51-12 多模态论文串讲—BLIP 论文精读
视觉语言预训练VLP模型最近在各种多模态下游任务上获得了巨大的成功,目前还有两个主要局限性:
(1)?模型角度: 大多数方法要么采用encoder模型,要么采用encoder-decoder模型。然而,基于编码器的模型不太容易直接转换到文本生成任务(如图像字幕),而编码器-解码器模型尚未成功用于图像文本检索任务。
(2)?数据角度:?如CLIP、ALBEF等从web上收集到的图文对上进行预训练,目前用有噪声的网络文本训练效果是次优的。
为此,作者提出了BLIP: 引导语言图像预训练,以实现统一的视觉语言理解和生成。BLIP是一个新的VLP框架,与现有方法相比,它可以实现更广泛的下游任务。它分别从模型和数据角度有两个贡献:
(1) 多模态编码器-解码器混合(MED):一种用于有效多任务预训练和灵活迁移学习的新模型架构。MED可以作为单模态编码器、基于图像的文本编码器或基于图像的文本解码器工作。该模型与三个视觉语言目标联合预训练:图像文本对比学习、图像文本匹配和图像条件语言建模。
(2) CapFilter:一种新的数据集增强方法,用于从噪声图像-文本对中学习。作者将预先训练的MED分为两个模块: 一个Captioner,用于生成给定web图像匹配的文本,以及一个Filter,用于从原始web文本和合成文本中删除嘈杂的文本。
BLIP,用这个Capfilter去生成更多更好的这个数据,然后给别的模型做训练用。你可以拿这个数据去训练VLMo,训练CoCA,训练BEiT3,去训练各种各样的多模的模型,因为它的目的,就是生成更好的数据。BLIP未来是一个非常通用的工具。
大家好,我们今天就接着上次多模态串讲,来说一说最近使用transformer encoder和decoder的一些方法。我们要过的第一篇论文叫做BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation。题目中,有两个关键词,一个就是bootstrapping,另一个就是unified,也就他们这篇文章的两个贡献点。第一个bootstrapping,其实是从数据集角度出发的,他是说,如果你有一个从网页上爬下来的,很嘈杂的数据集。这时候,你先用它去训练一个模型,接下来,你再通过一些方法,去得到一些更干净的数据,然后再用这些更干净的数据,能不能串出更好的模型。那第二个贡献点,其实就从后面来看就非常明了,也就是这两个方向,一个是understanding,也就是Image Text Retrieval,方向,即VQA,VR,VE这些。还有就是Generation这种生成任务,譬如这些Image Captioning图像生成字幕这种任务。作者团队,全部来自于salesforce research,是我们上次讲过ALBEF那篇论文的原班人马。我们一会儿也可以看到,这篇论文它的模型,也有很多ALBEF的影子,而且它里面也用了很多ALBEF的训练技巧。
那接下来,我们直接进入引言部分,看看这篇文章的研究动机到底是什么。BLIP的引言,写的非常清晰,他上来就告诉你,我的研究动机,有两个部分,一个是从这个模型角度出发,一个是从数据角度出发。从模型上,作者说,最近的一些方法,他要么,就是用了Transformer encoder的一些模型,这里举的这个CLIP,还有他们自己的ALBEF。另外一条路,就是用了这种编码器解码器,Encoder,Decoder的结构,比如说后面这个,就是SimVLM。虽然说方法都有,但是作者这里说这种encoder only的模型,它没法很直接的用到这种text generation的任务去,比如说这是图像生成字幕。因为它只有编码器,没有解码器,那它用什么去生成?当然也不是完全不行,但就是说不够直接肯定你要杂七杂八的再加一些模块,才能让他去做这种generation的任务。那对于encoder,decoder模型来说,它虽然有了decoder,它虽然可以去做这种生成的任务。但是反过来,因为没有一个统一的框架,所以说它又不能直接的被用来做这种image text retrieval的任务。那我们读到这儿,其实发现,作者这里这个研究动机,跟我们上次讲的那个VLMo是完全一样的。都是说现有的框架,A可以干什么,不能干什么,B可以干什么不能干什么,但是这两条方向,都不能一个人把所有的活都干了。所以如何能提出一个unified,一个统一的框架。用一个模型,把所有的任务都解决,那该多好。那接下来,我们很快就可以看到,其实BLIP这篇论文,就是利用了很多VLMo的想法,把他的模型,设计成了一个很灵活的框架。从而构造了这么一个unified framework。那另外一个研究动机,就是说数据层面。作者说,目前,这是表现出色的这些方法,比如说clip。他们都是在大规模的,这种上爬下的非常noisy的数据集上,也就是这种上去预训练模型的。虽然说当你有足够多足够大的数据集的时候,它能够弥补一些,这些嘈杂数据集带来的影响,也就是说,你通过这个把这个数据集变大,你还是能够得到非常好的这个性能的提升的。但是,BLIP这篇论文就告诉你,使用这种noisy的数据集区域训练,还是不好的,它是一个sub optimal,不是最优解。那如何能够有效的去clean这个nosiy的data set,如何能够让模型更好的去利用数据的这个图像文本配对信息?在这篇论文里,作者就提出了这个captioner和filter这么一个module。Captioner的作用,就是说我给定任意一张图片,我就用这个captioner,去生成一些这个字幕。这样,我就会得到大量的这个合成数据synthetic data。然后同时,我再去训练这么一个filter model,它的作用,就是把那些图像和文本不匹配的对,都从这个数据集里删掉。

比如说在这个例子里,这就是一个巧克力蛋糕吧,那原来从网上直接扒下的这个图像文本里的文本?写的是blue sky bakery in sunset park。就是说一家位于这个日落公园,叫蓝天的蛋糕店,那我们可以很明显的看出来,这个图文,其实是完全不匹配的。那我们上次也提过,之所以他这个文本是这样,其实是因为有利于这个搜索引擎去搜索,因为大家看到这个蛋糕的图片之后,更想做的,是去知道这家蛋糕店在哪儿,我怎么能去买到这家蛋糕店。这样,搜索引擎才能收广告挣钱,这个蛋糕店的店主,也能得到更多的客流量。所以大部分你爬下来的那些数据集,不论你爬了几百万,几千万,上亿的图片文本,对里面大部分,都是这种不匹配的,Noisy的文本对。那我们这个时候可以看到,作者训练的这个captainer这个模型,它其实可以生成非常非常有描述性的这个文本。那所以在接下来,他们训练的这个filter模型来看,他们就会选择这个图像文本对去进行模型的训练,而不用原来的那个真实的图形文本去进行训练。
那快速过完了引言中的研究动机,接下来,我们废话不多说,直接来看文章的图二,看一下,整体的这个模型结构。
那在看图二之前,我想再回顾一下上一期讲的两个方法。因为之前我们说过,ALBEF提出,就是ViLT在和CLIP一系列工作之前的这个经验总结上得到。那我们今天要讲的这个BLIP,是不是也能用之前的经验总结而得到?那答案,是肯定的。
我们首先来看ALBEF的模型,分成三个结构,一个是这个视觉编码器,一个是文本编码器,还有一个是多模态编码器。
|
|
|

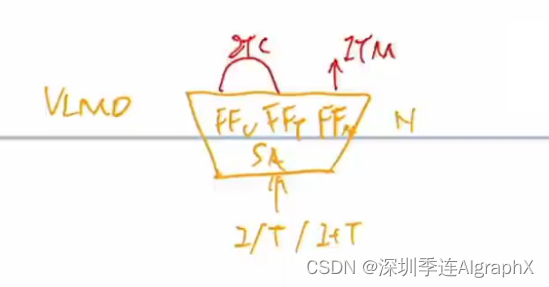
对于图像这端来说,就是一个图像,进入这个encoder,它一共有N层。然后一个文本,进入这个文本的编码器,它有L层。然后在得到对应的这个图像文本特征之后,他先做一个ITC这个对比学习的loss,去把图像和文本分别的这个特征好。然后,文本特征,继续进入这个self attention layer去学,然后图像特征,通过一个cross attention layer进来,然后文本特征去进行融合。然后经历了N-L层的这个多模态的编码器之后,最后得到了多模态的那个特征。然后最后,用这个多模态的特征去做这个image text matching任务,从而去训练更好的模型。
那为什么文本这端,要把一个N层的transform encoder硬生生的劈成L层和N-L层?至于作者,还想大概维持这个计算量不变,就是跟clip一样,左边一个12层的,右边也是一个12层的。他不想增加更多过量的这个多模态融合这部分的计算量。但是,多模态这一部分又特别的重要,然后相对而言,文本这端不那么重要,所以他就把这边12层的计算量,给分成了两部分。
但是同样的问题,VLMo是怎么解决的?VLMo觉得,你这样劈来劈去太麻烦了,而且也不够灵活。那我们现在来设计一个这个MoE这种网络,让它变得极其的灵活,就是说我只有一个网络。我的这个self attention层,全都是共享参数。我唯一根据模态不同而改变的地方,就是这个Feed Forward Netwrok FFN,我这个Feed Forward text,FF vision,FF modality。我用这个地方,去区别不同的modality,去训练不同的expert。这样,我就用统一的一个模型,就是在训练的时候是一个模型,但是我在做推理的时候,我可以根据不同的这个任务,去选择这个模型中的某一部分去做推理。而且这篇论文,用实验,大量的实验证明了这个self attention层,确实是可以共享参数的,它跟这个模态没什么关系。那大家一旦收到这个信号之后,肯定还是觉得VLMo这个结构更简单,至少直观上看起来更简单更优雅,所以说,结合了ALBEF和VLMo,作者就推出了BLIP这个模型。
我们先大体从粗略上来看一下。
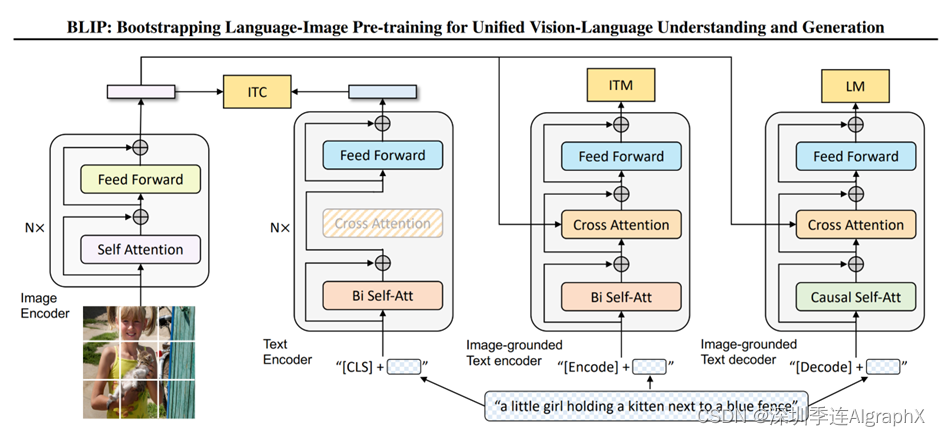
这个模型,包含了四个部分。
一个,就是图像这边,它有一个完整的VIT的模型,一个N层的VIT模型,而且是非常标准的self attention,FFN。然后文本这边,它有三个模型。分别用来算三个不同的这个目标函数。这个,就跟VLMo已经非常像了,它根据你这个输入模态的不同,它根据你这个目标函数的不同,去选择一个大模型里不同的部分,去做这个模型的forward。那对于第一个文本模型来说,这里面它也是N层,而不像ALBEF里的L层了。它的目的,是根据你输入的文本,去做这么一个understanding,去做这么一个分类的任务,所以说当得到了这个文本特征之后,他就去跟这个视觉特征,去做ITC loss。那第二个文本模型,作者这里说,它叫image grounded text encoder,就是它是一个多模态的编码器。它这里,是借助了图像的信息,然后去完成一些多模态的任务,很显然那这个就是我们之前要做这个ITM loss。那这个时候其实我们发现,如果你把第3部分,直接放到图上面,其实它不就是ALBEF的网络结构吗。所以如果暂时我们先不看第三个这个文本编码器,其实左边这一部分,完完全全就是一个ALBEF。
但是他跟ALBEF有一点不同。就是他借鉴了VLMo,这个self attention层,是可以共享参数的。所以他就不需要把一个文本模型,P成两个部分去用了,他可以就用一个文本模型,但是,共享参数。所以这里我们也可以看到,作者说同样的颜色,代表同样的参数,就是共享参数的,它不是两个模型,那这里我们也可以看到,这个SA层,也是共享参数的。所以相当于,第一个文本编码器和第二个文本编码器,它基本就是一样的,它的这个SA和FF,全都是一致的,只不过第二个里头多了一个cross attention层,需要新去学习。那所以讲到这儿,也就回答了我们刚才的问题,我们确实可以通过看之前的方法,总结他们的经验,从而得到接下来的方法的这个大体的模型结构和创新点。
但是到这儿,我们会发现,目前的这个结构,它还是只能做这种VQA,VR,VE这种的任务,那怎么去做生成的任务,这个decoder在哪?
那有了VLMo这个想法之后,那一切就变得很简单了,对吧?如果你需要一个decoder,那就再加一个decoder不就完了吗?所以你就在后面,再加这么一个文本的decoder。但是,对于decoder来说,它的这个输入输出的形式,和尤其是第一层的这个self attention,是不太一样的。因为这个时候,他不能看到完整的这个句子,因为如果他已经看到完整的句子,他再去生成这个句子,那他肯定能100%生成出来这个句子,那就训练就没有难度了。那他必须像训练GPT模型一样,他把后面的这些句子,都挡住,都mask掉,他只通过前面的这些信息,去推测后面的句子到底长什么样,这才叫text generation。所以说,它的第一层用的是causal self attention,也就是因果关系的这个自注意力。就是你要去做一些这个因果推理,你要通过前面的这些文本,去推测后面的文本到底是什么。那因为这里,它做的是这种causal self attention,跟前面的这个self attention就不样,所以我们可以看到它这色是不一样,就是它俩是没办法共享数的。作者后面也做了实验,就是如果你硬要让他们去共享这个参数,这个性能是会下降。因为他确实是在做不同的任务。但是,除了第一层的这个自注意力之外,后面的这个cross attention和feed forward,它就跟前面,全都是共享参数的。所以说名义上,它新添加第三个这个text decoder,但事实上,参数量并没有增加多少,只是增加了一些causal的self attention。
最后的目标函数,就是用的GPT系的这种language model。也就是说给定一些词,还去预测剩下的那些词,这个叫language model。那对于MLM,也就是ALBEF和VLMo之前用的那个目标函数,那个是属于完形填空,就给一个句子,中间词扣掉,我去预测中间这个词。
所以说,LM和MLM其实是不一样的。
那在这篇论文里,因为作者要去做这种生成式的任务,所以更好的一个选择,是使用language model的目标函数。
那说到这儿,文章的模型部分,就基本已经说完了。
再来快速总结一下,就是说,对于图像,它就有一个VIT。但是对于文本来说,它对应了三个模型,分别是一个标准的这个text encoder,然后还有就是image grounded text encoder和image grounded text decoder。无论是encoder,还是decoder,模型的差距还是比较小的。譬如 image grounded text encoder,有一个新的cross attention。对image grounded text decoder呢,有一个causal的self attention。剩下的部分,其实基本都是共享参数的。然后就跟VLMo一样,当我们选择头两个模型的时候,我们就去算这个ITC loss。当我们选择第一个和第二个文本模型的时候,我们就去算ITM loss。
当我们选择第一个模型和第三个文本模型的时候,我们就去算这个LM loss。所以从目标函数角度来说,BLIP也是三个目标函数,头两个,跟ALBEF和VLMo都是一样的,只不过第三个从MLM换成LM。所以说,VLMo,BLIP推广的这一系列unified framework。虽然它不是真正意义上的,但确实是非常灵活,而且能把大部分的任务都融合到一个模型中来,大大加速了这个多模态学习的进展。
当然,文章中还有一些细节。比如对于三个文本模型来说,他们对应的这个token就不一样,第一个文本模型,就用的是cls token,第二个用的是encode token,第三个用的是decode token。
还有,就跟我们上次说的一样,这些模型都很难训练,训练的代价非常高,因为在做每一次这个trainning iteration的时候,图像端只需要做一次Forward,但其实文本端,在这里要做三次。要分别通过这三个模型,去得到对应的那个特征,然后去算对应的目标函数,所以还是非常费时间的。
另外,因为BLIP就是ALBEF的原班人马,所以说里面用到了很多ALBEF的技巧。譬如算ITC的时候,也用了momentum encoder动态蒸馏去做更好的knowledge distillation,也去做更好的这个数据的清理。同时,在算ITM loss的时候,也像ALBEF一样,利用ITC算的相似性去做Hard Negative mining,从而每次都用那个最难的负样本去算这个ITM,从而增加这个loss的有效性。总之,这就是BLIP的模型结构。文章中作者把这叫MED就是mixture of encoder and decoder,就是把编码和码混到一起了。那其实这个命名方式,跟VLMo也很像,VLMo提出的那个transformer block叫MoME,就是multimodality mixture of expert。BLIP不过就是把mixture of expert换成了mixture of encoder and decoder,但意思,都是一个意思。
那说完了模结构MED,下们讨论第二个贡献,也就是最重要的那个贡献CapFilter module。

他的出发点,或者研究动机,就是说,假如说你有很多这个数据集,这个D里面{(Iw,Tw)}+{(Ih,Th)},可能有一些网上爬下的数据集,可能有一些手工标注的数据集。当然了,像CLIP模型的训练,他就没有用这个手工标注的数据集,就只用从网上爬下来的那400m。但是有的时候,反正手工标注的数据集,比如说coco也是存在的,那不用白不用,所以有的人也会用。对所有的现有的这个数据D来说,它最大的问题就是说从网页上爬上的数据集,这个图片文本论不匹配,也就是说这里的这个Tw不好,所以作者这里用红色来表示。这个coco,手工标注的,他认为这个文本就一定匹配,所以用绿色来表示。然后作者这里的论点就是说,如果你用这种noisy的数据集,去预训练一个这个模型,它的效果就不是最好。
那如果我们想清理一下这个数据集,从而去达到这个最优解,该怎么做?
那很自然的,我就需要训练一个模型,这个模型,最好是能给我一些像图像文本之间这个相似度。那相似度高的,就说明匹配,相似度不高的,可能就不匹配,所以这也就是filter这个模块的由来。至于filter是怎么训练的?作者就是把已经提前预训练好的这个MED,也就是把已经训练好的这个BLIP模型拿出来。然后把那个图像模型和两个文本模型,就是分别做ITC,ITM模型拿来,然后又在coco数据集上,就是在干净的数据集上又去做了一些很快的微调。然后先训练出来的这个,就是微调过后的这个MED,就叫做这个Filter了。那接下来,他只要用这个模型,去算一下这个图像文本的这个相似度,尤其是这个image text match的这个分数,那他就知道到底这个像和文本是不是一个match了,那不是match,自然他就可以把它拿掉。所以通过这个filter,作者就把原始这个爬下来的noisy的It的文本,比如说这个红色的Tw,就变成了这个稍微一点这个图像文本,就是这个绿色的Tw了。
那其实到这里这个任务其实就已经完成了,对吧,那为什么作者还要再去加一个Captioner。
主要原因,我觉得还是因为作者在训练出来那个decoder之后,他发现,这个BLIP模型训练好的decoder真的是非常的强。它有时候生成的那个句子比原始的那个图像文本段要好很多。就即使原来的那个图像文本段是一个match,它俩是匹配的,但是我新生成的这个文本,更匹配,它的质量更高。所以作者就想说,那我就试试看对吧,那我用生成的这些文本,去充当新的训练数据集,会不会得到更好的模型?那其实这里,作者也是在coco这个数据集{(Ih,Th)}上,去把已经训练好的这个image-grounded text decoder,又去微调了一下,然后就得到了这个Captioner。e然后给定任意一张从网上爬下来的图片,然后他就用这个captioner,去给这个图片去生成新的字幕,也就是红色的这里的{I我,Ts}。当然Ts的质量,可高可低,这个完全是由模型来决定,有的时候就描述的特别好,那有的时候可能就是非常差,这个可能甚至都不make sense,所以作者这里,还是用红色去表示的,因为是synthetic data。那最后,通过captioner和filter,我们得到的数据集,就从原来的这个D{(Iw,Tw)}+{(Ih,Th)},就变成了现在这个D{(Iw,Tw)}+{(Iw,Ts)}+{(Ih,Th)},我们就会发现多了一项。就原来的那个CC12m,假如说我们用CC12m来做例子的话。这个{(Iw,Tw)},就是Filter过的CC12m,还是原来从网上爬下来的文本对,只不过filter了,变少了。那第二个这里的{(Iw,Ts)},就是CC12m合成的新生的这些像文本。然后接下来,如果你使用这个手工标注的,比如coco数据集,{(Ih,Th)},总之,你的数据集不仅变得更大了,而且质量变得更高了。
那这个时候,你再拿新的这个D,然后返回来,再去预训练一个BLIP模型。最后作者发现了BLIP模型的提升非常显著,而且还有很多有趣的应用。这个就是本文提出的第二个创新点,这个capfilter模型,从而做到了数据集上的这个bootstrapping。
那接下来,我们先看几张图,形象的了解一下这个capfilter模型到底有多强大。作者给了三个例子,上面的Tw,就是直接从网页端下载下来的那个文本,下面的这个Ts,就是他们的capfilter生成的文本。红色的,就代表被filter 掉的那些文本,绿色就代表filter以后保留下来的那个文本,也就是说跟图片更匹配的那个文本。

那现在我们来看一下第一个例子,看着像一个自然风光。
那原来从网上爬下来的,就是说在我家旁边,有一个桥上,可能照出来的这张图片。确实,也不能说不对,但是如果你看底下这个生成的这个句子,他说,在日落的时候,有一群鸟飞过了一个湖面,这个描述的简直是太精确了,把这个日落,湖和鸟全都包含在里面了,那如果你用这个图像文本段去训练模型,肯定训练出来的模型效果很好。因为语义是完全match上的。那我们再来看第三个例子,从网上爬下来的这个,说这是一个1180年建立的这么一个城堡,它是取代了九世纪的时候一个用木头做的一个城堡。但是这次的效果,就差强人意,也是对的,但是,他说这是一个很大的一个楼,上面有很多很多的窗户。那它就不够具体了,因为这里,这些有可能就是那些门洞,拱门,或而且整个,这就是一个castle,它不是一个大的building。所以这次,BLIP训练出来的这个filter就选择了上面,就原始的这个图片文本对。所以这里,我们不仅可以体会到,这个caption的强大之处,就你给定什么样的一张图,我都能给你生成比较reasonable的这个文本,同时,我们也能体会到这个filter的强大之处,就是我能够很准确的,从这个原始的文本和新生成的文本里去挑出来,哪个跟这个图像是更匹配的。所以我们看完这几个例子之后,我们就应该知道,Capfilter真的是把这个数据集清理的相当好了。
那这个时候我们再看上面这个图表,看到capfilter带来这个提升之后,我们也就不会再惊讶了。那接下来,我们就来看一下这个表一,就是一些主要的消融实验和主要的一些结果。

可以看到数据集大,模型越大,效果就越好。
那接下来,我们来看一下这篇文章独有的,这个caption filter模式,到底带来什么样的提升。
那这个C就代表caption,f就代表用了filter。我们第一个可以观察到的现象,就是说如果都不用,那这个结果肯定是最差的。然后不论是用了filter,还是用了这个captioner,效果都会有提升,而且比较神奇的,是用了captioner以后,这个提升是更加显著的,也就意味着说,这个captioner带来的这个data diversity,这种多样性是会更让这个模型受益的。
因为尤其是对大模型,或者大数据集的训练来说,你偶尔这个数据集有点noise,其实无所谓,模型都是能够handle的。但是,因为模型参数量太大,所以它非常非常的data hungry,它需要大量大量的数据,所以这个时候,你只要能生成更多更好的数据,它往往就能够受益。那最后,这个captioner和filter同时用,效果就达到最好了。当然这个,只是一个消融实验。
但是这个表格里,最最有意思,就是这两行B,B和L,L,都是打了这个对号,也就是说它都用了caption和filter。那为什么一个叫base,一个叫large。是因为,如果你回想我们这个bootstrapping的过程,它其实一个分阶段的训练,就跟VLMo一样分阶段,BLIP其实也是分阶段。他先是用嘈杂的数据集预训练的一个模型,这是训练stage one。然后这个时候,他用coco去fine tune captioner和filter,然后把数据集重新处理一遍,得到了一个新的更大的质量更好的数据集,这是stage two,然后第三个stage,就是他用这个新的数据集去又pre-train了一个blip。那这几个步骤,这三个stage,其实都是互不相干的,其实是可以分开训练或者分开使用的。所以作者这里的意思就是说,即使我的这个模型是VIT base,就我的模型可以很小,但是我在第二阶段生成这个新的数据集的时候,我可以用更大的这个模型,用更大的那个MED,更大的cap+filter模式,去生成更好质量更高的这个数据集。我并不一定说我这儿用的模型是base,我那个capfilter模型就一定要用base。生成数据这一步,完全是一个额外的步骤,完全是另外一步pseudo-label的过程,理论上我也可以用任何一种方式去生成这种pseudo-label。这个就很有意思,也就是说,理论上,你是可以拿训练出来的这个BLIP,这个capfilter去生成更好的这个数据,然后去给别的模型做训练用,你可以拿这个数据去训练VLMo,你也可以拿它去训练CoCA,训练BEiT3,去训练各种各样的多模的模型,因为它的目的,就是生成更好的数据。
所以BLIP是可以做一个非常通用的工具。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MyBatis 使用报错: Can‘t generate mapping method with primitive return type
- SpringSecurity6 | 失败后的跳转
- SpringBoot源码分析
- 谷粒商城-微服务架构图
- 网上购物推荐系统的设计与实现(JSP+java+springmvc+mysql+MyBatis)
- 机器学习: 初探 定义与应用场景
- 服务案例|CIS数据库故障问题
- IDC 23Q3 数据发布 XSKY 对象存储软件市场份额继续蝉联第一
- Unity 安装APK后出现两个图标问题
- 汽车发动机缸体缸盖自动化光学测量系统尺寸测量偏差检测-CASAIM品质检测自动化设备