【源码分析】 Calcite 处理流程详解:calcite架构、处理流程以及就一个运行示例进行源码分析
文章目录
本文主要描述
- calcite的整体架构
- calcite具体地处理流程,并通过demo debug源码解释说明
?
了解calcite,主要为了了解
- flink利用calcite对sql从逻辑执行计划到物理执行计划的转换逻辑
- flink sql connector在这个过程中起到的作用,涉及到的逻辑是什么
等原理打基础。
?
Apache Calcite是一个动态的数据管理框架, 它可以实现SQL的解析, 验证, 优化和执行。
称之为”动态”是因为Calcite是模块化和插件式的, 上述任何一个步骤在Calcite中都对应着一个相对独立的模块。用户可以选择使用其中的一个或多个模块, 也可以对任意模块进行定制化的扩展。
?
正是这种灵活性使得Calcite可以在现有的存储或计算系统上方便地构建SQL访问层, 甚至在已有SQL能力的系统中也可引入Calcite中的某个模块实现相应的功能, 比如Apche Hive就仅使用了Calcite进行优化, 但却有自己的SQL解析器。
Calcite的这种特性使其在大数据系统中得到了广泛的运用, 比如Apache Flink, Apache Drill等都大量使用了Calcite, 因此理解Calcite的原理已经成为理解大数据系统中SQL访问层实现原理的必备条件。
?
一. Calcite整体架构
Calcite的整体架构与交互如下图(Calcite论文):
- JDBC接口: 用于使用标准的JDBC接口访问Calcite获取数据, 为了提供JDBC/ODBC接口,Calcite构建了一个独立的Avatica框架。
- SQL Parser和SQL Validator: 用于进行SQL的解析和验证, 将原始的SQL字符串解析并转化为内部的
SqlNode树(即AST)表示。 - Query Optimizer: 用于进行查询优化,查询优化是在关系代数的基础上进行的。
在Calcite内部有一种关系代数表示方法, 即:将关系代数表示为RelNode树.
RelNode树可由SqlNode树转化而来, 也可通过Expressions Builder接口构建. - Enumerator执行计划: Calcite提供了一种将优化后的
RelNode树生成为Enumerator执行计划的方法。Calcite的一些Adapter使用了Enumerator执行计划.

?
Calcite省略了一些关键的组成部分, 例如, 数据的存储, 处理数据的算法和存储元数据的存储库。
Calcite的目的是仅提供构建SQL访问的框架,这也是其广泛适用的原因。这种省略带来的另一个好处是, 使用Calcite可以十分方便地构建联邦查询引擎, 即屏蔽底层物理存储和计算引擎, 使用一个统一的SQL接口实现数据访问。
?
二. Calcite处理流程
Calcite的完整处理流程实际上就是SQL的解析, 优化与执行流程,如下:

Calcite的处理流程主要分为5个阶段:
- Parser用于解析SQL, 将输入的SQL字符串转化为抽象语法树(AST), Calcite中用
SqlNode树表示. - Validator根据元数据信息对
SqlNode树进行验证, 其输出仍是SqlNode树. - Converter将
SqlNode树转化为关系代数, 以方便进一步优化, Calcite中使用RelNode树表示关系代数. - Optimizer对输入的关系代数进行优化, 输出优化后的
RelNode树. - Execute阶段会根据优化后的
RelNode生成执行计划,在Calcite中内置了一种基于Enumerator的执行计划生成方法。
Enumerator是用于执行查询计划的接口,通常与可枚举(Enumerable)执行模型一起使用。可枚举执行模型是一种将关系代数计划转换为可执行的迭代式 Java 代码的模型。
?
在执行计划的过程中,关系代数计划首先被转换为可枚举的关系表达式(EnumerableRel),然后EnumerableInterpreter将这些表达式转换为可执行的 Java 代码。最后,Enumerator接口的实现负责执行这些 Java 代码,并生成查询结果。
?
三. 处理流程样例说明
?
1. 样例demo
1.1. 样例数据

?
1.2. 使用calcite
parse sql, validate, transform to relation expression and execute with a Planner
package com.gerardnico.calcite;
import com.gerardnico.calcite.schema.hr.HrSchemaMin;
import org.apache.calcite.adapter.java.ReflectiveSchema;
import org.apache.calcite.plan.hep.HepPlanner;
import org.apache.calcite.plan.hep.HepProgramBuilder;
import org.apache.calcite.rel.RelNode;
import org.apache.calcite.rel.RelRoot;
import org.apache.calcite.rel.RelWriter;
import org.apache.calcite.rel.externalize.RelWriterImpl;
import org.apache.calcite.rel.rules.FilterJoinRule;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.sql.SqlExplainLevel;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.dialect.OracleSqlDialect;
import org.apache.calcite.sql.parser.SqlParseException;
import org.apache.calcite.sql.parser.SqlParser;
import org.apache.calcite.tools.*;
import org.junit.Test;
import java.io.PrintWriter;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* This is class that demonstrate the query process planning:
* * parse
* * validate
* * convert to a query plan
* * execute.
* See <a href="https://gerardnico.com/db/calcite/query_planning#example">Query planning process example for more info</a>
*/
public class CalciteFrameworksTest {
@Test
public void parseValidateAndLogicalPlanTest() throws SqlParseException, RelConversionException, ValidationException, SQLException {
// Build the schema
SchemaPlus rootSchema = Frameworks.createRootSchema(true);
ReflectiveSchema schema = new ReflectiveSchema(new HrSchemaMin());
SchemaPlus hr = rootSchema.add("HR", schema);
// Get a non-sensitive parser
SqlParser.Config insensitiveParser = SqlParser.configBuilder()
.setCaseSensitive(false)
.build();
// Build a global configuration object
FrameworkConfig config = Frameworks.newConfigBuilder()
.parserConfig(insensitiveParser)
.defaultSchema(hr)
.build();
// Get the planner tool
Planner planner = Frameworks.getPlanner(config);
// Parse the sql to a tree
SqlNode sqlNode = planner.parse("select depts.name, count(emps.empid) from emps inner join depts on emps.deptno = depts.deptno where emps.empid >5 group by depts.deptno, depts.name order by depts.name");
// Print it
System.out.println(sqlNode.toSqlString(OracleSqlDialect.DEFAULT));
// Validate the tree
SqlNode sqlNodeValidated = planner.validate(sqlNode);
// Convert the sql tree to a relation expression
RelRoot relRoot = planner.rel(sqlNodeValidated);
// Explain, print the relational expression
RelNode relNode = relRoot.project();
final RelWriter relWriter = new RelWriterImpl(new PrintWriter(System.out), SqlExplainLevel.EXPPLAN_ATTRIBUTES, false);
// relNode.explain(relWriter);
//add HepProgram
HepProgramBuilder builder = new HepProgramBuilder();
builder.addRuleInstance(FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN); //note: 添加 rule
HepPlanner hepPlanner = new HepPlanner(builder.build());
hepPlanner.setRoot(relNode);
relNode = hepPlanner.findBestExp();
relNode.explain(relWriter);
// Run it
PreparedStatement run = RelRunners.run(relNode);
ResultSet resultSet = run.executeQuery();
// Print it
System.out.println("Result:");
while (resultSet.next()) {
for (int i = 1; i <= resultSet.getMetaData().getColumnCount(); i++) {
System.out.print(resultSet.getObject(i)+",");
}
System.out.println();
}
}
}
?
2. 流程源码分析
Step1: SQL 解析阶段(SQL–>SqlNode)
//1. Parse the sql to a tree :AST
SqlNode sqlNode =
planner.parse("select depts.name, count(emps.empid) from emps inner join depts on emps.deptno = depts.deptno " +
"where emps.empid >5 " +
"group by depts.deptno, depts.name order by depts.name");
org.apache.calcite.prepare.PlannerImpl#parse
// reader中包含:待解析的sql
public SqlNode parse(final Reader reader) throws SqlParseException {
...
//创建解析器
SqlParser parser = SqlParser.create(reader, parserConfig);
//进行解析
SqlNode sqlNode = parser.parseStmt();
state = State.STATE_3_PARSED;
return sqlNode;
}
基本原理:
使用 JavaCC + Parser.jj 将SQL 转换为 AST:
Calcite 使用 JavaCC 做 SQL 解析,JavaCC 根据 Calcite 中定义的 Parser.jj 文件,生成一系列的 java 代码,生成的 Java 代码会把 SQL 转换成 AST 的数据结构(即 SqlNode )。
Javacc 这里要实现一个 SQL Parser,它的功能有以下两个,这里都是需要在 jj 文件中定义的。
- 设计词法和语义,定义 SQL 中具体的元素;
- 实现词法分析器(Lexer)和语法分析器(Parser),完成对 SQL 的解析,完成相应的转换。
?
1.创建解析器:
org.apache.calcite.prepare.PlannerImpl
public SqlNode parse(final Reader reader) throws SqlParseException {
switch (state) {
case STATE_0_CLOSED:
case STATE_1_RESET:
ready();
}
ensure(State.STATE_2_READY);
SqlParser parser = SqlParser.create(reader, parserConfig);
SqlNode sqlNode = parser.parseStmt();
state = State.STATE_3_PARSED;
return sqlNode;
}
parser 指的是 SqlParserImpl 类(SqlParser.Config.DEFAULT 指定的),它是由 JJ 文件生成的解析类,具体解析逻辑还是要看 JJ 文件中的定义。
?
2.将sql解析为AST(sqlNode)
SqlNode sqlNode = parser.parseStmt();
org.apache.calcite.sql.parser#SqlParser
public SqlNode parseQuery() throws SqlParseException {
...
return parser.parseSqlStmtEof();
...
}
/**
* Parses an SQL statement followed by the end-of-file symbol.
* 解析SQL语句(后面有文件结束符号)
*/
final public SqlNode SqlStmtEof() throws ParseException {
SqlNode stmt;
stmt = SqlStmt();
jj_consume_token(0);
{if (true) return stmt;}
throw new Error("Missing return statement in function");
}
//note: 解析 SQL statement
final public SqlNode SqlStmt() throws ParseException {
SqlNode stmt;
switch ((jj_ntk==-1)?jj_ntk():jj_ntk) {
...
case UNICODE_QUOTED_IDENTIFIER:
stmt = OrderedQueryOrExpr(ExprContext.ACCEPT_QUERY);
break;
...
}
...
}
示例中 SQL 经过前面的解析之后,会生成一个 SqlNode,这个 SqlNode 是一个 SqlOrder 类型,如下debug:
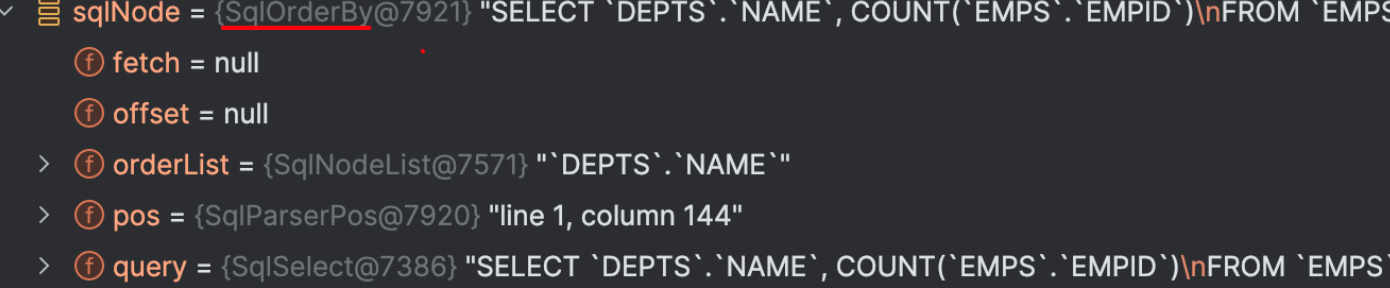
?
Step2: SqlNode 验证(SqlNode–>SqlNode)
生成的 SqlNode 对象是一个未经验证的抽象语法树,下面就进入了一个语法检查阶段,语法检查前需要知道元数据信息,这个检查会包括表名、字段名、函数名、数据类型的检查。
demo代码
//2. Validate: the tree
SqlNode sqlNodeValidated = planner.validate(sqlNode);
?
源码
org.apache.calcite.prepare.PlannerImpl
public SqlNode validate(SqlNode sqlNode) throws ValidationException {
// 状态检查
ensure(State.STATE_3_PARSED);
//构建检查器:
//createCatalogReader实例:用于封装元数据,以及获取元数据的方法
this.validator = createSqlValidator(createCatalogReader());
。。。
//检查
validatedSqlNode = validator.validate(sqlNode);
。。。
//更新状态
state = State.STATE_4_VALIDATED;
return validatedSqlNode;
}
校验逻辑总体有如下步骤:
- 元数据封装到 CatalogReader 对象,以便能够通过对象方法获取到元数据。
- 创建SqlValidator对象,提供检验能力。
- 进行校验。
?
1. 注册元数据
Calcite 本身是不管理和存储元数据的,在检查之前,需要先把元信息注册到 Calcite 中,本例是通过ReflectiveSchema 注册元数据
demo代码
// Build the schema
SchemaPlus rootSchema = Frameworks.createRootSchema(true);
//将HrSchemaMin对象封装为schema。
ReflectiveSchema schema = new ReflectiveSchema(new HrSchemaMin());
// 将schema注册为HR
SchemaPlus hr = rootSchema.add("HR", schema);
ReflectiveSchema通过反射的原理获取表的字段、表名等信息
//父类:
org.apache.calcite.schema.impl.AbstractSchema
protected Map<String, Table> getTableMap() {
return ImmutableMap.of();
}
public final Set<String> getTableNames() {
return getTableMap().keySet();
}
public final Table getTable(String name) {
return getTableMap().get(name);
}
//ReflectiveSchema 实现类
org.apache.calcite.adapter.java.ReflectiveSchema
...
private Map<String, Table> createTableMap() {
final ImmutableMap.Builder<String, Table> builder = ImmutableMap.builder();
//字段映射
for (Field field : clazz.getFields()) {
final String fieldName = field.getName();
final Table table = fieldRelation(field);
if (table == null) {
continue;
}
builder.put(fieldName, table);
}
Map<String, Table> tableMap = builder.build();
。。。
return tableMap;
}
?
2. 语法检查验证
语法检查验证是通过 SqlValidatorImpl 的 validate() 方法进行操作的,其实现如下:
org.apache.calcite.sql.validate.SqlValidatorImpl
public SqlNode validate(SqlNode topNode) {
SqlValidatorScope scope = new EmptyScope(this);
scope = new CatalogScope(scope, ImmutableList.of("CATALOG"));
final SqlNode topNode2 = validateScopedExpression(topNode, scope);
final RelDataType type = getValidatedNodeType(topNode2);
Util.discard(type);
return topNode2;
}
主要的实现是在 validateScopedExpression() 方法中,其实现如下
private SqlNode validateScopedExpression(
SqlNode topNode,
SqlValidatorScope scope) {
//note: 1. rewrite expression,将其标准化,便于后面的逻辑计划优化
SqlNode outermostNode = performUnconditionalRewrites(topNode, false);
cursorSet.add(outermostNode);
top = outermostNode;
TRACER.trace("After unconditional rewrite: {}", outermostNode);
//note: 2. Registers a query in a parent scope.
//note: register scopes and namespaces implied a relational expression
if (outermostNode.isA(SqlKind.TOP_LEVEL)) {
registerQuery(scope, null, outermostNode, outermostNode, null, false);
}
//note: 3. catalog 验证,调用 SqlNode 的 validate 方法,
outermostNode.validate(this, scope);
if (!outermostNode.isA(SqlKind.TOP_LEVEL)) {
// force type derivation so that we can provide it to the
// caller later without needing the scope
deriveType(scope, outermostNode);
}
TRACER.trace("After validation: {}", outermostNode);
return outermostNode;
}
它的处理逻辑主要分为三步:
- rewrite expression,将其标准化,便于后面的逻辑计划优化;
- 注册 relational expression 的 scopes 和 namespaces(这两个对象代表了其元信息);
- 进行相应的验证,这里会依赖第二步注册的 scopes 和 namespaces 信息。
?
3. registerQuery
这里的功能主要就是将元数据转换成 SqlValidator 内部的对象进行表示,也就是 SqlValidatorScope 和 SqlValidatorNamespace 两种类型的对象:
- SqlValidatorNamespace:a description of a data source used in a query,它代表了 SQL 查询的数据源,它是一个逻辑上数据源,可以是一张表,也可以是一个子查询;
- SqlValidatorScope:describes the tables and columns accessible at a particular point in the query,代表了在某一个程序运行点,当前可见的字段名和表名。
?
4. validate 验证
接着回到最复杂的一步,就是 outermostNode 实例调用 validate(this, scope) 方法进行验证的部分,对于此示例,这里最后调用的是 SqlSelect 的 validate() 方法,如下所示:
SqlSelect
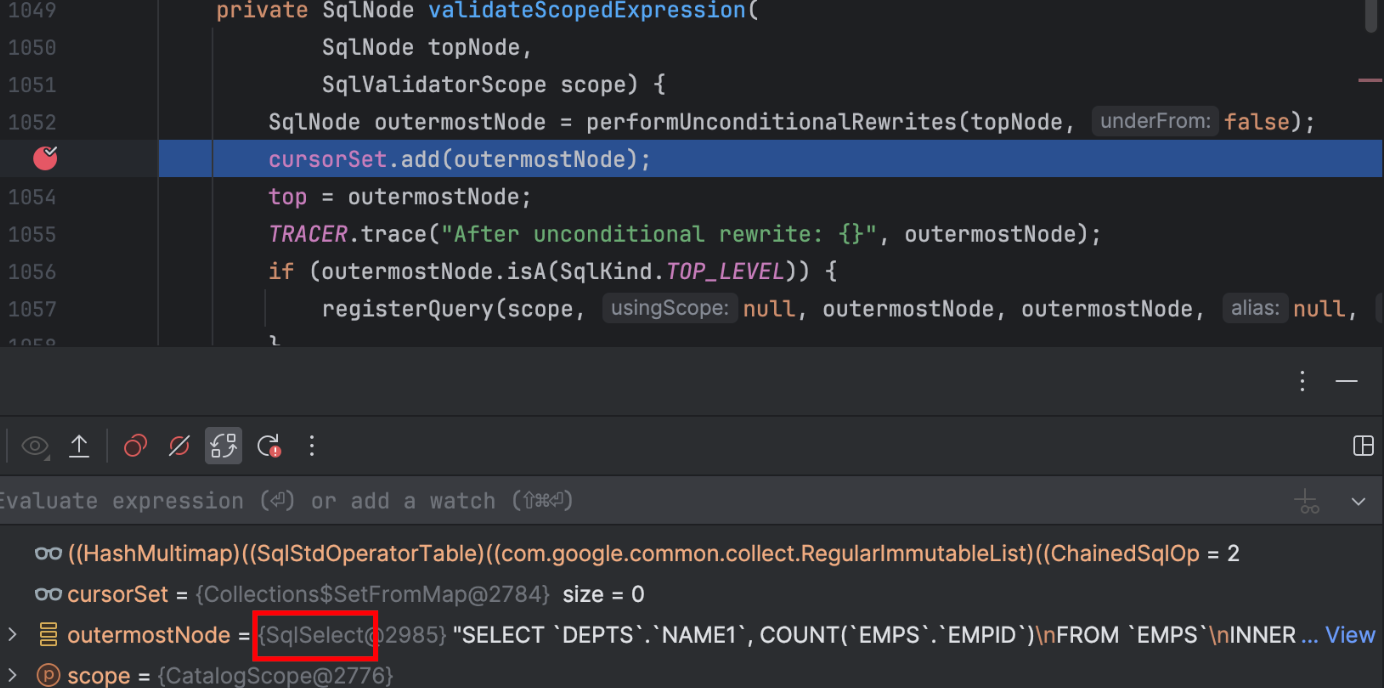
public void validate(SqlValidator validator, SqlValidatorScope scope) {
validator.validateQuery(this, scope, validator.getUnknownType());
}
它调用的是 SqlValidatorImpl 的 validateQuery() 方法
public void validateQuery(SqlNode node, SqlValidatorScope scope,
RelDataType targetRowType) {
final SqlValidatorNamespace ns = getNamespace(node, scope);
...
//验证Namespace
validateNamespace(ns, targetRowType);
。。。
//验证Modality
if (node == top) {
validateModality(node);
}
//validateAccess
validateAccess(
node,
ns.getTable(),
SqlAccessEnum.SELECT);
//validateSnapshot
validateSnapshot(node, scope, ns);
}
最后验证方法的实现是 SqlValidatorImpl 的 validateSelect() 方法,其调用过程如下图所示:
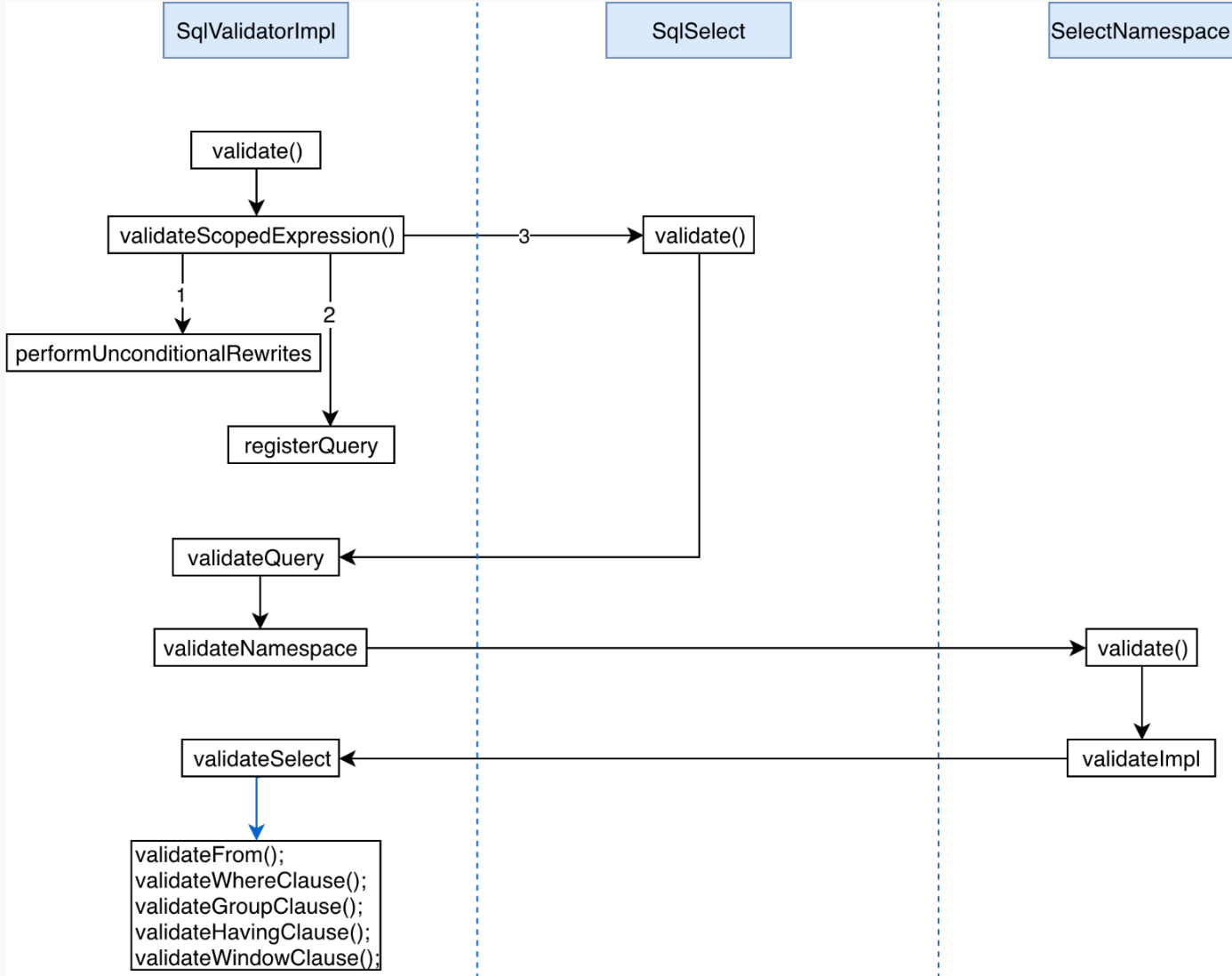
?
Step3: 转换为关系代数表达式(SqlNode–>RelNode/RexNode)
接下来这一步就是将 SqlNode 转换成 RelNode/RexNode,也就是生成相应的逻辑计划(Logical Plan),demo实例如下:
// Convert the sql tree to a relation expression
RelRoot relRoot = planner.rel(sqlNodeValidated);
具体源码步骤:
org.apache.calcite.prepare.PlannerImpl
public RelRoot rel(SqlNode sql) throws RelConversionException {
ensure(State.STATE_4_VALIDATED);
assert validatedSqlNode != null;
//1. 初始化rexBuilder
final RexBuilder rexBuilder = createRexBuilder();
//2. 初始化 RelOptCluster
final RelOptCluster cluster = RelOptCluster.create(planner, rexBuilder);
//3. 初始化 sqlToRelConverter
final SqlToRelConverter.Config config = SqlToRelConverter.configBuilder()
.withConfig(sqlToRelConverterConfig)
.withTrimUnusedFields(false)
.build();
final SqlToRelConverter sqlToRelConverter =
new SqlToRelConverter(this, validator,
createCatalogReader(), cluster, convertletTable, config);
//4. 进行转换
root =
sqlToRelConverter.convertQuery(validatedSqlNode, false, true);
root = root.withRel(sqlToRelConverter.flattenTypes(root.rel, true));
final RelBuilder relBuilder =
config.getRelBuilderFactory().create(cluster, null);
root = root.withRel(
RelDecorrelator.decorrelateQuery(root.rel, relBuilder));
state = State.STATE_5_CONVERTED;
return root;
}
主要的逻辑在于
//4. 进行转换
root =
sqlToRelConverter.convertQuery(validatedSqlNode, false, true);
SqlToRelConverter 中的 convertQuery() 将 SqlNode 转换为 RelRoot,其实现如下:
org.apache.calcite.sql2rel.SqlToRelConverter
public RelRoot convertQuery(
SqlNode query,
final boolean needsValidation,
final boolean top) {
...
// 转换为RelNode(relational expression)
RelNode result = convertQueryRecursive(query, top, null).rel;
。。。
//对转换前后的 RelDataType 做验证
checkConvertedType(query, result);
...
return RelRoot.of(result, validatedRowType, query.getKind())
.withCollation(collation)
.withHints(hints);
}
主要转换逻辑
org.apache.calcite.sql2rel.SqlToRelConverter
protected RelRoot convertQueryRecursive(SqlNode query, boolean top,
RelDataType targetRowType) {
final SqlKind kind = query.getKind();
switch (kind) {
case SELECT:
return RelRoot.of(convertSelect((SqlSelect) query, top), kind);
case INSERT:
return RelRoot.of(convertInsert((SqlInsert) query), kind);
....
throw new AssertionError("not a query: " + query);
}
}
调用
case SELECT:
return RelRoot.of(convertSelect((SqlSelect) query, top), kind);
// 将一个 Select parse tree 转换成一个关系表达式
public RelNode convertSelect(SqlSelect select, boolean top) {
final SqlValidatorScope selectScope = validator.getWhereScope(select);
final Blackboard bb = createBlackboard(selectScope, null, top);
convertSelectImpl(bb, select);//note: 做相应的转换
return bb.root;
}
这部分方法调用过程是:
convertQuery -->
convertQueryRecursive -->
convertSelect -->
convertSelectImpl -->
convertFrom & convertWhere & convertSelectList
到这里 SqlNode 到 RelNode 过程就完成了,调用如下代码打印逻辑计划:
// Explain, print the relational expression
RelNode relNode = relRoot.project();
final RelWriter relWriter = new RelWriterImpl(new PrintWriter(System.out), SqlExplainLevel.EXPPLAN_ATTRIBUTES, false);
relNode.explain(relWriter);
LogicalSort(sort0=[$0], dir0=[ASC])
LogicalProject(NAME=[$1], EXPR$1=[$2])
LogicalAggregate(group=[{0, 1}], EXPR$1=[COUNT()])
LogicalProject(deptno0=[$5], NAME=[$6], empid=[$0])
LogicalFilter(condition=[>($0, 5)])
LogicalJoin(condition=[=($1, $5)], joinType=[inner])
LogicalTableScan(table=[[HR, emps]])
LogicalTableScan(table=[[HR, depts]])
从下往上看
?
Step4: 优化阶段(RelNode–>RelNode)
第四阶段是 Calcite 的核心所在,优化器进行优化的地方,前面 sql 中有一个明显可以优化的地方就是过滤条件的下压(push down),在进行 join 操作前,先进行 filter 操作,这样的话就不需要在 join 时进行全量 join,减少参与 join 的数据量。
?
关于filter 操作下压,在 Calcite 中已经有相应的 Rule 实现,即FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN,这里使用 HepPlanner 作为示例的 planer,并注册 FilterIntoJoinRule 规则进行相应的优化。demo代码如下:
HepProgramBuilder builder = new HepProgramBuilder();
builder.addRuleInstance(FilterJoinRule.FilterIntoJoinRule.FILTER_ON_JOIN); //note: 添加 rule
HepPlanner hepPlanner = new HepPlanner(builder.build());
hepPlanner.setRoot(relNode);
relNode = hepPlanner.findBestExp();
relNode.explain(relWriter);
优化后的逻辑计划
LogicalSort(sort0=[$0], dir0=[ASC])
LogicalProject(NAME=[$1], EXPR$1=[$2])
LogicalAggregate(group=[{0, 1}], EXPR$1=[COUNT()])
LogicalProject(deptno0=[$5], NAME=[$6], empid=[$0])
LogicalJoin(condition=[=($1, $5)], joinType=[inner])
LogicalFilter(condition=[>($0, 5)])
LogicalTableScan(table=[[HR, emps]])
LogicalTableScan(table=[[HR, depts]])
从下往上看
?
在 Calcite 中,提供了两种 planner:HepPlanner 和 VolcanoPlanner
HepPlanner
特点(来自 Apache Calcite介绍):
- HepPlanner is a heuristic optimizer similar to Spark’s optimizer,与 spark 的优化器相似,HepPlanner 是一个 heuristic 优化器;
- Applies all matching rules until none can be applied:将会匹配所有的 rules 直到一个 rule 被满足;
- Heuristic optimization is faster than cost- based optimization:它比 CBO 更快;
- Risk of infinite recursion if rules make opposing changes to the plan:如果没有每次都不匹配规则,可能会有无限递归风险;
VolcanoPlanner
特点(来自 Apache Calcite介绍):
- VolcanoPlanner is a cost-based optimizer:VolcanoPlanner是一个CBO优化器;
- Applies matching rules iteratively, selecting the plan with the cheapest cost on each iteration:迭代地应用 rules,直到找到cost最小的plan;
- Costs are provided by relational expressions;
- Not all possible plans can be computed:不会计算所有可能的计划;
- Stops optimization when the cost does not significantly improve through a determinable number of iterations:根据已知的情况,如果下面的迭代不能带来提升时,这些计划将会停止优化;
?
四. 总结
Calcite 本身的架构比较好理解,但是具体到代码层面就不是那么好理解了,它抛出了很多的概念,入门的门槛确实高一些,但是当这些流程梳理清楚之后,其实再回头看,也没有多少东西,在生产中用的时候主要也是针对具体的业务场景扩展相应的 SQL 语法、进行具体的规则优化。
Calcite 架构设计得比较好,其中各个组件都可以单独使用,Rule(规则)扩展性很强,用户可以根据业务场景自定义相应的优化规则,它支持标准的 SQL,支持不同的存储和计算引擎,目前在业界应用也比较广泛,这也证明其牛叉之处。
?
参考:
https://matt33.com/2019/03/07/apache-calcite-process-flow/
https://github.com/gerardnico/calcite
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!