目标检测-One Stage-YOLOv7
文章目录
前言
自YOLOv4之后,其作者提出一些新的trciks,YOLOv7诞生主要贡献分为以下3个方面
- 设计了几种训练tricks(bag-of-freebies),使得实时目标检测可以在不增加推理成本的情况下大大提高检测精度
- 针对目标检测领域现有的两个问题提出解决方案:一是模块重参化如何高效合并,二是动态标签分配策略如何处理好不同输出层的分配
ps:
- 模型重参化就是在推理阶段将多个模块合并为一个计算模块,YOLOv6的RepVGG Style就是基于这种策略设计的
- YOLOv6的是SimOTA就是一种动态标签分配策略,除此外还有ATSS、OTA、TAL等方法
- 提出了一种新型的模型缩放方法-基于级联模型的复合缩放方法,可以更加高效地利用参数和计算量,减少实时探测器50%的参数,使其具备更快的推理速度和更高的检测精度。
提示:以下是本篇文章正文内容,下面内容可供参考
一、YOLOv7的不同版本
YOLOv7给出了以下版本:
- 基础版本
YOLOv7-tiny(边缘GPU)、YOLOv7(普通GPU)、YOLOv7-W6(云GPU)
- 缩放版本
YOLOv7-X:基于YOLOv7,对neck部分进行stage缩放+使用新的模型缩放法对整个模型部分进行depth和width缩放YOLOv7-E6:基于YOLOv7-W6,使用新的模型缩放法进行了depth缩放YOLOv7-D6:基于YOLOv7-W6,使用新的模型缩放法进行了depth和width缩放YOLOv7-E6E:基于YOLOv7-E6,使用E-ELAN替换ELAN
二、YOLOv7的网络结构
YOLOv7基础版本是anchor-based的,和YOLOv5比较相似,除数据增强外,在输入端都使用了自适应锚框计算、自适应图片缩放,并将Neck和Head合称Head层。
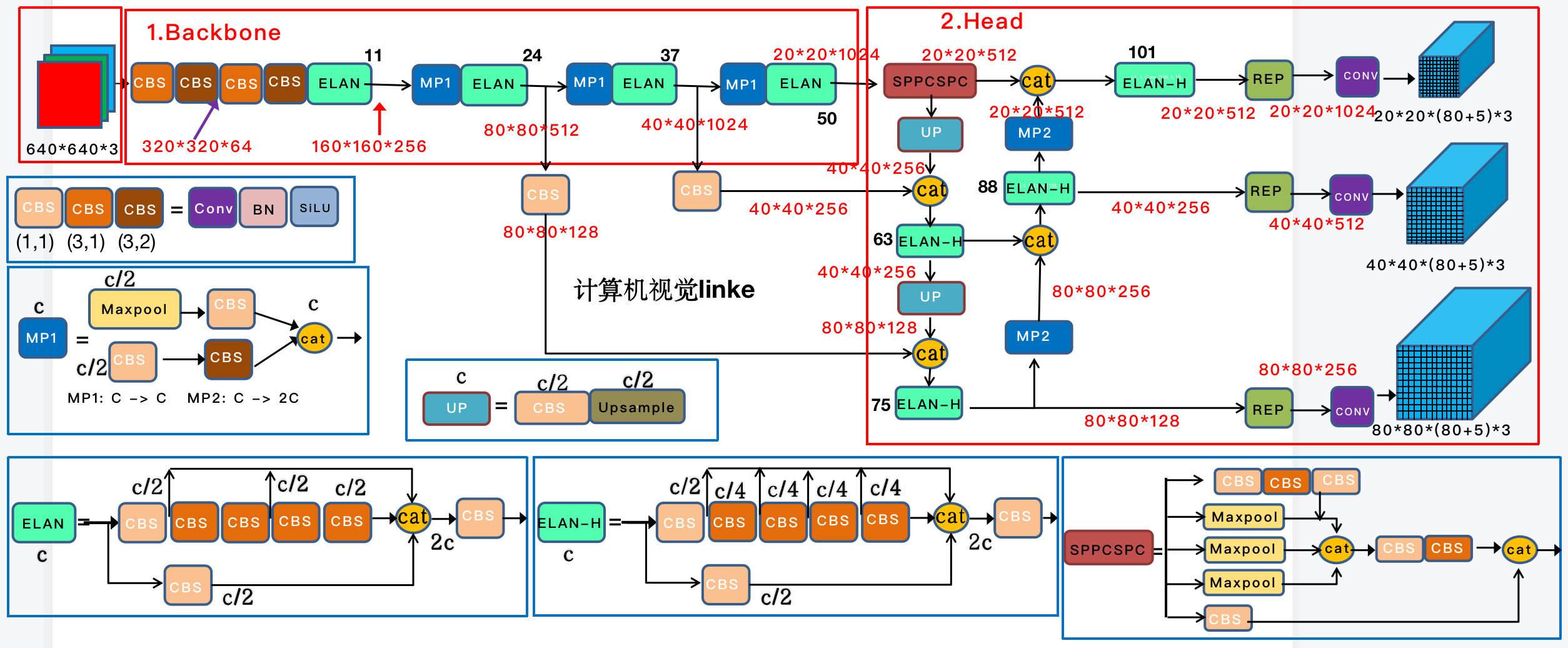
YOLOv7的网络结构图如下,可以看出改动在于:
- backbone:
- 卷积块:与YOLOv5相比,将CBL卷积模块改为不同卷积核大小的CBS(激活函数从Leaky relu改为SiLU)
- 残差块:与YOLOv5相比,将CSP_1残差块修改为ELAN,ELAN 由多个 CBS 模块堆叠组成,含有丰富的梯度流信息,能够有效的使用网络参数并且加速网络的推理
- 新增MP模块:由 CBS 和最大池化层组成,主要用于下采样操作,能够有效减少特征丢失
- Neck:
- 仍然是FPN+PAN结构,与YOLOv5相比, 将SPPF模块改为SPPCSPC模块,CSP 模块换成了 ELAN-H 模块, 同时下采样变为了 MP模块
ps:
- ELAN-H相比于 ELAN 增加了两个拼接操作,SPPCSPC 主要用于增大感受野。
- 前面系列中,已经提到了SPP(空间金字塔池化)和CSPC(跨阶段部分连接),其中SPP是一种用于解决不同尺寸输入图像问题的技术,CSPC是一种用于提高特征传递和网络效率的技术,SPPCSPC将SPP和CSPC两种技术结合起来。它首先使用SPP技术提取不同尺度的特征表示,然后通过CSPC技术进行特征传递和信息融合。这种结合可以同时处理不同尺度的特征信息,提高目标检测的准确性和效率。
- SPPCSPC 表现优于SPPF,但参数量和计算量提升了很多
- Head:
- 加入了Rep算子,用于参数重参化
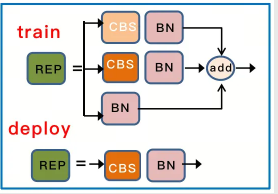
- 加入了Rep算子,用于参数重参化
二、YOLOv7的创新点
- 结合一些先进模块改进了模型:
CBS、ELAN\E-ELAN、MP、SPPCSPC、Rep,保证速度情况下,提升了检测精度 - 提出了一些BoF训练技巧(
计划型重参化卷积、辅助训练模块、标签分配(Coarse-to-fine lead head guided label assigner)),使用了一些现有BoF训练技巧(conv-bn-activation拓扑中的批量归一化、YOLOR中的隐式知识与卷积特征图以加法和乘法的方式相结合、EMA更新权重),在不增加推理成本的情况下大大提高了检测精度 - 提出了一种新型的模型缩放方法-
基于级联模型的复合缩放方法,可以更加高效地利用参数和计算量,减少实时探测器50%的参数,使其具备更快的推理速度和更高的检测精度。
三、创新点的详细解读
ELAN和E-ELAN
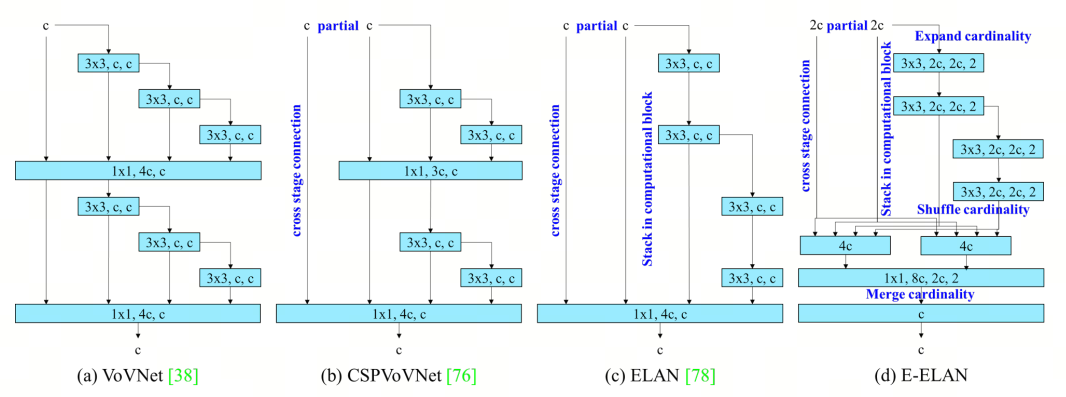
- 设计轻量级网络或高效架构时,计算量(FLOPs)和模型参数量是主要考虑因素,但是减少模型大小和FLOPs不等同于减少推理时间和降低能耗。比如ShuffleNetv2与MobileNetv2在相同的FLOPs下,前者在GPU上速度更快。所以除了FLOPs和模型大小外,还需要考虑其他因素对能耗和模型推理速度的影响。VoVNet诞生,除了考虑上述因素外,还考虑两个重要的因素:内存访问成本(Memory Access Cost,MAC)和GPU计算效率。实质上就是要减少残差连接(内存碎片化)和减少层数(并行运算)
- CSPVoVNet是VoVNet的变种,在其基础上还考虑了梯度路径(gradient path),使不同层的权重可以学习更多不同的特征,即增加了跨stage连接(cross stage connection)
- ELAN模块是一个高效的网络结构,它通过控制最短和最长的梯度路径,使网络能够学习到更多的特征,并且具有更强的鲁棒性(作者发现通过控制最短最长梯度路径,更深的网络可以有效地进行学习并更好地收敛)
- E-ELAN是ELAN的扩展
ps:在大规模ELAN中,无论梯度路径长度和计算模块数量如何,都达到了稳定的状态。但如果更多计算模块被无限地堆叠,这种稳定状态可能会被破坏,参数利用率也会降低。论文提出的E-ELAN采用expand、shuffle、merge cardinality结构,实现了在不破坏原始梯度路径的情况下,提高网络的学习能力。
BoF训练技巧
计划型重参化卷积
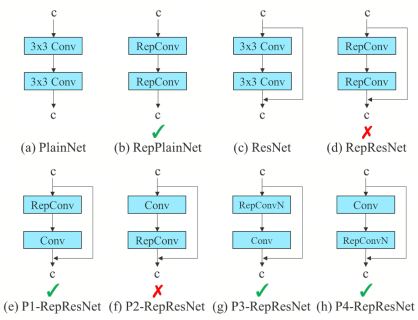
尽管RepConv在VGG上取得了优异的性能,但将它直接应用于ResNet和DenseNet或其他网络架构时,它的精度会显著降低。作者使用梯度传播路径来分析不同的重参化模块应该和哪些网络搭配使用。通过分析RepConv与不同架构的组合以及产生的性能,作者发现RepConv中的identity破坏了ResNet中的残差结构和DenseNet中的跨层连接,这为不同的特征图提供了梯度的多样性
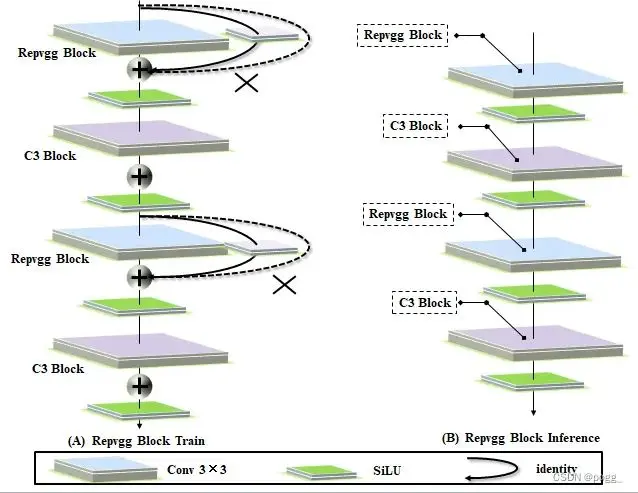
基于上述原因,作者使用没有identity连接的RepConv结构。图4显示了作者在PlainNet和ResNet中使用的“计划型重参化卷积”的一个示例
辅助训练模块
深度监督是一种常用于训练深度网络的技术,其主要概念是在网络的中间层增加额外的辅助头,以及以辅助损失为指导的浅层网络权重。即使对于像ResNet和DenseNet这样收敛效果好的网络结构,深度监督仍然可以显著提高模型在许多任务上的性能。
作者将负责最终输出的头部称为引导头部(lead head),而用于辅助训练的头部则称为辅助头部(auxiliary head)

标签分配
过去,在深度网络的训练中,标签分配通常直接参考ground true框,并根据给定的规则生成硬标签。然而,近年来,以目标检测为例,研究人员经常使用网络输出的预测质量和分布,然后与ground true框一起考虑,使用一些计算和优化方法来生成可靠的软标签。例如,YOLO使用边界框回归预测框和ground true框的IoU和作为对象性的软标签。
在软标签分配器相关技术的发展过程中,作者意外地发现了一个新的衍生问题,即“如何为辅助头和引导头分配软标签?”,并且作者并未发现相关文献迄今对此问题进行了探讨。
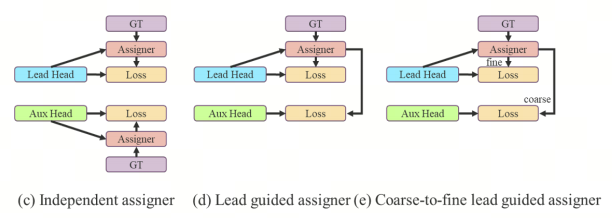
此前最流行的方法的结果如下图(c)所示,即将辅助头和引导头分离,然后使用它们自己的预测结果和ground true框来执行标签分配。本文提出的方法是一种新的标签分配方法,通过引导头预测来引导辅助头和引导头。
即使用引导头预测作为指导来生成从粗到细的分层标签,这些标签分别用于辅助头和引导头学习。提出的两种深度监督标签分配策略分别如下图(d)和(e)所示
Lead head guided label assigner
- 引导头指导的标签分配器主要根据引导头的预测结果和ground true框进行计算,并通过优化过程生成软标签。这组软标签将用作辅助头和引导头的目标训练模型。
ps:之所以这样做,是因为引导头具有相对较强的学习能力,因此从中生成的软标签应该更能代表源数据和目标之间的分布和相关性。此外,我们可以将这种学习视为一种广义残差学习。通过让较浅的辅助头直接学习引导头已经学习的信息,引导头将能够更专注于学习尚未学习的剩余信息
Coarse-to-fine lead head guided label assigner
- Coarse-to-fine引导头指导的标签分配器同样利用引导头的预测结果和ground true框生成软标签。不同的是,生成了两组不同的软标签(粗标签和细标签), 粗标签用于辅助头的目标训练模型,细标签用于引导头的目标训练模型。
ps:
- 细标签与Lead head guided label assigner生成的软标签相同,而粗标签是通过放宽正样本分配过程的约束,允许更多的网格被视为正目标来生成的(例如FastestDet的label assigner,不单单只把gt中心点所在的网格当成候选目标,还把附近的三个也算进行去,增加正样本候选框的数量)。
- 之所以这样做,是因为辅助头的学习能力不如引导头,为了避免丢失需要学习的信息,将在目标检测任务中重点优化辅助头的召回。对于引导头的输出,可以从高召回率的结果中过滤出高精度的结果作为最终输出。
- 需要注意的是,如果粗标签的附加权重接近细标签的附加权值,那么在最终预测时可能会产生不良先验。因此,为了使这些超粗正网格具有较小的影响,作者在解码器中施加了限制,使得超粗正栅格不能完美地产生软标签。该机制允许在学习过程中动态调整细标签和粗标签的重要性,并使细标签的可优化上界始终高于粗标签。
基于级联模型的复合缩放方法
compound model scaling method for a concatenation-based model
EfficientNet的缩放模型考虑了宽度、深度和分辨率。对于缩放的YOLOv4,其缩放模型是调整stage数量。
这些缩放方法主要用于PlainNet或ResNet等架构中。当这些架构执行缩放时,每层的入度和出度都不会改变,因此可以独立分析每个缩放因子对参数量和计算量的影响。
然而,如果将这些方法应用于基于级联的体系结构就会发现,当对深度进行缩放时,宽度也将改变,如下图(a)和(b)所示
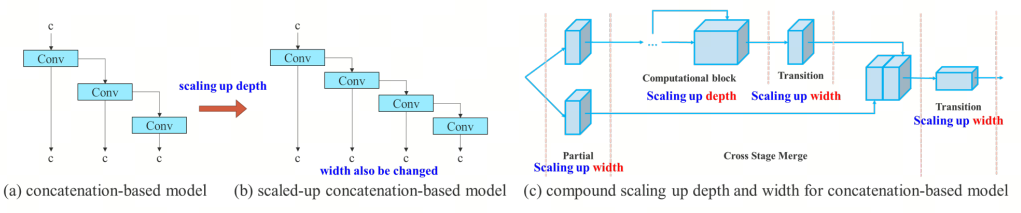
从上述现象可以推断,对于基于级联的模型,不能单独分析不同的缩放因子,而必须一起考虑。以放大深度为例,这样的动作会导致过渡层的输入通道和输出通道之间的比例变化,这可能导致模型占用更多硬件资源。
因此,必须为基于级联的模型提出相应的复合模型缩放方法。当缩放计算块的深度因子时,还必须计算该块的输出通道的变化。然后在过渡层上执行相同变化量的宽度因子缩放,结果如上图(c)所示。该复合缩放方法可以保持模型在初始设计时的特性,并保持最佳结构。
总结
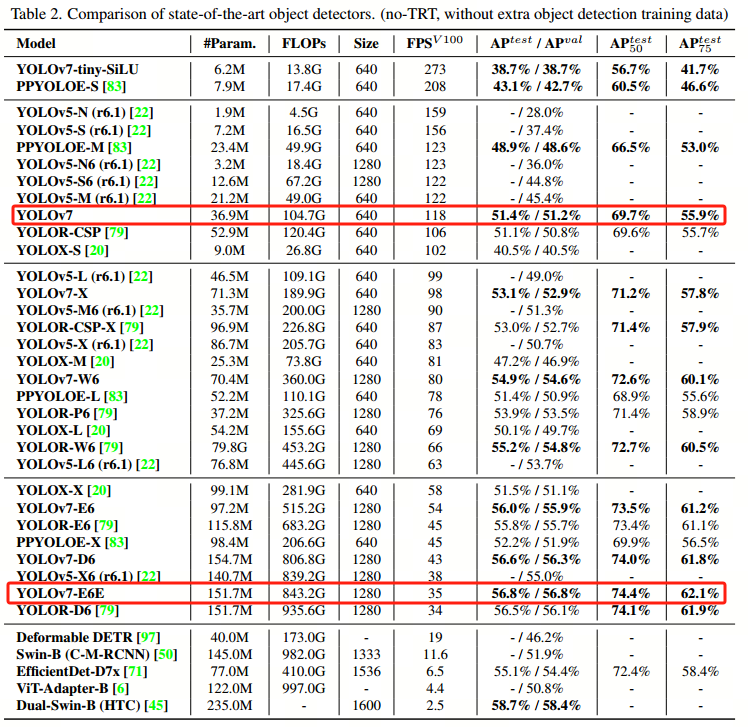
YOLOv7达到新的SOTA,所提出的方法具有最好的速度-精度均衡性
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 项目中leafleft使用方法整理
- REVIT二次开发根据类别选择元素
- 机器学习在缺陷检测中的突破与实践
- flutter 实战 之 dio小实践
- P1115 最大子段和
- 适合机器学习的ide---Jupyter Notebook的安装使用
- 10|记忆:通过Memory记住客户上次买花时的对话细节
- Socks5与代理IP:深度技术解析
- MacOS访问某局域网域名存在问题,但是ip可以正常访问的问题解决方案
- 数字人SaaS系统无限生成AI数字人!