本地缓存:Caffeine入门使用
概况
回顾互联网应用发展史,可以发现一个通用并且普遍存在的一个工作过程。如下图所示,用户从浏览器发出请求 -> 网络转发请求 -> 应用服务业务处理 -> 底层存储信息获取,然后逆向的返回用户,形成页面给予用户相应信息。

优秀的互联网应用随着业务的普及范围的扩大,用户和用户发出的请求也在与日俱增。这时候就会出现系统瓶颈
- 如果是计算型服务应用,那么对于服务器的计算能力是一个考验
- 如果是IO型的服务应用,那么频繁的从文件系统,数据库等磁盘文件中获取信息会有比较大的延时和压力
由于服务资源是建立在成本上的,自然服务资源是有限的,所以需要使用有限的服务资源去支撑日益增长的业务场景
业内很常见的方式是引入缓存,将计算结果,从磁盘文件中读取的信息存储在缓存中,那么获取数据时就无需从数据存储层获得或者重新计算获得。减少应用服务器的压力,也就是通过减少磁盘读取、数据计算等方式来快速获取所需结果,提高相应速度。
简介
Caffeine是一款基于jdk8实现的缓存工具,在设计上参考了google的Guava cach组件,可以理解为是一个Guava Cache的加强版本,性能也是在其基础上有了提升。
Caffeine cache的作者是Ben manes,可以通过他的github:github.com/ben-manes来查看组件的源码 ,并且他还编写了ConcurrentLinkedHashMap工具类,也被用于缓存的底层数据结构,这个类就是Guava cache的基础。我们知道Guava cache是基于LRU算法实现的一种缓存工具,LRU算法的缺点是短暂持续性冷数据流量会导致热数据的淘汰,造成数据的污染。而Caffeine cache采用了在LRU基础上的W-TinyLFU算法实现,有比较好的命中率。
优点
Caffeine淘汰算法:使用基于W-TinyLFU算法,实现几乎完美的命中率;
- FIFO:实现简单,类似于队列,先进先出,因此缓存命中率不是很高。
- LRU:最近最久未使用算法(Least Recently Used)如果一个数据在一段时间内没有被访问,那么我们认为后面被访问的概率也很小。当我们添加新数据的时候,会把新数据放到队尾(假设新数据最大概率被再次访问),当我们长度到达阈值需要淘汰数据的时候,会从队首进行淘汰。这种算法造成缓存污染的概率会大些,比如现在有一些较少数据突增流量,但是后面不在访问,那么此时已经将热数据淘汰出去了,而缓存的数据后面也几乎不被访问。
- LFU:最近最少使用算法(Least Frequently Used)如果一个数据在一段时间内访问的频率很小,那么认为后面被访问的几率也很小,所以淘汰访问频率最少的数据;该算法可以处理LRU因为冷数据突增带来的缓存污染问题。存在的问题是数据访问模式如果改变,这种算法命中率会下降,并且需要额外的空间存储信息频率。
- W-TinyLFU:记录了近期访问记录的频率信息,不满足的记录不会进入到缓存。使用Count-Min Sketch算法记录访问记录的频率信息。依靠衰减操作,来尽可能的支持数据访问模式的变化。
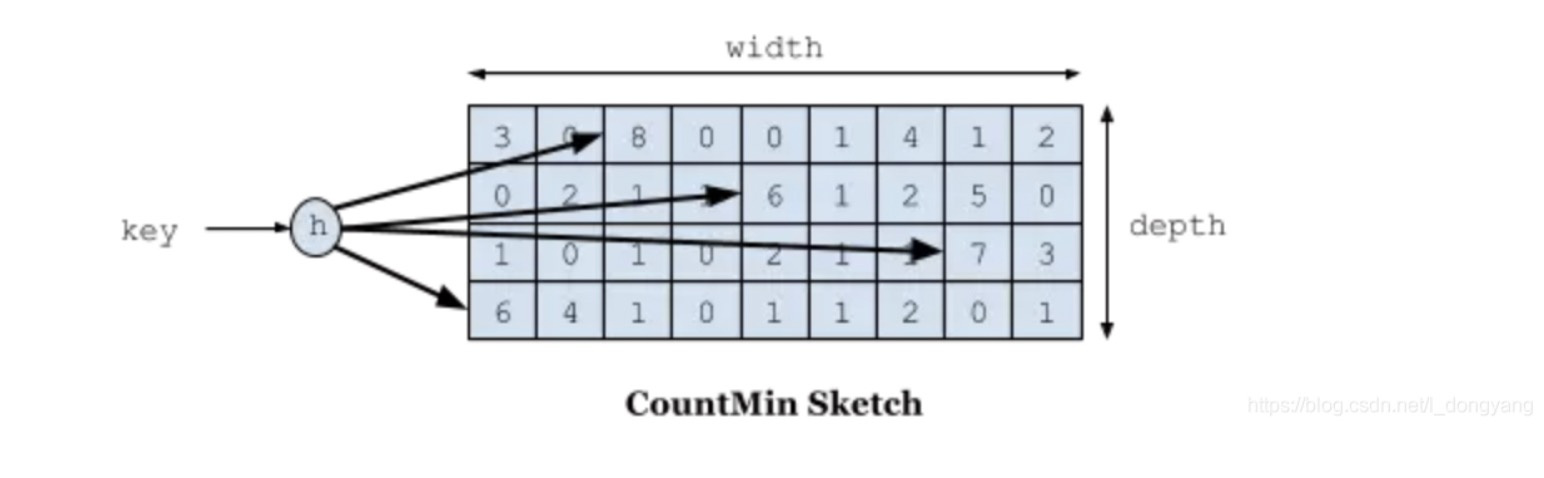
?
适用场景
因为Caffeine cache是类似于Guava cache的一种内存缓存,所以适合单机的数据缓存;因为存储在内存的,没有持久化,因此适合一些短期或者启动以及结果信息的短暂缓存。当涉及到多机多服务的缓存时候,属于分布式缓存的范畴,可以使用Redis、memcached等分布式的缓存组件。
基础使用
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.0.3</version>
</dependency>缓存填充策略
缓存的填充方式在使用形式看有三种,手动、同步和异步,从返回对象类别看,可以看做为4种,下面分别简单介绍下每种方式使用的API:
手动填充
1.手动加载:手动控制缓存的增删改处理,主动增加、获取以及依据函数式更新缓存;底层使用ConcurrentHashMap进行节点存储,因此get()方法是安全的。批量查找可以使用getAllPresent()方法或者带填充默认值的getAll()方法。
/**
* 手动填充测试
*/
public void cacheTest(String k) {
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.build();
//手动添加缓存值
cache.put("c1", "c1");
//-- 测试缓存值是否存在
//获取缓存值,如果为空,返回null
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("cacheTest default: [{}] -> [{}]", k, cache.get(k, this::buildLoader));
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
//清除缓存
cache.invalidate(k);
log.info("cacheTest present: [{}] -> [{}]", k, cache.getIfPresent(k));
}
//从数据库查询需要添加到缓存的数据
private String buildLoader(String k) {
return k + "+default";
}自动填充
同步加载
同步加载:LoadingCache对象进行缓存的操作,使用CacheLoader进行缓存存储管理。批量查找可以使用getAll()方法。默认情况下,getAll()将会对缓存中没有值的key分别调用CacheLoader.load方法来构建缓存的值(build中的表达式)。我们可以重写CacheLoader.loadAll方法来提高getAll()的效率。
/**
* 同步填充测试
*/
public void loadingCacheTest(String k) {
//同步填充在build方法指定表达式
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.build(this::buildLoader);
loadingCache.put("c1", "c1");
log.info("loadingCacheTest get: [{}] -> [{}]", k, loadingCache.get(k));
//获取缓存值,如果为空,返回null
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("loadingCacheTest default: [{}] -> [{}]", k, loadingCache.get(k, this::buildLoader));
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
loadingCache.invalidate(k);
log.info("loadingCacheTest present: [{}] -> [{}]", k, loadingCache.getIfPresent(k));
}
//从数据库查询需要添加到缓存的数据
private String buildLoader(String k) {
return k + "+default";
}异步加载
自动异步加载
AsyncLoadingCache对象进行缓存管理,get()返回一个CompletableFuture对象,默认使用ForkJoinPool.commonPool()来执行异步线程,但是我们可以通过Caffeine.executor(Executor) 方法来替换线程池。
/**
* 异步填充测试
*/
public void asyncLoadingCacheTest(String k) throws ExecutionException, InterruptedException {
//异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
//
//如果要以异步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
AsyncLoadingCache<String, String> asyncLoadingCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.buildAsync(s -> this.buildLoaderAsync("123").get());
log.info("asyncLoadingCacheTest get: [{}] -> [{}]", k, asyncLoadingCache.get(k).get());
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("asyncLoadingCacheTest default: [{}] -> [{}]", k, asyncLoadingCache.get(k, this::buildLoader).get());
}
//异步从数据库查询需要添加到缓存的数据
private CompletableFuture<String> buildLoaderAsync(String k) {
return CompletableFuture.supplyAsync(() -> k + "+buildLoaderAsync");
}手动异步加载
/**
* 手动异步测试
*/
public void asyncManualCacheTest(String k) throws ExecutionException, InterruptedException {
//异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
//
//如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
AsyncCache<String, String> asyncCache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterAccess(100L, TimeUnit.SECONDS)
.buildAsync(); //不添加异步填充方法
//获取返回值,如果为空,则运行后面表达式,存入该缓存
log.info("asyncManualCacheTest default: [{}] -> [{}]", k, asyncCache.get(k, this::buildLoader).get());
}过期策略
Caffeine的缓存清除是惰性的,可能发生在读请求后或者写请求后,比如说有一条数据过期后,不会立即删除,可能在下一次读/写操作后触发删除(类比于redis的惰性删除)。如果读请求和写请求比较少,但想要尽快的删掉cache中过期的数据的话,可以通过增加定时器的方法,定时执行cache.cleanUp()方法(异步方法,可以等待执行),触发缓存清除操作。
基于缓存条目过期
1.基于大小过期:当缓存超出后,使用W-TinyLFU算法进行缓存淘汰处理
maximumSize()方法,参数是缓存中存储的最大缓存条目,当添加缓存时达到条目阈值后,将进行缓存淘汰操作
/**
* 淘汰策略-size
*/
public void sizeTest() {
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumSize(1)
.build(this::buildLoader);
List<String> list = Lists.newArrayList("c1", "c2", "c3");
//添加缓存数据 c1
loadingCache.put(list.get(0), list.get(0));
log.info("weightTest get: [{}] -> [{}]", list.get(0), loadingCache.get(list.get(0))); //c1 -> c1
//添加缓存数据 c2 , 并且达到最大缓存条目,所以把c1数据从缓存中淘汰
loadingCache.put(list.get(1), list.get(1));
log.info("weightTest get: [{}] -> [{}]", list.get(1), loadingCache.get(list.get(1))); //c2 -> c2
//添加缓存数据 c3 , 并且达到最大缓存条目,所以把c2数据从缓存中淘汰
loadingCache.put(list.get(2), list.get(2));
log.info("weightTest get: [{}] -> [{}]", list.get(2), loadingCache.get(list.get(2))); //c2 -> c2
log.info("weightTest cache map:{}", loadingCache.getAll(list));
//c2 -> c2
}基于权重过期(大小与权重 只能二选一)
weigher()方法可以指定缓存所占比重,maximumWeight()方法指定最大的权重阈值,当添加缓存超过规定权重后,进行数据淘汰
- 总权重其实是等于所有缓存的权重加起来
- 缓存淘汰是异步的
/**
* 淘汰策略-weight
*/
public void weightTest() {
LoadingCache<String, String> loadingCache = Caffeine.newBuilder()
.maximumWeight(10)
.weigher((key, value) -> 5)
.build(this::buildLoader);
List<String> list = Lists.newArrayList("c1", "c2", "c3");
loadingCache.put(list.get(0), list.get(0));
log.info("weightTest get: [{}] -> [{}]", list.get(0), loadingCache.get(list.get(0)));
loadingCache.put(list.get(1), list.get(1));
log.info("weightTest get: [{}] -> [{}]", list.get(1), loadingCache.get(list.get(1)));
log.info("weightTest cache map:{}", loadingCache.getAll(list));
}基于时间过期
- expireAfterAccess():缓存访问后,一定时间失效;即最后一次访问或者写入开始时计时。
-
- 每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰
- expireAfterWrite():缓存写入后,一定时间失效;以写入缓存操作为准计时。
-
- 每次访问都会重置时间,也就是说如果一直被访问就不会被淘汰
- expireAfter():自定义缓存策略,满足多样化的过期时间要求。
/**
* 淘汰策略-time
*/
public void timeTest() {
//1.缓存访问后,一定时间后失效
LoadingCache<String, String> loadingCacheOne = Caffeine.newBuilder()
.expireAfterAccess(10L, TimeUnit.SECONDS)
.build(this::buildLoader);
//2.缓存写入后,一定时间后失效
LoadingCache<String, String> loadingCacheTwo = Caffeine.newBuilder()
.expireAfterWrite(10L, TimeUnit.SECONDS)
.build(this::buildLoader);
//3.自定义过期策略
LoadingCache<String, String> loadingCacheThree = Caffeine.newBuilder()
.expireAfter(new Expiry<Object, Object>() {
@Override
public long expireAfterCreate(@NonNull Object o, @NonNull Object o2, long l) {
return 0;
}
@Override
public long expireAfterUpdate(@NonNull Object o, @NonNull Object o2, long l, @NonNegative long l1) {
return 0;
}
@Override
public long expireAfterRead(@NonNull Object o, @NonNull Object o2, long l, @NonNegative long l1) {
return 0;
}
})
.build(this::buildLoader);
}另外还有一个refreshAfterWrite()表示x秒后自动刷新缓存可以配合以上的策略使用
private static int NUM = 0;
@Test
public void refreshAfterWriteTest() throws InterruptedException {
LoadingCache<Integer, Integer> cache = Caffeine.newBuilder()
.refreshAfterWrite(1, TimeUnit.SECONDS)
//模拟获取数据,每次获取就自增1
.build(integer -> ++NUM);
//获取ID=1的值,由于缓存里还没有,所以会自动放入缓存
System.out.println(cache.get(1));// 1
// 延迟2秒后,理论上自动刷新缓存后取到的值是2
// 但其实不是,值还是1,因为refreshAfterWrite并不是设置了n秒后重新获取就会自动刷新
// 而是x秒后&&第二次调用getIfPresent的时候才会被动刷新
Thread.sleep(2000);
System.out.println(cache.getIfPresent(1));// 1
//此时才会刷新缓存,而第一次拿到的还是旧值
System.out.println(cache.getIfPresent(1));// 2
}
基于引用过期
| 引用名称 | 垃圾回收时机 | 用途 | 生存周期 |
| 强引用(Strong Reference) | 不回收 | 正常普遍的类别 | JVM停止运行 |
| 软引用(soft Reference) | 内存不足回收 | 缓存对象 | 内存不足时 |
| 弱引用(weak Reference) | 下一次GC回收 | 缓存对象 | GC之后 |
| 虚引用(Phantom Reference) | 随时回收,引用虚设 | 通知功能 | 随时回收 |
API使用方式
/**
* 淘汰策略-引用
*/
public void referenceTest() {
//1.弱引用弱key方式,没有强引用时,回收
LoadingCache<String, String> loadingCacheOne = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(this::buildLoader);
//2.软值引用,内存不足的时候回收
LoadingCache<String, String> loadingCacheTwo = Caffeine.newBuilder()
.softValues()
.build(this::buildLoader);
}最佳实践
在实际开发中如何配置淘汰策略最优呢,根据我的经验常用的还是以大小淘汰为主
实践1
配置:设置 maxSize、refreshAfterWrite,不设置 expireAfterWrite/expireAfterAccess
优缺点:因为设置refreshAfterWrite当缓存过期时会同步加锁获取缓存,所以设置refreshAfterWrite时性能较好,但是某些时候会取旧数据,适合允许取到旧数据的场景
实践2 配置:设置 maxSize、expireAfterWrite/expireAfterAccess,不设置 refreshAfterWrite
优缺点:与上面相反,数据一致性好,不会获取到旧数据,但是性能没那么好(对比起来),适合获取数据时不耗时的场景
手动删除
Caffeine中提供了手动进行缓存的删除,无需等待我们上面提到的被动的一些删除策略,使用方法如下:
cacheOne.invalidateAll();
cacheOne.invalidate(Object o);
cacheOne.invalidateAll(List);事件监听
移除事件RemovalListener是一种缓存监听事件,当key被移除的时候就会触发这个方法,可以进行一些相关联的操作。RemovalListener可以获取到key、value和RemovalCause(删除的原因)。另外RemovalListener中操作是线程池异步执行的。
/**
* 移除监听器
*/
public void removeTest() throws InterruptedException {
Cache<String, String> cacheOne = Caffeine.newBuilder()
.maximumSize(1)
.removalListener(
(o, o2, removalCause) ->
System.out.println(o + " is " + "remove" + " reason is " + removalCause.name()))
.build();
}外部存储
CacheWriter是实现Caffeine cache的实现外部资源操作的一种方式,所有缓存的读写可以通过CacheWriter进行传递,比如我们可以通过CacheWriter的实现方法进行第三方外部资源的操作。一方面这个组件可以代替上面提到的RemovalListener移除事件监听,不同之处在于这个是同步执行的,且是一个原子操作,写入缓存完成之前会阻塞后续更新缓存的操作,但是读缓存不会阻塞;另一方面,可以当作是维持和外部资源的一个纽带,进行外部资源关联使用。
/**
* writer
*/
public void writerTest() {
Cache<String, String> cacheOne = Caffeine.newBuilder()
.maximumSize(1)
.writer(new CacheWriter<Object, Object>() {
@Override
public void write(@NonNull Object o, @NonNull Object o2) {
//将缓存的数据写入数据库
System.out.printf("key: %s is write , value: %s", o, o2);
}
@Override
public void delete(@NonNull Object o, @Nullable Object o2, @NonNull RemovalCause removalCause) {
//删除其他的数据
System.out.printf("key: %s is delete , value: %s , reason is %s", o, o2, removalCause.name());
}
})
.build();
cacheOne.put("k1", "v1");
System.out.printf("key: %s , value: %s", "k1", cacheOne.getIfPresent("k1"));
cacheOne.put("k2", "v2");
System.out.printf("key: %s , value: %s", "k1", cacheOne.getAllPresent(Lists.newArrayList("k1", "k2")));
}与SpringBoot集成
<!--缓存-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.ben-manes.caffeine/caffeine -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.0.3</version>
</dependency>注解方式
- yml文件配置
spring:
cache:
type: caffeine
cache-names:
- caffeineTestOne
- caffeineTestTwo
caffeine:
spec: maximumSize=500yml配置可替换为Configuration类配置
@Configuration
public class CaffeineConfig {
@Bean
public CacheManager caffeineCacheManager() {
List<CaffeineCache> caffeineCaches = new ArrayList<>();
//可自行在yml或使用枚举设置多个缓存,不同名字的缓存的不同配置
caffeineCaches.add(new CaffeineCache("caffeineTestOne",
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterWrite(10, TimeUnit.SECONDS)
.build())
);
caffeineCaches.add(new CaffeineCache("caffeineTestTwo",
Caffeine.newBuilder()
.maximumSize(500)
.expireAfterWrite(10, TimeUnit.SECONDS)
.build())
);
SimpleCacheManager cacheManager = new SimpleCacheManager();
cacheManager.setCaches(caffeineCaches);
return cacheManager;
}
}
- 在启动类加注解:@EnableCaching,表示开始缓存功能
@EnableCaching // 开启缓存
@SpringBootApplication
@ComponentScan(basePackages = "com.ldy")
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}- 在想要缓存的方法和参数上使用注解:@Cacheable(value = "caffeineTestOne")(value指定了caffeine)
@Cacheable(value = "caffeineTestOne")
public String getKey(String key) {
log.info("本次从逻辑获取 key=[{}]", key);
return key;
}执行第一次显示日志,表示从逻辑中获取,后面的同参数请求就没日志打印了,表示走的是Caffeine缓存。
配合Redis做二级缓存
缓存的解决方案一般有三种
- 本地内存缓存,如Caffeine、Ehcache; 适合单机系统,速度最快,但是容量有限,而且重启系统后缓存丢失
- 集中式缓存,如Redis、Memcached; 适合分布式系统,解决了容量、重启丢失缓存等问题,但是当访问量极大时,往往性能不是首要考虑的问题,而是带宽。现象就是 Redis 服务负载不高,但是由于机器网卡带宽跑满,导致数据读取非常慢
- 第三种方案就是结合以上2种方案的二级缓存应运而生,以内存缓存作为一级缓存、集中式缓存作为二级缓存
市面上已有成熟的框架,开源中国官方开源的工具:J2Cache
大致原理就是这样
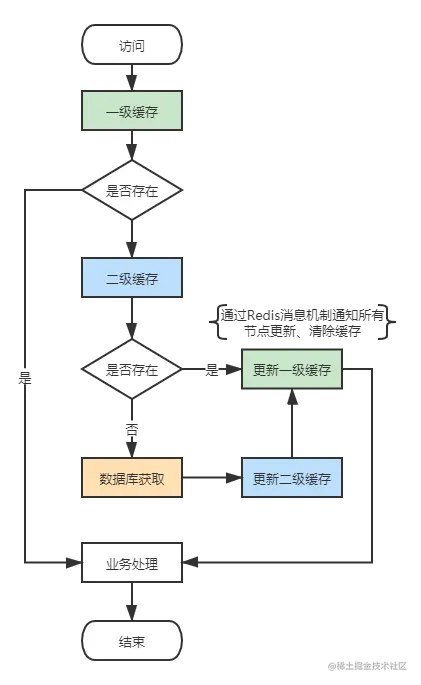
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 抖店的发展前景?2024准备入局抖店的,建议做好以下准备
- 清华开源ChatGPT自动编程ChatDev项目codes.py代码解读
- 邮件营销高回复率技巧:提升客户响应率的实用指南
- log4js-node在nodejs项目中的使用示例
- 条件编译是一种在预处理阶段根据特定条件控制代码是否被编译的技术
- Docker安装WebRTC下TURN服务
- Python入门-函数
- linux中安装docker
- JLX12864带中文字库液晶屏的STM32驱动程序
- 干货!3D模型格式转换工具HOOPS Exchange文件格式支持最新明细