大模型微调总结1-总览
背景
2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据以及超级算力资源使得基础模型成为一些头部企业的“特权”。
然而,无法自己创建基础模型,并不代表着大模型无法为大部分公司所用:在大量基础模型的开源分享之后,企业可以使用微调(Fine tuning)的方法,训练出适合自己行业和独特用例的大模型以及应用。
大模型
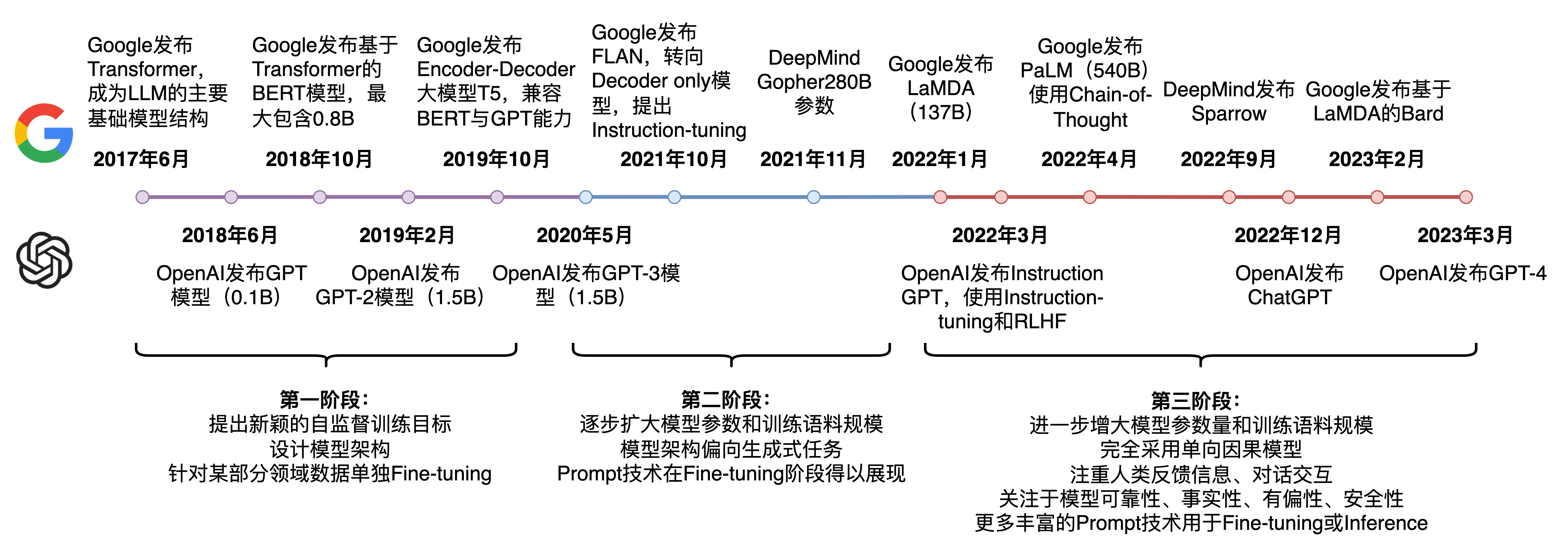
上图出自Prompt-Tuning——深度解读一种新的微调范式
截止23年3月底,语言模型发展走过了三个阶段:
第一阶段:设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式。典型代表是BERT、GPT、XLNet等;
第二阶段:逐步扩大模型参数和训练语料规模,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
第三阶段:走向AIGC(Artificial Intelligent Generated Content)时代,模型参数规模步入千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型。典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
如何对大模型进行微调
目前,基于 Transformers 架构的大型语言模型 (LLM),如 GPT、T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了 SOTA 结果。此外,还开始涉足其他领域,例如:计算机视觉 (VIT、Stable Diffusion、LayoutLM) 和音频 (Whisper、XLS-R)。
将预训练好的语言模型(LM)在下游任务上进行微调已成为处理 NLP 任务的一种范式。与使用开箱即用的预训练 LLM (例如:零样本推理) 相比,在下游数据集上微调这些预训练 LLM 会带来巨大的性能提升。随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调(full fine-tuning)变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型(调整模型的所有参数)与原始预训练模型的大小相同。
因此,近年来研究者们提出了各种各样的参数高效迁移学习方法(Parameter-efficient Transfer Learning),即固定住Pretrain Language model(PLM)的大部分参数,仅调整模型的一小部分参数来达到与全部参数的微调接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)。
1,从参数规模的角度,大模型的微调分成两条技术路线:
-
一条是对全量的参数,进行全量的训练,这条路径叫全量微调FFT(Full Fine Tuning)。
-
一条是只对部分的参数进行训练,这条路径叫PEFT(Parameter-Efficient Fine Tuning)。
FFT的原理,就是用特定的数据,对大模型进行训练 ,最大的优点就是上述特定数据领域的表现会好很多。
但FFT也会带来一些问题,影响比较大的问题,主要有以下两个:
- 一个是训练的成本会比较高,因为微调的参数量跟预训练的是一样的多的;
- 一个是叫灾难性遗忘(Catastrophic Forgetting),用特定训练数据去微调可能会把这个领域的表现变好,但也可能会把原来表现好的别的领域的能力变差。
PEFT主要想解决的问题,就是FFT存在的上述两个问题,PEFT也是目前比较主流的微调方案。
2,从训练数据的来源、以及训练的方法的角度,大模型的微调有以下几条技术路线:
-
监督式微调SFT(Supervised Fine Tuning),这个方案主要是用人工标注的数据,用传统机器学习中监督学习的方法,对大模型进行微调;
-
基于人类反馈的强化学习微调RLHF(Reinforcement Learning with Human Feedback),这个方案的主要特点是把人类的反馈,通过强化学习的方式,引入到对大模型的微调中去,让大模型生成的结果,更加符合人类的一些期望;
-
基于AI反馈的强化学习微调RLAIF(Reinforcement Learning with AI Feedback),这个原理大致跟RLHF类似,但是反馈的来源是AI。这里是想解决反馈系统的效率问题,因为收集人类反馈,相对来说成本会比较高、效率比较低。
不同的分类角度,只是侧重点不一样,对同一个大模型的微调,也不局限于某一个方案,可以多个方案一起。
微调的最终目的,是能够在可控成本的前提下,尽可能地提升大模型在特定领域的能力。
PEFT总结
参数高效微调(Parameter-efficient fine-tuning)是指微调少量或额外的模型参数,固定大部分预训练模型(LLM)参数,从而大大降低了计算和存储成本,同时,也能实现与全量参数微调相当的性能。参数高效微调方法甚至在某些情况下比全量微调效果更好,可以更好地泛化到域外场景。这也是现在主流的微调方法。
高效微调技术可以粗略分为以下三大类:增加额外参数(A)、选取一部分参数更新(S)、引入重参数化(R)。而在增加额外参数这类方法中,又主要分为类适配器(Adapter-like)方法和软提示(Soft prompts)两个小类。
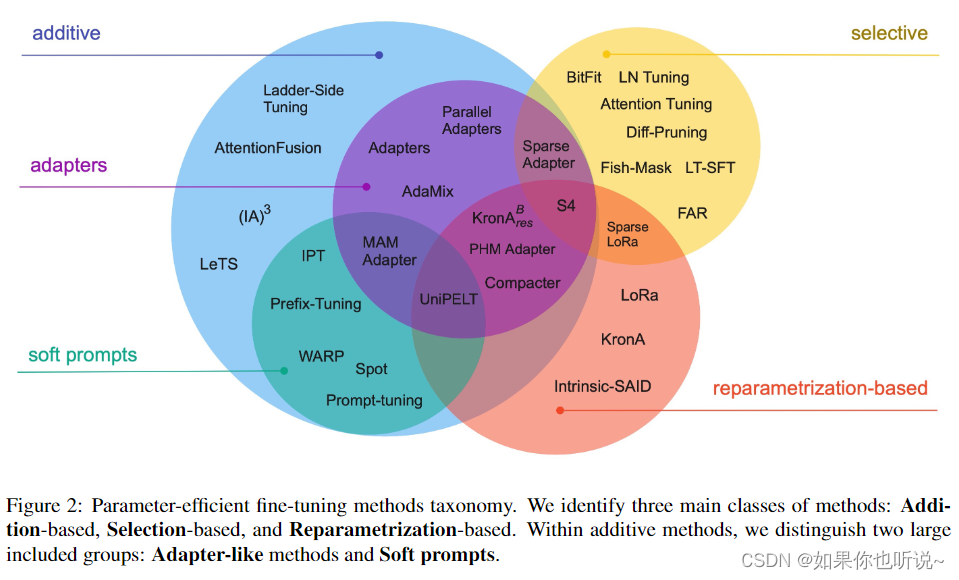
上图总结出自论文Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning
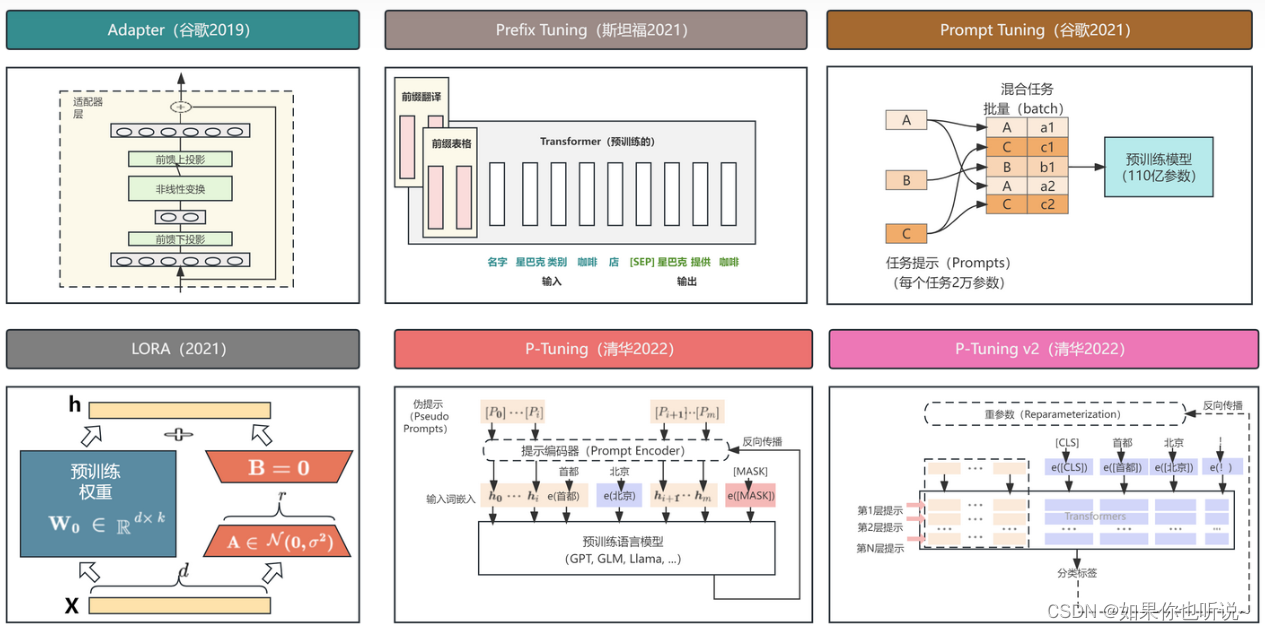
常见的参数高效微调技术有BitFit、Adapter Tuning、Prefix Tuning、Prompt Tuning、LoRA、P-Tuning等,后续文章会对此深度讲解。
实践效果:
效果上LoRA比较好,效率上P-tuning比较快,Prefix-tuning和P-tuning V2居中
https://wjn1996.blog.csdn.net/article/details/120607050
https://zhuanlan.zhihu.com/p/635152813
https://zhuanlan.zhihu.com/p/627642632
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- PyTorch|一次画一批图像
- IIS 缓存, 更新后前端资源不能更新问题
- Springboot解决跨域问题
- 【Web2D/3D】css3的2D/3D转换、过渡、动画(第一篇)
- C++初阶-priority_queue(优先级队列)的使用与模拟实现
- 【Java】post请求示例
- FaceChain-FACT:免训练的丝滑体验,秒级别的人像生成
- 乔拓云智能建站:让你的官网与众不同
- Linux环境安装2
- python两种办法对二叉树判断是否对称