已解决:UnicodeDecodeError: ‘gb2312‘ codec can‘t decode byte 0xe5 in position 1
发布时间:2024年01月10日
起因
python 读文件报错。这个报错不是来自open而是read函数(请看最后部分)。
原因:文件编码不一致。
比如文件本身编码为 gb2312,而 python默认以 utf-8 编码打开,报错。
解决
初级:以通用的 utf-8 编码打开。
with open(file_path, 'r', encoding=‘utf-8’) as file:
code = file.read()
问题:文件本身编码非 utf-8 能够解析的编码,比如gbk,就无法打开了。
中级:先读取文件编码,然后用该编码打开
with open(file_path, 'rb') as file:
content = file.read()
encoding = chardet.detect(content)['encoding']
print("编码为:" + encoding)
with open(file_path, 'r', encoding=encoding) as file:
content = file.read()
问题:当文件本身已经存在部分乱码时,无法打开。
高级:ignore:忽略无法解码或编码的字符,直接跳过。
try:
with open(file_path, 'rb') as file:
content = file.read()
encoding = chardet.detect(content)['encoding']
with open(file_path, 'r', encoding=encoding, errors='ignore') as file:
content = file.read()
except Exception as e:
logging.error(e)
解释:
errors参数解释
errors是一个可选字符串,用于指定如何处理编码和解码错误——不能在二进制模式中使用。
errors 常用的参数值:
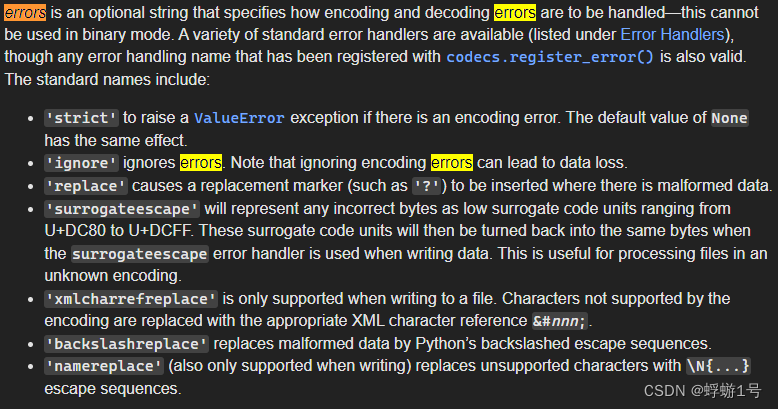
strict:当遇到无法解码或编码的字符时,抛出 ValueError 异常。也是默认值。(解释:UnicodeDecodeError 实际是 read()函数报的错,不是open函数报的)
ignore:忽略无法解码或编码的字符,直接跳过,会缺失这部分内容。
replace:将畸形数据替换为指定字符(比如问号’?')。
文章来源:https://blog.csdn.net/JiuShu110/article/details/135503775
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JavaScript新加入的**运算符,哪里有些不一样呢?
- python代码行数统计
- 数据加工:从原始数据到有价值的信息
- C++学习笔记(十六)
- 深入理解JVM虚拟机第三十一篇:详解JVM当中本地方法接口
- 深入浅出理解Web认证:Session、Cookie与Token
- YOLOv8改进全新Inner-IoU损失函数:全网首发|2023年11月最新论文|扩展到其他SIoU、CIoU等主流损失函数,带辅助边界框的损失
- 三.Winform使用Webview2加载本地HTML页面
- pandas分组聚合转换
- Spring MVC文件上传!!!