使用YOLOv8和Grad-CAM技术生成图像热图
目录
yolov8导航
????????如果大家想要了解关于yolov8的其他任务和相关内容可以点击这个链接,我这边整理了许多其他任务的说明博文,后续也会持续更新,包括yolov8模型优化、sam等等的相关内容。
YOLOv8(附带各种任务详细说明链接)
概述
????????在深度学习和计算机视觉的领域,了解模型如何解读图像是至关重要的。本文将介绍如何使用YOLOv8模型结合Grad-CAM(梯度加权类激活映射)技术生成图像的热图。这种方法可以帮助我们可视化和理解模型在图像识别过程中关注的区域。后续我会把源码的下载链接附到最后。
环境准备
????????首先,确保您的环境中已安装以下库:torch, yaml, cv2, numpy, matplotlib, PIL, tqdm,以及ultralytics和pytorch_grad_cam。这些库对于运行和理解接下来的代码至关重要。
代码解读
导入库
import warnings
warnings.filterwarnings('ignore') # 忽略警告,保持输出清洁
# 导入必要的库
import torch, yaml, cv2, os, shutil
import numpy as np
np.random.seed(0) # 设置随机种子
import matplotlib.pyplot as plt
from tqdm import trange
from PIL import Image
# 导入YOLOv8和Grad-CAM相关的库
from ultralytics.nn.tasks import RTDETRDetectionModel as Model
from ultralytics.utils.torch_utils import intersect_dicts
from ultralytics.utils.ops import xywh2xyxy
from pytorch_grad_cam import GradCAMPlusPlus, GradCAM, XGradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image
from pytorch_grad_cam.activations_and_gradients import ActivationsAndGradients
?定义letterbox函数
????????这段代码定义了一个名为 letterbox 的函数,它主要用于调整图像大小和进行填充处理,以便使图像适配于深度学习模型的输入要求。现在我将详细解释这个函数的每一部分:?
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32):
im: 输入图像。new_shape: 目标图像的新尺寸,默认为 640x640。color: 用于边缘填充的颜色,默认为灰色(114, 114, 114)。auto: 是否自动调整填充大小以满足步长约束。scaleFill: 是否拉伸图像以填充新形状。scaleup: 是否允许放大图像。stride: 模型步长,用于确保输出尺寸是该数值的倍数。
?调整尺寸和比例
shape = im.shape[:2] # 当前图像的形状 [高度, 宽度]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# 计算缩放比例 (新尺寸 / 旧尺寸)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # 仅缩小图像,不放大(为了更好的验证mAP)
r = min(r, 1.0)
?????????这部分代码首先获取图像的原始尺寸,然后根据new_shape和原始尺寸计算缩放比例。
计算填充
ratio = r, r # 宽度、高度比例
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # 宽高填充
if auto: # 最小矩形
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # 宽高填充
elif scaleFill: # 拉伸填充
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # 宽度、高度比例
?????????这段代码计算了在缩放后的图像周围需要添加多少填充,以达到目标尺寸。auto模式下,填充被调整以满足步长约束。scaleFill模式下,图像被拉伸以填充整个目标尺寸。
应用填充
dw /= 2 # 将填充分成两边
dh /= 2
if shape[::-1] != new_unpad: # 如果需要调整大小
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # 添加边框
????????最后,这部分代码将计算出的填充应用到图像上。首先,如果需要,会将图像缩放到new_unpad指定的尺寸。接着,使用cv2.copyMakeBorder函数在图像的四周添加计算出的填充。?然后直接定义返回值:return im, ratio, (dw, dh)?函数返回调整大小并填充后的图像,以及相关的缩放比例和填充维度。
?????????letterbox函数是深度学习中常用的图像预处理手段之一。它通过调整图像的尺寸和添加填充,确保图像能够适配神经网络的输入要求,同时保持了图像的原始比例,避免了可能的形变。这在目标检测等需要精确空间定位的任务中尤为重要。
yolov8_heatmap类定义和初始化
class yolov8_heatmap:
def __init__(self, weight, cfg, device, method, layer, backward_type, conf_threshold, ratio):
...
- 初始化函数接收多个参数,包括模型权重(
weight)、配置文件(cfg)、运行设备(device)、Grad-CAM方法(method)、目标层(layer)、反向类型(backward_type)、置信度阈值(conf_threshold)和处理比例(ratio)。 - 加载YOLOv8模型,并根据提供的配置和权重设置模型。
- 随机生成颜色映射,用于不同类别的可视化。
- 初始化的参数被存储在类的属性中。
后处理函数?
def post_process(self, result):
...
post_process函数处理模型的输出。它将模型输出分离为逻辑值(logits_)和边界框(boxes_)。- 该函数还对输出进行排序,并转换边界框格式。
?绘制检测结果
def draw_detections(self, box, color, name, img):
...
draw_detections函数用于在图像上绘制检测到的边界框和类别名称。- 它调整边界框大小以适应原始图像尺寸,并在图像上绘制边界框和类别名称。
?类的调用函数
def __call__(self, img_path, save_path):
...
- 当实例被当作函数调用时,执行图像处理和热图生成的主要流程。
- 加载并预处理图像,将其转换为模型可以处理的格式。
- 使用
ActivationsAndGradients对象从指定的层中获取激活和梯度。 - 使用Grad-CAM方法生成热图,这涉及到计算重要性权重和应用它们到激活图上。
- 将生成的热图叠加到原始图像上,并保存结果。
热图生成细节?
- 类的核心功能是使用Grad-CAM技术从指定层生成热图。
- 根据
backward_type,可以选择对类别、边界框或两者进行反向传播,以生成针对不同目标的热图。 - 生成的热图反映了模型在做出预测时关注图像的哪些区域。
参数解释
def get_params():
params = {
'weight': 'rtdetr-l.pt',
'cfg': 'ultralytics/cfg/models/rt-detr/rtdetr-l.yaml',
'device': 'cuda:0',
'method': 'GradCAM', # GradCAMPlusPlus, GradCAM, XGradCAM
'layer': 'model.model[10]',
'backward_type': 'all', # class, box, all
'conf_threshold': 0.3, # 0.3
'ratio': 0.5 # 0.5-1.0
}
return params?????????这段代码定义了一个名为 get_params 的函数,它用于设置并返回一个字典,包含了一系列参数,这些参数是用于配置和运行 yolov8_heatmap 类的。现在我将逐个解释这些参数的含义和作用:
weight
'rtdetr-l.pt': 这个参数指定了模型的权重文件。在这种情况下,它是一个预先训练的YOLOv8模型的权重文件。这个文件包含了模型的所有训练参数,是模型运行的基础。
cfg
'ultralytics/cfg/models/rt-detr/rtdetr-l.yaml': 这是模型的配置文件路径。配置文件定义了模型的架构和其他相关设置。这里指定的是使用YOLOv8模型的具体配置。
device
'cuda:0': 这个参数指定了模型运行的设备。在这里,'cuda:0'表明模型将在第一个NVIDIA GPU上运行。如果没有GPU或希望在CPU上运行,可以将其更改为'cpu'。
method
'GradCAM': 此参数指定了用于生成热图的Grad-CAM(梯度加权类激活映射)变体。'GradCAM'是一种常用的方法,其他选项如'GradCAMPlusPlus'和'XGradCAM'提供了不同的热图生成算法。
layer
'model.model[10]': 这个参数指定了用于生成热图的网络层。'model.model[10]'指的是YOLOv8模型中的特定层。选择的层会影响热图的细节和质量。
backward_type
'all': 这个参数决定了反向传播的类型。它可以是'class'、'box'或'all'。'class'仅关注类别预测,'box'仅关注边界框预测,而'all'结合了两者。
conf_threshold
0.3: 这是一个置信度阈值,用于过滤模型的预测。仅当模型对其预测的置信度高于0.3时,这些预测才会被考虑。
ratio
0.5: 这个参数指定了在生成热图时考虑的顶部预测的比例。0.5表示只考虑置信度最高的50%的预测。
热力图解读
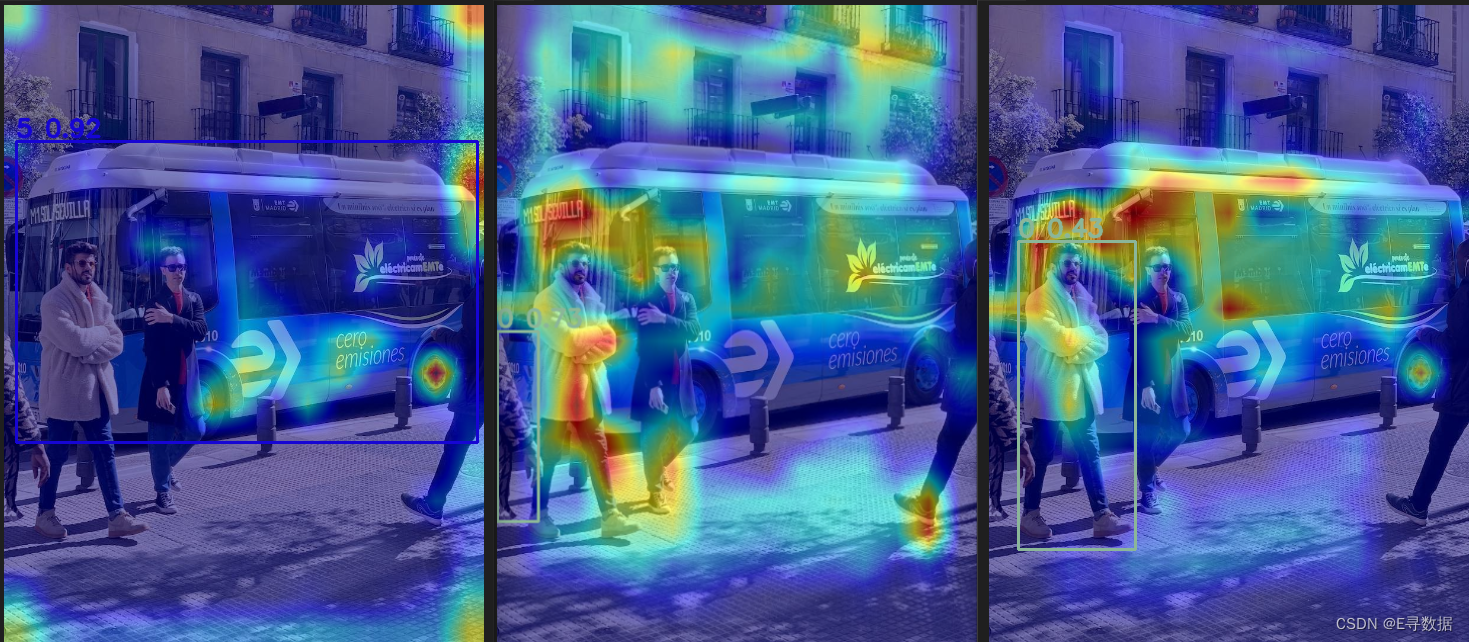
-
颜色解释:
- 热图中的颜色通常代表一个量级的标量,其中热色调(如红色、黄色)表示高活跃度或高重要性区域,冷色调(如蓝色、绿色)表示低活跃度或低重要性区域。
-
区域关注:
- 热图上明亮的区域表明了模型在做出预测或决策时,这些区域对模型的输出贡献度较高。例如,在目标检测任务中,如果热图中某个物体的轮廓区域亮度很高,这可能意味着模型正将注意力集中在这个物体上。
-
模型解释性:
- 热图可以用来理解和解释模型的行为。例如,在图像分类任务中,热图可以显示模型认为图像的哪些部分对于识别特定类别最重要。
程序源码下载地址
计算机视觉YOLOv8模型热图可视化工具
????????如果有哪里写的不够清晰,小伙伴本可以给评论或者留言,我这边会尽快的优化博文内容,另外如有需要,我这边可支持技术答疑与支持。另外这个程序并非我的原创,如有侵权告知必删。?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!