Spark详解
Spark
概念
Spark 提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
核心架构

Spark Core
包含 Spark 的基本功能;尤其是定义 RDD 的 API、操作以及这两者上的动作。其他 Spark 的库都是构建在 RDD 和 Spark Core 之上的
Spark SQL
提供通过 Apache Hive 的 SQL 变体 Hive 查询语言(HiveQL)与 Spark 进行交互的 API。每个数据库表被当做一个 RDD,Spark SQL 查询被转换为 Spark 操作。
Spark Streaming
对实时数据流进行处理和控制。Spark Streaming 允许程序能够像普通 RDD 一样处理实时数据
Mllib
一个常用机器学习算法库,算法被实现为对 RDD 的 Spark 操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
GraphX
控制图、并行图操作和计算的一组算法和工具的集合。GraphX 扩展了 RDD API,包含控制图、创建子图、访问路径上所有顶点的操作
核心组件
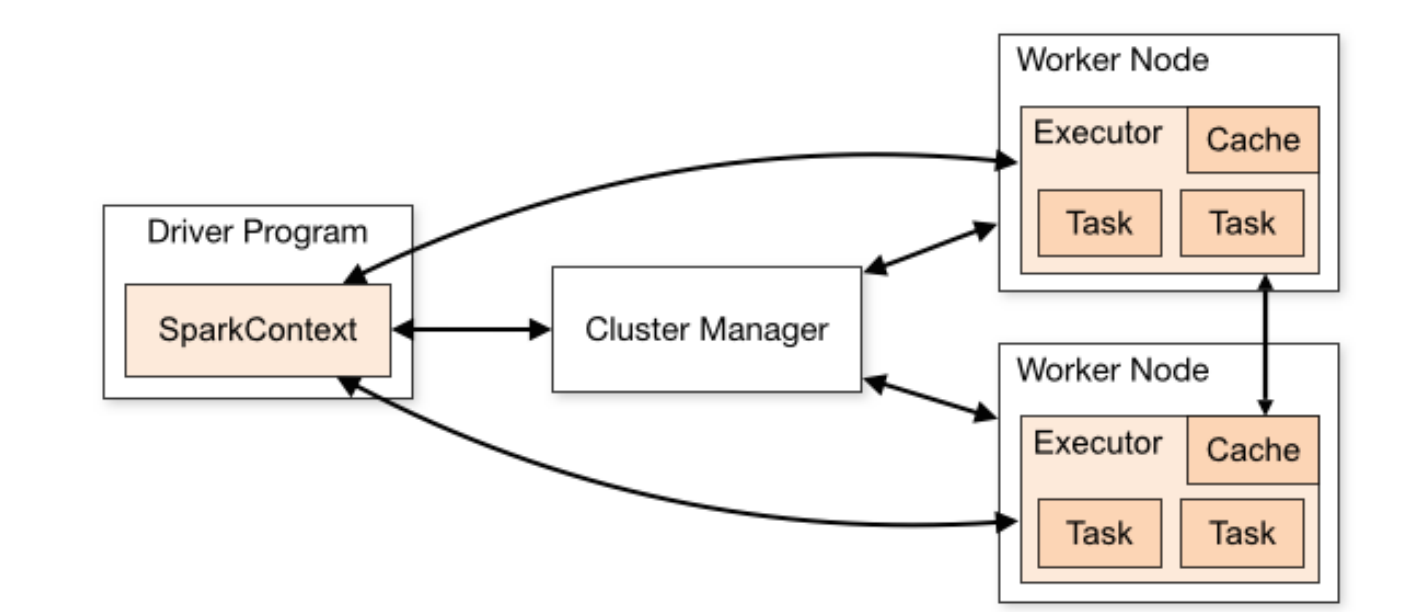
Cluster Manager-控制整个集群,监控 worker
在 standalone 模式中即为 Master 主节点,控制整个集群,监控 worker。在 YARN 模式中为资源管理器
Worker 节点-负责控制计算节点
从节点,负责控制计算节点,启动 Executor 或者 Driver。
Driver: 运行 Application 的 main()函数
Executor:执行器,是为某个 Application 运行在 worker node 上的一个进程
SPARK 编程模型
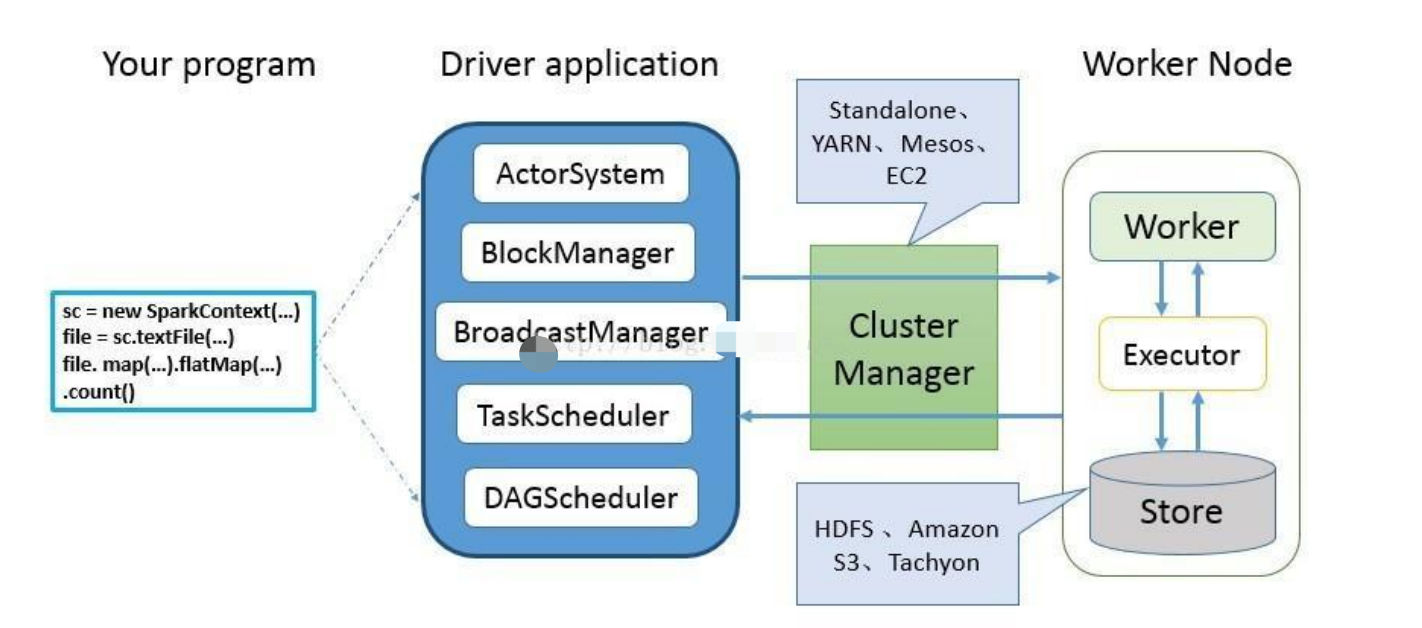
Spark 应用程序从编写到提交、执行、输出的整个过程如图所示,图中描述的步骤如下:
-
用户使用 SparkContext 提供的 API(常用的有 textFile、sequenceFile、runJob、stop 等)编写 Driver application 程序。此外 SQLContext、HiveContext 及 StreamingContext 对SparkContext 进行封装,并提供了 SQL、Hive 及流式计算相关的 API。
-
使用SparkContext提交的用户应用程序,首先会使用BlockManager和BroadcastManager将任务的 Hadoop 配置进行广播。然后由 DAGScheduler 将任务转换为 RDD 并组织成 DAG,DAG 还将被划分为不同的 Stage。最后由 TaskScheduler 借助 ActorSystem 将任务提交给集群管理器(Cluster Manager)。
-
集群管理器(ClusterManager)给任务分配资源,即将具体任务分配到Worker上,Worker创建 Executor 来处理任务的运行。Standalone、YARN、Mesos、EC2 等都可以作为 Spark的集群管理器。
SPARK 计算模型
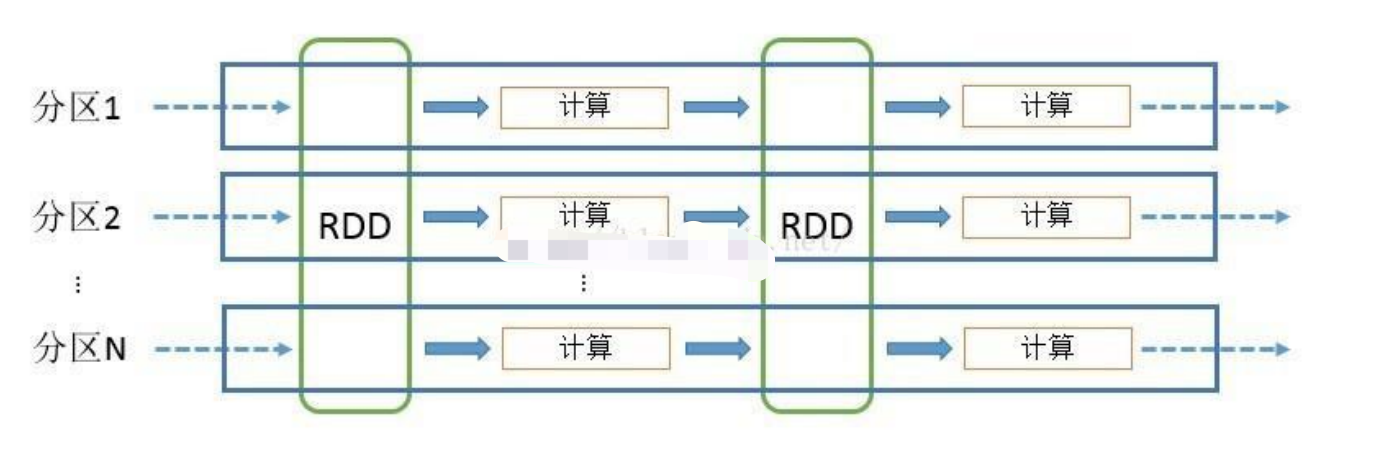
RDD 可以看做是对各种数据计算模型的统一抽象,Spark 的计算过程主要是 RDD 的迭代计算过程。RDD 的迭代计算过程非常类似于管道。分区数量取决于 partition 数量的设定,每个分区的数据只会在一个 Task 中计算。所有分区可以在多个机器节点的 Executor 上并行执行。
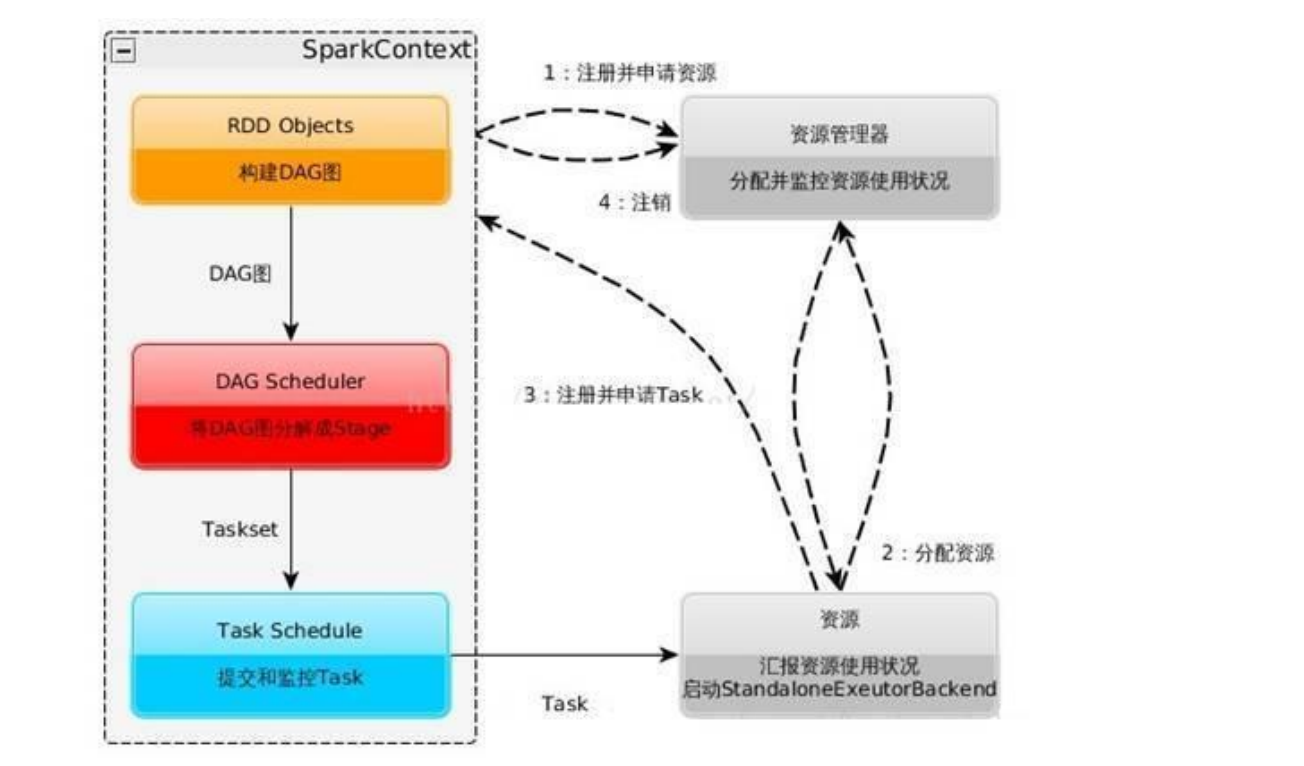
SPARK 运行流程
-
构建 Spark Application 的运行环境,启动 SparkContext
-
SparkContext 向资源管理器(可以是 Standalone,Mesos,Yarn)申请运行 Executor 资源,并启动 StandaloneExecutorbackend
-
Executor 向 SparkContext 申请 Task
-
SparkContext 将应用程序分发给 Executor
-
SparkContext 构建成 DAG 图,将 DAG 图分解成 Stage、将 Taskset 发送给 Task Scheduler,最后由 Task Scheduler 将 Task 发送给 Executor 运行
-
Task 在 Executor 上运行,运行完释放所有资源
SPARK RDD 流程
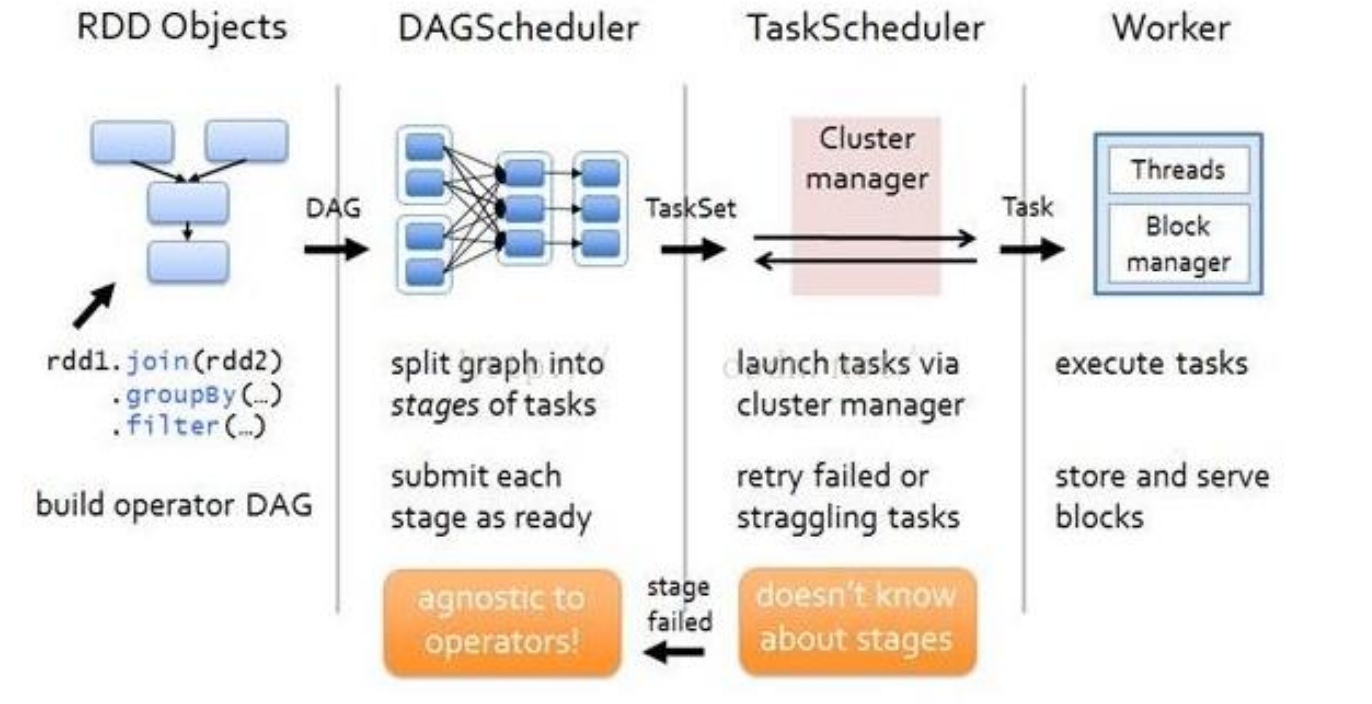
-
创建 RDD 对象
-
DAGScheduler 模块介入运算,计算 RDD 之间的依赖关系,RDD 之间的依赖关系就形成了DAG
-
每一个 Job 被分为多个 Stage。划分 Stage 的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个 Stage,避免多个 Stage 之间的消息传递开销
SPARK RDD
RDD的创建方式
1)从 Hadoop 文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、HBase)输入(例如 HDFS)创建。
2)从父 RDD 转换得到新 RDD。
3)通过 parallelize 或 makeRDD 将单机数据创建为分布式 RDD。
RDD的两种操作算子(转换(Transformation)与行动(Action))
对于 RDD 可以有两种操作算子:转换(Transformation)与行动(Action)。
1)转换(Transformation):Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个 RDD 的转换操作不是马上执行,需要等到有 Action 操作的时候才会真正触发运算。
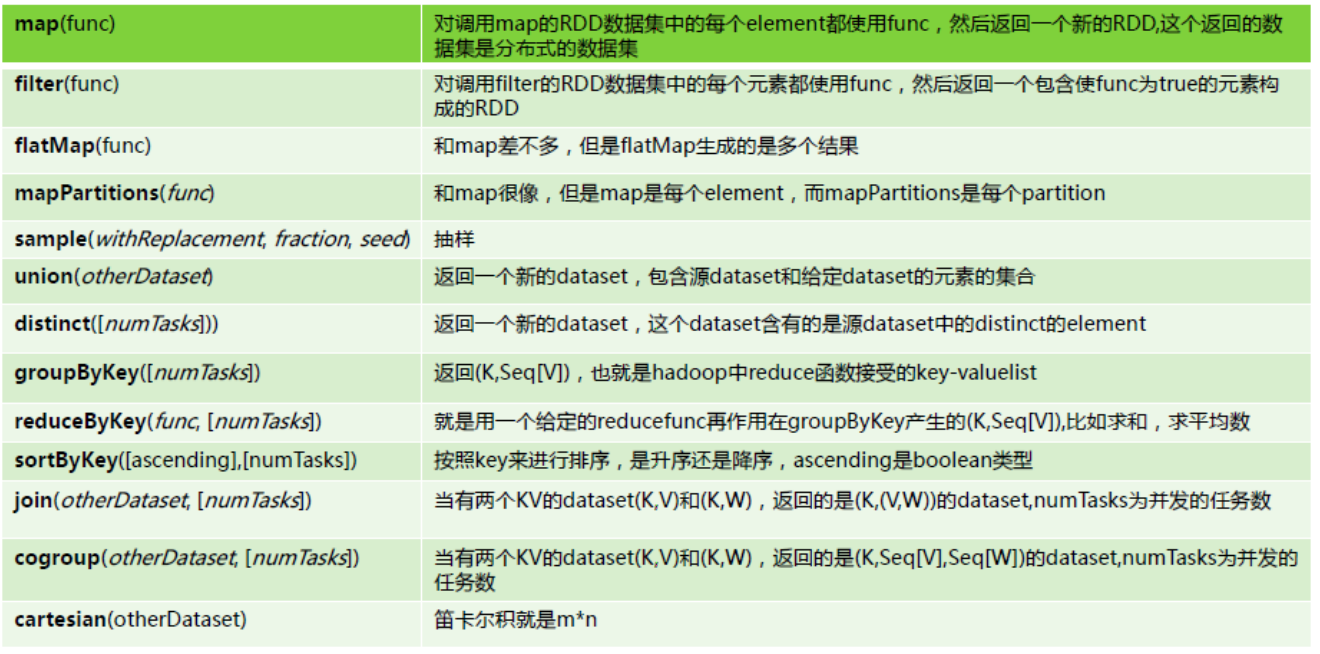
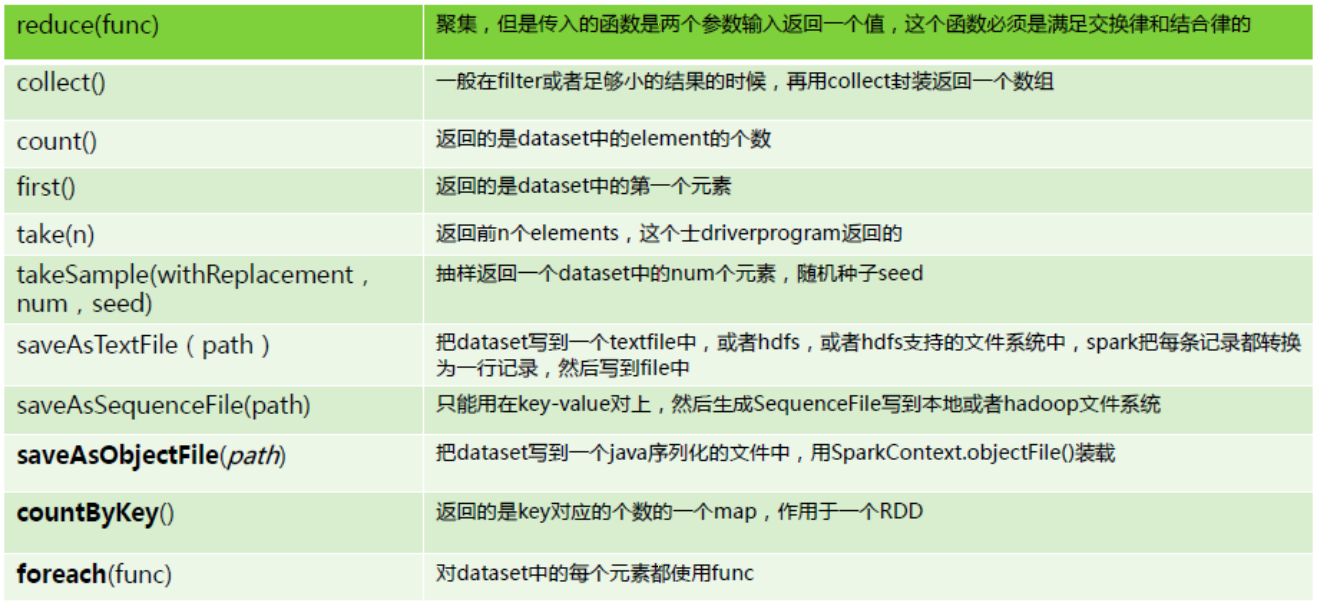
2)行动(Action):Action 算子会触发 Spark 提交作业(Job),并将数据输出 Spark 系统。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用Scikit Learn 进行识别手写数字
- 家用燃气热水器在进行点火测试时,格雷希尔G60系列和G85V系列快速连接器的密封方案
- cetos7搭建部署k8s 版本1.28
- 如何用GOWIN创建FPGA工程
- 记录win10专业版启动VMware虚拟机开机秒蓝屏问题
- 【ranger】CDP环境 更新 ranger 权限策略会发生低概率丢失权限策略的解决方法
- vue3 项目笔记
- 【CSDN博客系列】自定义模块
- File 类的用法和 InputStream, OutputStream 的用法
- SQL Server2022版+SSMS安装(保姆级)