探秘网络爬虫的基本原理与实例应用
发布时间:2024年01月19日
1. 基本原理
网络爬虫是一种用于自动化获取互联网信息的程序,其基本原理包括URL获取、HTTP请求、HTML解析、数据提取和数据存储等步骤。
-
URL获取: 确定需要访问的目标网页,通过人工指定、站点地图或之前的抓取结果获取URL。
-
HTTP请求: 发送HTTP请求向目标服务器请求页面内容,通常使用GET请求,服务器返回相应的HTML页面或其他格式的数据。
-
HTML解析: 解析HTML页面,使用解析器库如Beautiful Soup或lxml,以便更方便地提取数据。
-
数据提取: 在HTML解析的基础上,通过选择器或正则表达式等方式,定位和提取所需的数据。
-
数据存储: 将提取到的数据保存到本地文件、数据库或其他数据存储介质中。
2. 百度是如何搜到CSDN的
百度搜素引擎通过爬虫技术实现网页的抓取和索引。当用户在百度搜索框中输入关键词时,百度就会将之前爬取的结果展示出来了:
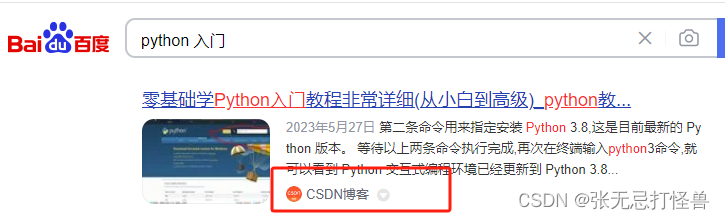
-
抓取: 百度爬虫按照一定的算法和策略抓取与用户搜索相关的网页。这包括在互联网上爬取网页的内容、链接等信息。
-
索引: 抓取到的网页被存储在百度的数据库中,建立索引以便能够快速检索。索引包括关键词、页面内容、链接等信息。
当用户输入关键词,百度根据索引中的信息找到匹配的网页,并按照一定的排名算法呈现给用户,其中包括了CSDN等相关网页。
3. Python爬虫简单实例
以下是一个使用Python实现的简单网络爬虫示例,通过爬取百度首页的标题:
import requests
from bs4 import BeautifulSoup
# 发送HTTP请求
response = requests.get("https://www.baidu.com")
html_content = response.text
# HTML解析
soup = BeautifulSoup(html_content, 'html.parser')
# 提取标题
title = soup.title.text
# 打印结果
print(f"百度首页标题:{title}")
这个例子使用了requests库发送HTTP请求,BeautifulSoup库解析HTML页面,然后提取了页面的标题信息。这只是一个简单的入门示例,实际爬虫应用可能需要更复杂的处理和对抗反爬机制的策略。在实际应用中,请确保你的爬虫行为合法,遵守网站的规则和法规。
文章来源:https://blog.csdn.net/xuanunix/article/details/135704984
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 单细胞RNA速率(RNA velocity)
- 第三届先进控制、自动化与机器人国际会议(ICACAR 2024) | Ei、Scopus双检索
- 让Windows系统加速引导的六种方法,值得你去尝试
- 众和策略证券开户首选:交易规则和开通条件解析!
- LeetCode[62] 不同路径
- 抖捧AI实景自动直播怎么玩
- 深入理解 Spark(四)Spark 内存管理模型
- 2024“华数杯”国际大学生数学建模竞赛(B题)光伏发电| 建模秘籍&文章代码思路大全
- 流式系统:第九章到第十章
- Linux驱动学习—中断