Text-to-SQL小白入门(十一)DAIL-SQL教你刷Spider榜单第一
发布时间:2024年01月04日
论文概述
学习这篇Text2SQL+LLM的benchmark论文前,可以先学习一下基础的Text2SQL知识。
,这个项目收集了Text2SQL+LLM领域的相关简介、综述、经典Text2SQL方法、基础大模型、微调方法、数据集、实践项目等等,持续更新中!
(如果觉得对您有帮助的话,可以star、fork,有问题、建议也可以提issue、pr,欢迎围观)

基本信息
- 英文标题:Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
- 中文标题:基于LLM的Text2SQL:基准评估
- 发表时间:2023年8月29日 v1版,2023年11月20日v4版
- 作者单位:阿里巴巴
- 论文链接:https://arxiv.org/abs/2308.15363
- 代码链接:GitHub - BeachWang/DAIL-SQL: A efficient and effective few-shot NL2SQL method on GPT-4.
摘要
- 大型语言模型(LLM)用于Text2SQL任务已成为一种新范式。 然而,缺乏系统的基线benchmark阻碍了基于 LLM 的Text2SQL方案设计。
- 为了应对这一挑战,在本文中,论文首先进行了系统且广泛的研究,与现有提示工程方法prompt engineering methods比较,包括问题表示question representation、例子选择example selection和例子组织example organization,并通过这些实验结果,论文阐述了它们的优点和缺点。
- 基于这些发现,论文提出了一种新的综合名为DAIL-SQL的解决方案,刷新Spider排行榜-执行准确率(EX)达到 86.6%,树立了新标杆。
- 为了探索开源LLM的潜力,论文进行了调查,并进一步使用有监督微调SFT提升其性能。论文的探索突出了开源LLM 在Text2SQL方面的潜力,以及监督微调的优点和缺点。 此外,为了实现一个高效且经济的基于LLM的Text2SQL解决方案,论文强调prompt engineering的token效率并进行比较之前的研究。
86.6现在已经不是spider第一了,不过仍然非常强大,也开源了代码,目前(2024-0104)是MiniSeek的91.2(没有开源代码),可以参考Awesome-Text2SQL开源项目中的榜单汇总

结果
问题表示question representation
有5个类别:
- Basic Prompt

- Text Representation Prompt (多了一些文字描述)

- OpenAI Demostration Prompt

- Code Representation Prompt

- Alpaca SFT Prompt

图 1:zero-shot场景下Spider-dev 上不同问题表示的结果。
- 没有一致的最好question representation,也就是说不同的模型,可能question representation表现最好的不是同一种
- 具体的数值可以看表5

- Vicuna-33B:OpenAI Demostration Prompt表现最好
- GPT-4:Basic Prompt 表现最好
- GPT-3.5-TURBO:OpenAI Demostration Prompt表现最好
- TEXT-DAVINCI-003:Code Representation Prompt表现最好

论文做了消融实验,对prompt中的问题表示去掉外键信息,比如图2和表6。
图2 Spider-dev 上外键信息的消融实验。 绿色箭头表示增加,红色箭头表示,表示减少。
- 大部分问题表示中增加上foreign key后,EX和EM都是有增加的,除了少数,比如Text Representation Prompt With Foreign Keys 在GPT-4下,结果反而还降低了0.2。


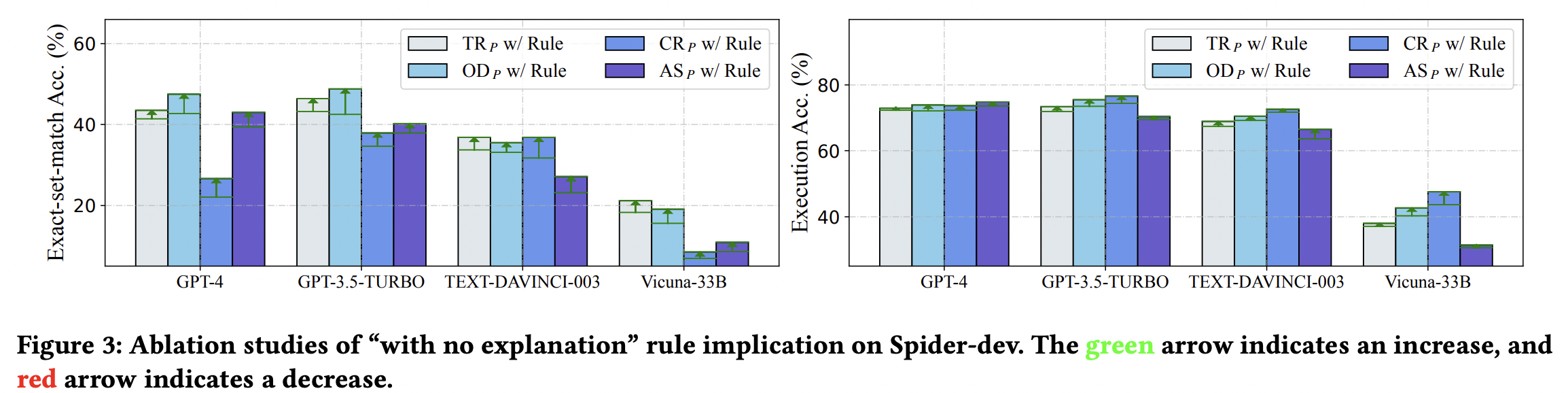
同样的,还有关于是否解释explanation的消融实验,如图3和表7。
- 加上Explanation rule,大部分问题表示结果EX/EM都是上升的,除了OpenAI Demostration Prompt。

上下文学习In-Context Learning(ICL)
这里统一选取问题表示为Code Representation Prompt
Example Selection
example的选择分为了5类:

- Random 随机选example
- Question Similarity selection 根据和问题的相似性选择
- Masked Question Similarity selection 把问题的表名、列名mask,再计算问题的相似性
- Query Similarity selection 查询的相似性
- DAIL selection 就是这篇论文的方法
- Upper Limit
-
- 这个和DAIL selection类似,只不过计算的是ground truth的query的相似性 (DAIL selection 是predicted query)

- 1-shot/3-shot/5-shot,DAIL selection方法仅次于Upper Limit,比其他的方法都要好,表明了问题相似性的重要性。
- 因为比Upper Limit差,表面了生成得query和真实的query之间的差距。
Example Organization
示例的组织方式有3种:
- Full-Information Organization

- SQLOnly Organization

- DAIL Organization

图4 :对不同example organization 的 Spider-dev 进行评估。
Example Selection 固定为 DAIL Selection。

- 详细数据如表10
-
- spider数据集上,在GPT-4上,DAIL Organization 都比另外两种情况好。当为7-shot时,EX最高为83.5。

-
- 比如还有Spider-Realistic数据集上

SFT
开源模型-0-shot
- 不对齐,LLaMA-33B在EX指标表现最好42.8,EM指标最好是13.8
- 对齐后,codellama-34b在spider-dev表现最好,使用code representation,EX-68.5,EM-27.8

开源模型-few-shot
- 横坐标是k-shot:比如0-shot、1-shot、3-shot等
- 纵坐标是EX/EM
- EM指标上:LLaMA-33B表现最好
- EX指标上:Vicuna-33B表现最好

开源模型-SFT
- 不经过SFT模型,few-shot可以提高精度
-
- LLaMA -7B-0-shot < LLaMA -7B -1-shot
- 经过SFT之后,few-shot反而会降低精度
-
- LLaMA -7B-SFT-0-shot > LLaMA -7B -1-shot

Token Efficiency
这个比较还是有意思的,不光用精度评估,也要用过程的消耗以及token数量评估
- token 的数量
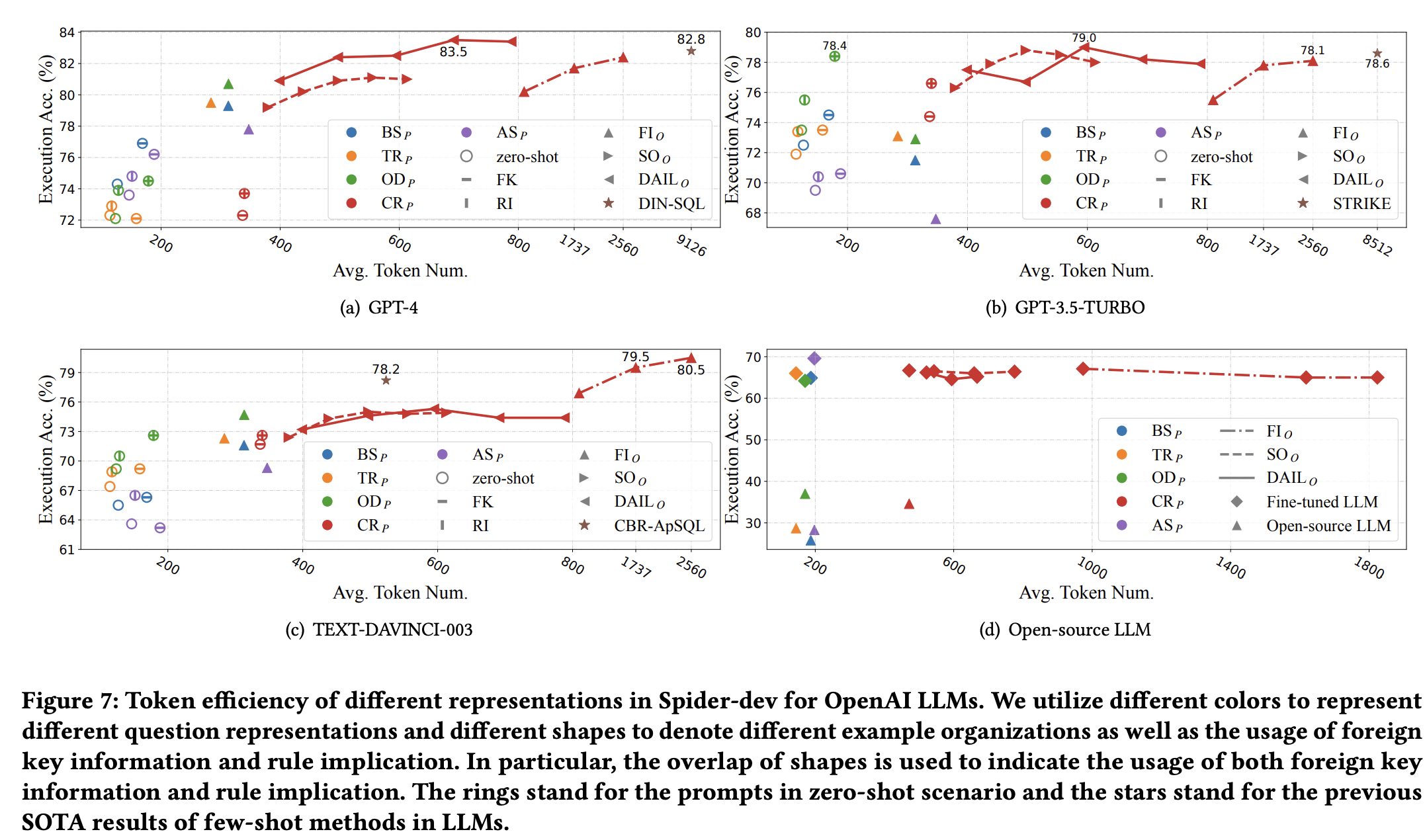
- 花钱多少

- 花时间多少

论文的数据实验非常扎实,分类别很多,需要很细致的看,附录也有很多实验,值得学习和借鉴。
结论
few-shot + SFT 效果不如SFT,这一点很关键。
- 在本文中,论文提出了一种新的快速工程方法,名为 DAIL-SQL,刷新 Spider 排行榜EX-86.6%,排名第一。
- 关于监督微调,论文展示了开源 LLM 在Text2SQL方面的巨大潜力,强调了在语料库预训练和模型参数的重要性,并指出微调后上下文学习能力的退化。
- 此外,论文进行对现有解决方案在效率方面的观察,其中表明 DAIL-SQL 效率更高,并强调了标记效率在提示工程中的重要性。
核心方法
DAIL-SQL-步骤
细节去参考源码,这里理解一下大概意思
- 输入:
-
- 目标question和目标database
- 其他的Text2SQL+LLM的基础信息:比如question、database、三元组(question,answer(就是SQL), dataset)、示例examples、model、相似度阈值等等等
- 输出:
-
- 针对目标quetsion,得到对应的sql
- 方法
-
- 1.对问题进行mask:包括目标question和候选questions
- 2.初步预测sql
- 3.解析预测的初步sql骨架
- 4.计算和mask_question的相似性,排序
- 5.重新排序:通过优先考虑具有高度的查询相似度的候选者来重新排序 Q
- 6.重新生成prompt和最后的SQL

一些细节
更加具体的细节:
- question representation --> Code Representation Prompt
- example selection --> DAIL Selection
- example organization --> DAIL Organization
- 使用 self-consistency -->增长0.4% 【Self-Consistency Improves Chain of Thought Reasoning in Language Models】
文章来源:https://blog.csdn.net/qq_40755094/article/details/135396391
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- vue2面试题:对vue生命周期的理解
- redis安装-Linux为例
- springboot常见注解
- web开发学习笔记(6.element ui)
- TSINGSEE青犀基于opencv的安全帽/反光衣/工作服AI检测算法自动识别及应用
- 提升FTP上传速度的方法(提升FTP下载速度的技巧)
- 【产品经理】产品专业化提升路径
- 防抖(debounce)
- 大模型实战笔记04——XTuner 大模型单卡低成本微调实战
- 广播测试信令记录一文全解