论文阅读_tinyllama_轻量级大模型
英文名称: 'TinyLlama: An Open-Source Small Language Model'
中文名称: 'TinyLlama: 一个开源的小型语言模型
链接: http://arxiv.org/abs/2401.02385v1
代码: https://github.com/jzhang38/TinyLlama
作者: Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu机构: 新加坡科技与设计大学日期: 2024-01-04
1 读后感
文中介绍了 TinyLlama 一种开源的轻量级大语言模型。作者发布了所有相关信息,包括的预训练代码、所有中间模型检查点以及数据处理步骤的细节。TinyLlama 可以在移动设备上支持最终用户应用程序,并作为测试语言模型的轻量级平台。
TinyLlama 相对于 Llama2,在架构和算法上都没有太多改进,但有一些微调,旨在测试用更多 token,更小模型的训练结果,以及提交训练效率的方法。
论文正文 5 页左右。
2 摘要:
目标:TinyLlama 是在约 1T tokens 上进行了约 3 轮 (epochs) 的预训练的,大小为 1.1B 的紧凑型语言模型。
方法:基于 Llama 2 的架构和分词器,它利用了开源社区的各种新技术,实现了更好的计算效率。
结论:在一系列下游任务中,明显优于具有相似尺寸的现有开源语言模型。


3 引言
自然语言处理的最新进展在很大程度上是通过扩大语言模型规模来推动的。一些实证研究表明,要训练最优模型,模型的大小和训练数据量应以相同的速度增加。
也有实验证明,当使用更多数据训练时,较小模型训练较长时间的情况下,较小的模型可以匹配甚至优于较大的模型。
文中工作的重点是探索使用非常大量的数据训练具有参数量较小的模型,且开源了 TinyLlama。
4 预训练
4.1 预训练数据
采用自然语言数据和代码数据混合预训练 TinyLlama,从 SlimPajama 获取自然语言数据(1.2 T tokens),从 Starcoderdata 获取代码数据(86 种编程语言,约 250 B token)。采用 Llama 的分词器来处理数据。
将两个语料库结合起来后,总共有大约 950B Token 用于预训练。训练 3 轮 (epochs)。在训练过程中,以自然语言数据和代码数据之间大约 7:3 的比例采样。
4.2 架构
采用与 Llama 2 类似的模型架构


位置嵌入使用 RoPE 旋转位置嵌入;归一化使用 RMSNorm 提高训练效率;激活函数使用 SwiGLU;注意力使用 Grouped-query Attention 分组查询,以减少内存带宽开销并加快推理速度,它可在多个头之间共享键和值表示,而不牺牲太多性能。
4.3 速度优化
完全分片数据并行(FSDP)
在训练期间,集成了 FSDP,以有效地利用多 GPU 和多节点设置,显著提高了训练效率。
Flash Attention
集成了 Flash Attention 2 优化的注意力机制,以提高计算吞吐量。
xFormers
用原始的 SwiGLU 模块替换了 xFormers 中的融合 SwiGLU 模块。以减少内存占用,使 1.1B 模型能在 40GB 的 GPU RAM 训练。


图 1:训练速度比较。
性能分析及与其他型号的比较
将训练吞吐量提高到每个 A100-40G GPU 每秒 24,000 token。与其他模型相比,如图所示,TinyLlama-1.1B 模型只需要 3,456 个 A100 GPU 小时即可训练 300B token,在训练中节省大量时间和资源。
4.4 训练
基于 lit-gpt 构建框架,在预训练阶段采用了自回归语言建模目标,与 Llama 2 的设置一致。文中使用 16 个 A100-40G GPU 预训练了 TinyLlama。
5 结果
在广泛常识推理和解决问题的任务上评估了 TinyLlama,将其与大小相似的模型进行比较。
5.1 常识推理评测


图 2 展示了训练过程中性能的变化:


图 2:预训练期间常识推理基准的性能演变,与 Pythia-1.4B 性能比较。
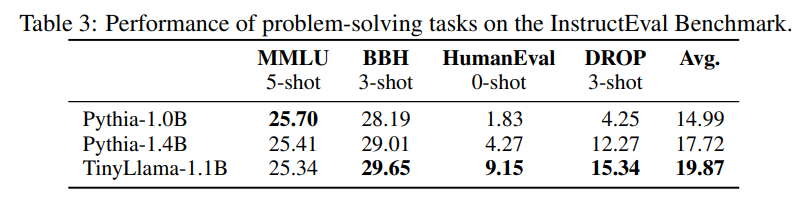
5.2 解决问题评测
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 代理注册行业的CRM解决方案-有哪些特色功能?
- LaTex详细安装及配置(Windows)
- JavaIO:企业级深度剖析NIO技术
- Linux进程程序替换
- 苹果紧急修复两大零日漏洞,影响iPhone、iPad 和 Mac 设备
- 24年初级会计资格考试报名信息采集流程共10大步骤,千万不要搞错
- 【LMM 003】生物医学领域的垂直类大型多模态模型 LLaVA-Med
- QT 利用开源7z 实现解压各种压缩包,包括进度条和文件名的显示(zip,7z,rar,iso等50多种格式)
- Jtti:怎么解决Docker容器日志占用空间过大的问题?
- 使用IDEA后端java代码打包为jar,使用Nginx打包前端Vue