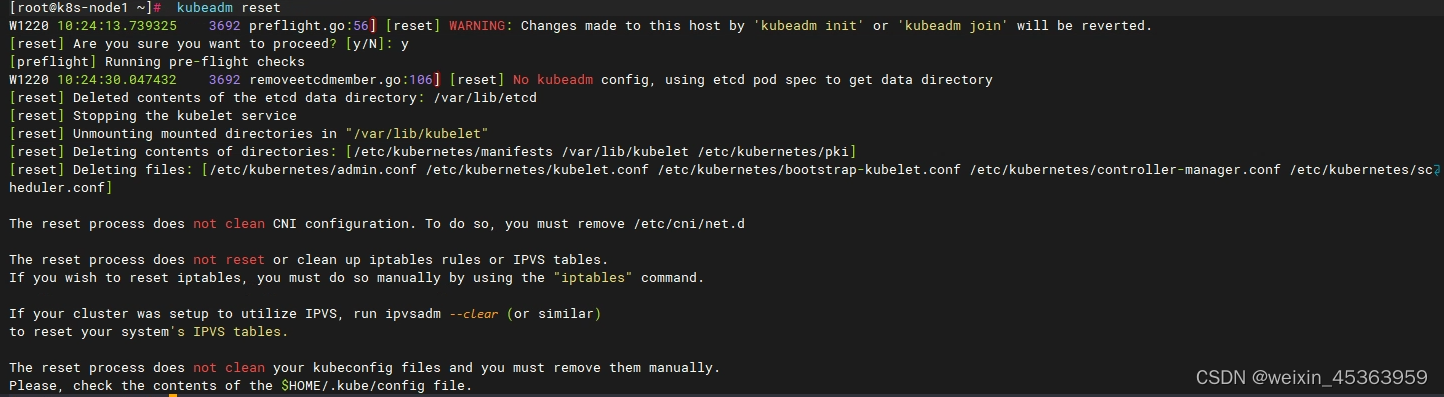
在每台节点机器上执行 kubeadm reset
kubeadm reset
2.删除$HOME/.kube
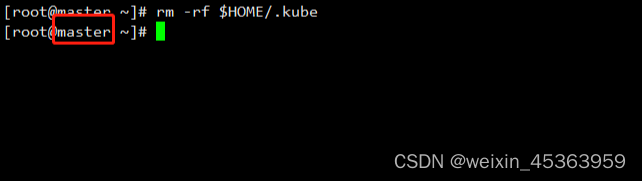
在master节点上执行 rm -rf $HOME/.kube命令
rm -rf $HOME/.kube
3.集群初始化
只需要在master节点上执行即可
kubeadm init --kubernetes-version=1.28.0 --apiserver-advertise-address=192.168.1.200 --pod-network-cidr=10.244.0.0/16 --image-repository registry.aliyuncs.com/google_containers
4.创建必要文件
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
5.把Node节点加入集群
kubeadm join 192.168.1.200:6443 --token cexxct.pvvfy19t7w59w85j \
--discovery-token-ca-cert-hash sha256:3013aff45d18317bf5e533c6b727d3cfe2ab3bedf5b14ff668d8d878d45d9f2c
在每台node节点上分别执行,记得把token 和 discovery-token-ca-cert-hash 换成自己的,如果是生产集群,把备份的edct数据拷贝到重置后etcd对应的文件夹中。
文章来源:https://blog.csdn.net/weixin_45363959/article/details/135101486
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 特征工程 -- 数据分桶
- UnityRenderStreaming使用记录(一)
- 计算天数[2]
- C#/.NET/.NET Core推荐学习书籍(23年12月更新)
- 前端国际化之痛点(一):让人头疼的词条Key
- 低代码,前端工程化项目的未来
- Node.JS校园新闻管理系统 计算机专业毕业设计源码19282
- linux 云课堂笔记day2
- Python遍历读取 A 文件夹中的 A1、A2、A3、A4、A5 中的各子文件夹中的图片,并对每张图片处理后保存到指定路径
- css3基础语法与盒模型