go interface 设计与实现
在上一篇文章《go interface 基本用法》中,我们了解了 go 中 interface 的一些基本用法,其中提到过 接口本质是一种自定义类型,本文就来详细说说为什么说 接口本质是一种自定义类型,以及这种自定义类型是如何构建起 go 的 interface 系统的。
本文使用的源码版本: go 1.19。另外本文中提到的
interface和接口是同一个东西。
前言
在了解 go interface 的设计过程中,看了不少资料,但是大多数资料都有生成汇编的操作,但是在我的电脑上指向生成汇编的操作的时候,
生成的汇编代码却不太一样,所以有很多的东西无法验证正确性,这部分内容不会出现在本文中。本文只写那些经过本机验证正确的内容,但也不用担心,因为涵盖了 go interface 设计与实现的核心部分内容,但由于水平有限,所以只能尽可能地传达我所知道的关于 interface 的一切东西。对于有疑问的部分,有兴趣的读者可以自行探索。
如果想详细地了解,建议还是去看看 iface.go,里面有接口实现的一些关键的细节。但是还是有一些东西被隐藏了起来,
导致我们无法知道我们 go 代码会是 iface.go 里面的哪一段代码实现的。
接口是什么?
接口(
interface)本质上是一种结构体。
我们先来看看下面的代码:
// main.go
package main
type Flyable interface {
Fly()
}
// go tool compile -N -S -l main.go
func main() {
var f1 interface{}
println(f1) // CALL runtime.printeface(SB)
var f2 Flyable
println(f2) // CALL runtime.printiface(SB)
}
我们可以通过 go tool compile -N -S -l main.go 命令来生成 main.go 的伪汇编代码,生成的代码会很长,下面省略所有跟本文主题无关的代码:
// main.go:10 => println(f1)
0x0029 00041 (main.go:10) CALL runtime.printeface(SB)
// main.go:13 => println(f2)
0x004f 00079 (main.go:13) CALL runtime.printiface(SB)
我们从这段汇编代码中可以看到,我们 println(f1) 实际上是对 runtime.printeface 的调用,我们看看这个 printeface 方法:
func printeface(e eface) {
print("(", e._type, ",", e.data, ")")
}
我们看到了,这个 printeface 接收的参数实际上是 eface 类型,而不是 interface{} 类型,我们再来看看 println(f2) 实际调用的 runtime.printiface 方法:
func printiface(i iface) {
print("(", i.tab, ",", i.data, ")")
}
也就是说 interface{} 类型在底层实际上是 eface 类型,而 Flyable 类型在底层实际上是 iface 类型。
这就是本文要讲述的内容,go 中的接口变量其实是用 iface 和 eface 这两个结构体来表示的:
iface表示某一个具体的接口(含有方法的接口)。eface表示一个空接口(interface{})

iface 和 eface 结构体
iface 和 eface 的结构体定义(runtime/iface.go):
// 非空接口(如:io.Reader)
type iface struct {
tab *itab // 方法表
data unsafe.Pointer // 指向变量本身的指针
}
// 空接口(interface{})
type eface struct {
_type *_type // 接口变量的类型
data unsafe.Pointer // 指向变量本身的指针
}
go 底层的类型信息是使用
_type结构体来存储的。
比如,我们有下面的代码:
package main
type Bird struct {
name string
}
func (b Bird) Fly() {
}
type Flyable interface {
Fly()
}
func main() {
bird := Bird{name: "b1"}
var efc interface{} = bird // efc 是 eface
var ifc Flyable = bird // ifc 是 iface
println(efc) // runtime.printeface
println(ifc) // runtime.printiface
}
在上面代码中,efc 是 eface 类型的变量,对应到 eface 结构体的话,_type 就是 Bird 这个类型本身,而 data 就是 &bird 这个指针:

类似的,ifc 是 iface 类型的变量,对应到 iface 结构体的话,data 也是 &bird 这个指针:

_type 是什么?
在 go 中,_type 是保存了变量类型的元数据的结构体,定义如下:
// _type 是 go 里面所有类型的一个抽象,里面包含 GC、反射、大小等需要的细节,
// 它也决定了 data 如何解释和操作。
// 里面包含了非常多信息:类型的大小、哈希、对齐及 kind 等信息
type _type struct {
size uintptr // 数据类型共占用空间的大小
ptrdata uintptr // 含有所有指针类型前缀大小
hash uint32 // 类型 hash 值;避免在哈希表中计算
tflag tflag // 额外类型信息标志
align uint8 // 该类型变量对齐方式
fieldAlign uint8 // 该类型结构体字段对齐方式
kind uint8 // 类型编号
// 用于比较此类型对象的函数
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gc 相关数据
gcdata *byte
str nameOff // 类型名字的偏移
ptrToThis typeOff
}
这个 _type 结构体定义大家随便看看就好了,实际上,go 底层的类型表示也不是上面这个结构体这么简单。
但是,我们需要知道的一点是(与本文有关的信息),通过 _type 我们可以得到结构体里面所包含的方法这些信息。
具体我们可以看 itab 的 init 方法(runtime/iface.go),我们会看到如下几行:
typ := m._type
x := typ.uncommon() // 结构体类型
nt := int(x.mcount) // 实际类型的方法数量
// 实际类型的方法数组,数组元素为 method
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
在底层,go 是通过 _type 里面 uncommon 返回的地址,加上一个偏移量(x.moff)来得到实际结构体类型的方法列表的。
我们可以参考一下下图想象一下:

itab 是什么?
我们从 iface 中可以看到,它包含了一个 *itab 类型的字段,我们看看这个 itab 的定义:
// 编译器已知的 itab 布局
type itab struct {
inter *interfacetype // 接口类型
_type *_type
hash uint32
_ [4]byte
fun [1]uintptr // 变长数组. fun[0]==0 意味着 _type 没有实现 inter 这个接口
}
// 接口类型
// 对应源代码:type xx interface {}
type interfacetype struct {
typ _type // 类型信息
pkgpath name // 包路径
mhdr []imethod // 接口的方法列表
}
根据
interfacetype我们可以得到关于接口所有方法的信息。同样的,通过_type也可以获取结构体类型的所有方法信息。
从定义上,我们可以看到 itab 跟 *interfacetype 和 *_type 有关,但实际上有什么关系从定义上其实不太能看得出来,
但是我们可以看它是怎么被使用的,现在,假设我们有如下代码:
// i 在底层是一个 interfacetype 类型
type i interface {
A()
C()
}
// t 底层会用 _type 来表示
// t 里面有 A、B、C、D 方法
// 因为实现了 i 中的所有方法,所以 t 实现了接口 i
type t struct {}
func (t) A() {}
func (t) B() {}
func (t) C() {}
func (t) D() {}
下图描述了上面代码对应的 itab 生成的过程:

说明:
itab里面的inter是接口类型的指针(比如通过type Reader interface{}这种形式定义的接口,记录的是这个类型本身的信息),这个接口类型本身定义了一系列的方法,如图中的i包含了A、C两个方法。_type是实际类型的指针,记录的是这个实际类型本身的信息,比如这个类型包含哪些方法。图中的i实现了A、B、C、D四个方法,因为实现了i的所有方法,所以说t实现了i接口。- 在底层做类型转换的时候,比如
t转换为i的时候(var v i = t{}),会生成一个itab,如果t没有实现i中的所有方法,那么生成的itab中不包含任何方法。 - 如果
t实现了i中的所有方法,那么生成的itab中包含了i中的所有方法指针,但是实际指向的方法是实际类型的方法(也就是指向的是t中的方法地址) mhdr就是itab中的方法表,里面的方法名就是接口的所有方法名,这个方法表中保存了实际类型(t)中同名方法的函数地址,通过这个地址就可以调用实际类型的方法了。
所以,我们有如下结论:
itab实际上定义了interfacetype和_type之间方法的交集。作用是什么呢?就是用来判断一个结构体是否实现某个接口的。itab包含了接口的所有方法,这里面的方法是实际类型的子集。itab里面的方法列表包含了实际类型的方法指针(也就是实际类型的方法的地址),通过这个地址可以对实际类型进行方法的调用。itab在实际类型没有实现接口的所有方法的时候,生成失败(失败的意思是,生成的itab里面的方法列表是空的,在底层实现上是用fun[0] = 0来表示)。
生成的 itab 是怎么被使用的?
go 里面定义了一个全局变量 itabTable,用来缓存 itab,因为在判断某一个结构体是否实现了某一个接口的时候,
需要比较两者的方法集,如果结构体实现了接口的所有方法,那么就表明结构体实现了接口(这也就是生成 itab 的过程)。
如果在每一次做接口断言的时候都要做一遍这个比较,性能无疑会大大地降低,因此 go 就把这个比较得出的结果缓存起来,也就是 itab。
这样在下一次判断结构体是否实现了某一个接口的时候,就可以直接使用之前的 itab,性能也就得到提升了。
// 表里面缓存了 itab
itabTable = &itabTableInit
itabTableInit = itabTableType{size: itabInitSize}
// 全局的 itab 表
type itabTableType struct {
size uintptr // entries 的长度,2 的次方
count uintptr // 当前 entries 的数量
entries [itabInitSize]*itab // 保存 itab 的哈希表
}
itabTableType 里面的 entries 是一个哈希表,在实际保存的时候,会用 interfacetype 和 _type 这两个生成一个哈希表的键。
也就是说,这个保存 itab 的缓存哈希表中,只要我们有 interfacetype 和 _type 这两个信息,就可以获取一个 itab。
具体怎么使用,我们可以看看下面的例子:
package main
type Flyable interface {
Fly()
}
type Runnable interface {
Run()
}
var _ Flyable = (*Bird)(nil)
var _ Runnable = (*Bird)(nil)
type Bird struct {
}
func (b Bird) Fly() {
}
func (b Bird) Run() {
}
// GOOS=linux GOARCH=amd64 go tool compile -N -S -l main.go > main.s
func test() {
// f 的类型是 iface
var f Flyable = Bird{}
// Flyable 转 Runnable 本质上是 iface 到 iface 的转换
f.(Runnable).Run() // CALL runtime.assertI2I(SB)
// 这个 switch 里面的类型断言本质上也是 iface 到 iface 的转换
// 但是 switch 里面的类型断言失败不会引发 panic
switch f.(type) {
case Flyable: // CALL runtime.assertI2I2(SB)
case Runnable: // CALL runtime.assertI2I2(SB)
}
if _, ok := f.(Runnable); ok { // CALL runtime.assertI2I2(SB)
}
// i 的类型是 eface
var i interface{} = Bird{}
// i 转 Flyable 本质上是 eface 到 iface 的转换
i.(Flyable).Fly() // CALL runtime.assertE2I(SB)
// 这个 switch 里面的类型断言本质上也是 eface 到 iface 的转换
// 但是 switch 里面的类型断言失败不会引发 panic
switch i.(type) {
case Flyable: // CALL runtime.assertE2I2(SB)
case Runnable: // CALL runtime.assertE2I2(SB)
}
if _, ok := i.(Runnable); ok { // CALL runtime.assertE2I2(SB)
}
}
我们对上面的代码生成伪汇编代码:
GOOS=linux GOARCH=amd64 go tool compile -N -S -l main.go > main.s
然后我们去查看 main.s,就会发现类型断言的代码,本质上是对 runtime.assert* 方法的调用(assertI2I、assertI2I2、assertE2I、assertE2I2),
这几个方法名都是以 assert 开头的,assert 在编程语言中的含义是,判断后面的条件是否为 true,如果 false 则抛出异常或者其他中断程序执行的操作,为 true 则接着执行。
这里的用处就是,判断一个接口是否能够转换为另一个接口或者另一个类型。
但在这里有点不太一样,这里有两个函数最后有个数字 2 的,表明了我们对接口的类型转换会有两种情况,我们上面的代码生成的汇编其实已经很清楚了,
一种情况是直接断言,使用 i.(T) 这种形式,另外一种是在 switch...case 里面使用,。
我们可以看看它们的源码,看看有什么不一样:
// 直接根据 interfacetype/_type 获取 itab
func assertE2I(inter *interfacetype, t *_type) *itab {
if t == nil {
// 显式转换需要非nil接口值。
panic(&TypeAssertionError{nil, nil, &inter.typ, ""})
}
// getitab 的第三个参数是 false
// 表示 getiab 获取不到 itab 的时候需要 panic
return getitab(inter, t, false)
}
// 将 eface 转换为 iface
// 因为 e 包含了 *_type
func assertE2I2(inter *interfacetype, e eface) (r iface) {
t := e._type
if t == nil {
return
}
// getitab 的第三个参数是 true
// 表示 getitab 获取不到 itab 的时候不需要 panic
tab := getitab(inter, t, true)
if tab == nil {
return
}
r.tab = tab
r.data = e.data
return
}
getitab的源码后面会有。
从上面的代码可以看到,其实带 2 和不带 2 后缀的关键区别在于:getitab 的调用允不允许失败。
这有点类似于 chan 里面的 select,chan 的 select 语句中读写 chan 不会阻塞,而其他地方会阻塞。
assertE2I2 是用在 switch...case 中的,这个调用是允许失败的,因为我们还需要判断能否转换为其他类型;
又或者 v, ok := i.(T) 的时候,也是允许失败的,但是这种情况会返回第二个值给用户判断是否转换成功。
而直接使用类型断言的时候,如 i.(T) 这种,如果 i 不能转换为 T 类型,则直接 panic。
对于 go 中的接口断言可以总结如下:
assertI2I用于将一个iface转换为另一个iface,转换失败的时候会panicassertI2I2用于将一个iface转换为另一个iface,转换失败的时候不会panicassertE2I用于将一个eface转换为另一个iface,转换失败的时候会panicassertE2I2用于将一个eface转换为另一个iface,转换失败的时候不会panicassert相关的方法后缀的I2I、E2E里面的I表示的是iface,E表示的是eface- 带
2后缀的允许失败,用于v, ok := i.(T)或者switch x.(type) ... case中 - 不带
2后缀的不允许失败,用于i.(T)这种形式中
当然,这里说的转换不是说直接转换,只是说,在转换的过程中会用到 assert* 方法。
如果我们足够细心,然后也去看了 assertI2I 和 assertI2I2 的源码,就会发现,这几个方法本质上都是,
通过 interfacetype 和 _type 来获取一个 itab 然后转换为另外一个 itab 或者 `iface。
同时,我们也应该注意到,上面的转换都是转换到 iface 而没有转换到 eface 的操作,这是因为,所有类型都可以转换为空接口(interface{},也就是 eface)。根本就不需要断言。
上面的内容可以结合下图理解一下:

itab 关键方法的实现
下面,让我们再来深入了解一下 itab 是怎么被创建出来的,以及是怎么保存到全局的哈希表中的。我们先来看看下图:

这个图描述了 go 底层存储 itab 的方式:
- 通过一个
itabTableType类型来存储所有的itab。 - 在调用
getitab的时候,会先根据inter和_type计算出哈希值,然后从entries中查找是否存在,存在就返回对应的itab,不存在则新建一个itab。 - 在调用
itabAdd的时候,会将itab加入到itabTableType类型变量里面的entries中,其中entries里面的键是根据inter和_type做哈希运算得出的。
itab 两个比较关键的方法:
getitab让我们可以通过interfacetype和_type获取一个itab,会现在缓存中找,找不到会新建一个。itabAdd是在我们缓存找不到itab,然后新建之后,将这个新建的itab加入到缓存的方法。
getitab 方法的第三个参数 canfail 表示当前操作是否允许失败,上面说了,如果是用在 switch...case 或者 v, ok := i.(T) 这种是允许失败的。
// 获取某一个类型的 itab(从 itabTable 中查找,键是 inter 和 _type 的哈希值)
// 查找 interfacetype + _type 对应的 itab
// 找不到就新增。
func getitab(inter *interfacetype, typ *_type, canfail bool) *itab {
if len(inter.mhdr) == 0 {
throw("internal error - misuse of itab")
}
// 不包含 Uncommon 信息的类型直接报错
if typ.tflag&tflagUncommon == 0 {
if canfail {
return nil
}
name := inter.typ.nameOff(inter.mhdr[0].name)
panic(&TypeAssertionError{nil, typ, &inter.typ, name.name()})
}
// 保存返回的 itab
var m *itab
// t 指向了 itabTable(全局的 itab 表)
t := (*itabTableType)(atomic.Loadp(unsafe.Pointer(&itabTable)))
// 会先从全局 itab 表中查找,找到就直接返回
if m = t.find(inter, typ); m != nil {
goto finish
}
// 没有找到,获取锁,再次查找。
// 找到则返回
lock(&itabLock)
if m = itabTable.find(inter, typ); m != nil {
unlock(&itabLock)
goto finish
}
// 没有在缓存中找到,新建一个 itab
m = (*itab)(persistentalloc(unsafe.Sizeof(itab{})+uintptr(len(inter.mhdr)-1)*goarch.PtrSize, 0, &memstats.other_sys))
// itab 的
m.inter = inter
m._type = typ
m.hash = 0
// itab 初始化
m.init()
// 将新创建的 itab 加入到全局的 itabTable 中
itabAdd(m)
// 释放锁
unlock(&itabLock)
finish:
// == 0 表示没有任何方法
// 下面 != 0 表示有 inter 和 typ 有方法的交集
if m.fun[0] != 0 {
return m
}
// 用在 switch x.(type) 中的时候,允许失败而不是直接 panic
// 但在 x.(Flyable).Fly() 这种场景会直接 panic
if canfail {
return nil
}
// 没有找到有方法的交集,panic
panic(&TypeAssertionError{concrete: typ, asserted: &inter.typ, missingMethod: m.init()})
}
itabAdd 将给定的 itab 添加到 itab 哈希表中(itabTable)。
注意:
itabAdd中在判断到哈希表的使用量超过75%的时候,会进行扩容,新的容量为旧容量的 2 倍。
// 必须保持 itabLock。
func itabAdd(m *itab) {
// 正在分配内存的时候调用的话报错
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable
// 容量已经超过 75% 的负载了,hash 表扩容
if t.count >= 3*(t.size/4) {
// 75% load factor(实际上是:t.size *0.75)
// 扩展哈希表。原来 2 倍大小。
// 我们撒谎告诉 malloc 我们需要无指针内存,因为所有指向的值都不在堆中。
// 2 是 size 和 count 这两个字段需要的空间
t2 := (*itabTableType)(mallocgc((2+2*t.size)*goarch.PtrSize, nil, true))
t2.size = t.size * 2
// 复制条目。
// 注意:在复制时,其他线程可能会查找itab,但找不到它。
// 没关系,然后它们会尝试获取itab锁,因此等待复制完成。
iterate_itabs(t2.add) // 遍历旧的 hash 表,复制函数指针到 t2 中
if t2.count != t.count { // 复制出错
throw("mismatched count during itab table copy")
}
// 发布新哈希表。使用原子写入:请参见 getitab 中的注释。
// 使用 t2 覆盖 itabTable
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
// 使用新的 hash 表
// 因为 t 是局部变量,指向旧的地址,
// 但是扩容之后是新的地址了,所以现在需要将新的地址赋给 t
t = itabTable
// 注:旧的哈希表可以在此处进行GC。
}
// 将 itab 加入到全局哈希表
t.add(m)
}
其实 itabAdd 的关键路径比较清晰,只是因为它是一个哈希表,所以里面在判断到当前 itab 的数量超过 itabTable 容量的 75% 的时候,会对 itabTable 进行 2 倍扩容。
根据 interfacetype 和 _type 初始化 itab
上面那个图我们说过,itab 本质上是 interfacetype 和 _type 方法的交集,这一节我们就来看看,itab 是怎么根据这两个类型来进行初始化的。
itab 的 init 方法实现:
// init 用 m.inter/m._type 对的所有代码指针填充 m.fun 数组。
// 如果该类型不实现接口,它将 m.fun[0] 设置为 0 ,并返回缺少的接口函数的名称。
// 可以在同一个m上多次调用,甚至同时调用。
func (m *itab) init() string {
inter := m.inter // 接口
typ := m._type // 实际的类型
x := typ.uncommon()
// inter 和 typ 都具有按名称排序的方法,并且接口名称是唯一的,因此可以在锁定步骤中迭代这两个;
// 循环时间复杂度是 O(ni+nt),不是 O(ni*nt)
ni := len(inter.mhdr) // 接口的方法数量
nt := int(x.mcount) // 实际类型的方法数量
// 实际类型的方法数组,数组元素为 method
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt] // 大小无关紧要,因为下面的指针访问不会超出范围
j := 0
// 用来保存 inter/_type 对方法列表的数组,数组元素为 unsafe.Pointer(是实际类型方法的指针)
methods := (*[1 << 16]unsafe.Pointer)(unsafe.Pointer(&m.fun[0]))[:ni:ni] // 保存 itab 方法的数组
// 第一个方法的指针
var fun0 unsafe.Pointer
imethods:
for k := 0; k < ni; k++ { // 接口方法遍历
i := &inter.mhdr[k] // i 是接口方法, imethod 类型
itype := inter.typ.typeOff(i.ityp) // 接口的方法类型
name := inter.typ.nameOff(i.name) // 接口的方法名称
iname := name.name() // 接口的方法名
ipkg := name.pkgPath() // 接口的包路径
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
// 根据接口方法查找实际类型的方法
for ; j < nt; j++ { // 实际类型的方法遍历
t := &xmhdr[j] // t 是实际类型的方法,method 类型
tname := typ.nameOff(t.name) // 实际类型的方法名
// 比较接口的方法跟实际类型的方法是否一致
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
// 实际类型的包路径
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
// 如果是导出的方法
// 则保存到 itab 中
if tname.isExported() || pkgPath == ipkg {
if m != nil {
ifn := typ.textOff(t.ifn) // 实际类型的方法指针(通过这个指针可以调用实际类型的方法)
if k == 0 {
// 第一个方法
fun0 = ifn // we'll set m.fun[0] at the end
} else {
methods[k] = ifn
}
}
// 比较下一个方法
continue imethods
}
}
}
// 没有实现接口(实际类型没有实现 interface 中的任何一个方法)
m.fun[0] = 0
return iname // 返回缺失的方法名,返回值在类型断言失败的时候会需要提示用户
}
// 实现了接口
m.fun[0] = uintptr(fun0)
return ""
}
接口断言过程总览(类型转换的关键)
具体来说有四种情况,对应上面提到的 runtime.assert* 方法:
- 实际类型转换到
iface iface转换到另一个iface- 实际类型转换到
eface eface转换到iface
这其中的关键是
interfacetype+_type可以生成一个itab。
上面的内容可能有点混乱,让人摸不着头脑,但是我们通过上面的讲述,相信已经了解了 go 接口中底层的一些实现细节,现在,就让我们重新来捋一下,看看 go 接口到底是怎么实现的:
首先,希望我们可以达成的一个共识就是,go 的接口断言本质上是类型转换,switch...case 里面或 v, ok := i.(T) 允许转换失败,而 i.(T).xx() 这种不允许转换失败,转换失败的时候会 panic。
接着,我们就可以通过下图来了解 go 里面的接口整体的实现原理了(还是以上面的代码作为例子):
- 将结构体赋值给接口类型:
var f Flyable = Bird{}

在这个赋值过程中,创建了一个 iface 类型的变量,这个变量中的 itab 的方法表只包含了 Flyable 定义的方法。
iface转另一个iface:
f.(Runnable)_, ok := f.(Runnable)switch f.(type)里面的case是Runnable

在这个断言过程中,会将 Flyable 转换为 Runnable,本质上是一个 iface 转换到另一个 iface。但是有个不同之处在于,
两个 iface 里面的方法列表是不一样的,只包含了当前 interfacetype 里面定义的方法。
- 将结构体赋值给空接口:
var i interface{} = Bird{}
在这个过程中,创建了一个 eface 类型的变量,这个 eface 里面只包含了类型信息以及实际的 Bird 结构体实例。

eface转换到iface
i.(Flyable)_, ok := i.(Runnable)switch i.(type)里面的case是Flyable
因为 _type 包含了 Bird 类型的所有信息,而 data 包含了 Bird 实例的值,所以这个转换是可行的。

panicdottypeI 与 panicdottypeE
从前面的几个小节,我们知道,go 的 iface 类型转换使用的是 runtime.assert* 几个方法,还有另外一种情况就是,
在编译期间编译器就已经知道了无法转换成功的情况,比如下面的代码:
package main
type Flyable interface {
Fly()
}
type Cat struct {
}
func (c Cat) Fly() {
}
func (c Cat) test() {
}
// GOOS=linux GOARCH=amd64 go tool compile -N -S -l main.go > main.s
func main() {
var b interface{}
var _ = b.(int) // CALL runtime.panicdottypeE(SB)
var c Flyable = &Cat{}
c.(Cat).test() // CALL runtime.panicdottypeI(SB)
}
上面的两个转换都是错误的,第一个 b.(int) 尝试将 nil 转换为 int 类型,第二个尝试将 *Cat 类型转换为 Cat 类型,
这两个错误的类型转换都在编译期可以发现,因此它们生成的汇编代码调用的是 runtime.panicdottypeE 和 runtime.panicdottypeI 方法:
// 在执行 e.(T) 转换时如果转换失败,则调用 panicdottypeE
// have:我们的动态类型。
// want:我们试图转换为的静态类型。
// iface:我们正在转换的静态类型。
// 转换的过程:尝试将 iface 的 have 转换为 want 失败了。
// 不是调用方法的时候的失败。
func panicdottypeE(have, want, iface *_type) {
panic(&TypeAssertionError{iface, have, want, ""})
}
// 当执行 i.(T) 转换并且转换失败时,调用 panicdottypeI
// 跟 panicdottypeE 参数相同,但是 hava 是动态的 itab 类型
func panicdottypeI(have *itab, want, iface *_type) {
var t *_type
if have != nil {
t = have._type
}
panicdottypeE(t, want, iface)
}
这两个方法都是引发一个 panic,因为我们的类型转换失败了:

iface 和 eface 里面的 data 是怎么来的?
我们先看看下面的代码:
package main
type Bird struct {
}
func (b Bird) Fly() {
}
type Flyable interface {
Fly()
}
// GOOS=linux GOARCH=amd64 go tool compile -N -S -l main.go > main.s
func main() {
bird := Bird{}
var efc interface{} = bird // CALL runtime.convT(SB)
var ifc Flyable = bird // CALL runtime.convT(SB)
println(efc, ifc)
}
我们生成伪汇编代码发现,里面将结构体变量赋值给接口类型变量的时候,实际上是调用了 convT 方法。
convT* 方法
iface 里面还包含了几个 conv* 前缀的函数,在我们将某一具体类型的值赋值给接口类型的时候,go 底层会将具体类型的值通过 conv* 函数转换为 iface 里面的 data 指针:
// convT 将 v 指向的 t 类型的值转换为可以用作接口值的第二个字的指针(接口的第二个字是指向 data 的指针)。
// data(Pointer) => 指向 interface 第 2 个字的 Pointer
func convT(t *_type, v unsafe.Pointer) unsafe.Pointer {
// ... 其他代码
// 分配 _type 类型所需要的内存
x := mallocgc(t.size, t, true)
// 将 v 指向的值复制到刚刚分配的内存上
typedmemmove(t, x, v)
return x
}
我们发现,在这个过程,实际上是将值复制了一份:

iface.go 里面还有将无符号值转换为 data 指针的函数,但是还不知道在什么地方会用到这些方法,如:
// 转换 uint16 类型值为 interface 里面 data 的指针。
// 如果是 0~255 的整数,返回指向 staticuint64s 数组里面对应下标的指针。
// 否则,分配新的内存地址。
func convT16(val uint16) (x unsafe.Pointer) {
// 如果小于 256,则使用共享的内存地址
if val < uint16(len(staticuint64s)) {
x = unsafe.Pointer(&staticuint64s[val])
if goarch.BigEndian {
x = add(x, 6)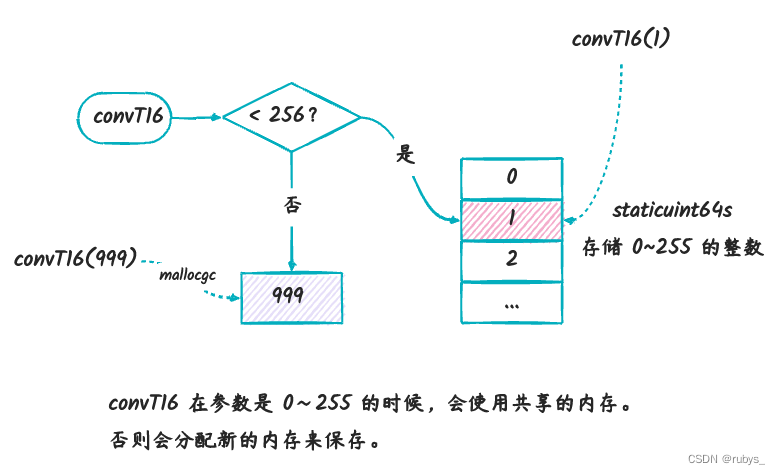
}
} else {
// 否则,分配新的内存
x = mallocgc(2, uint16Type, false)
*(*uint16)(x) = val
}
return
}
个人猜测,仅仅代表个人猜测,在整数赋值给 iface 或者 eface 的时候会调用这类方法。不管调不调用,我们依然可以看看它的设计,因为有些值得学习的地方:
staticuint64s 是一个全局整型数组,里面存储的是 0~255 的整数。上面的代码可以表示为下图:
这个函数跟上面的 convT 的不同之处在于,它在判断整数如果小于 256 的时候,则使用的是 staticuint64s 数组里面对应下标的地址。
为什么这样做呢?本质上是为了节省内存,因为对于数字来说,其实除了值本身,没有包含其他的信息了,所以如果对于每一个整数都分配新的内存来保存,
无疑会造成浪费。按 convT16 里面的实现方式,对于 0~255 之间的整数,如果需要给它们分配内存,就可以使用同一个指针(指向 staticuint64s[] 数组中元素的地址)。
这实际上是享元模式。
Java 里面的小整数享元模式
go 里使用 staticuint64s 的方式,其实在 Java 里面也有类似的实现,Java 中对于小整数也是使用了享元模式,
这样在装箱的时候,就不用分配新的内存了,就可以使用共享的一块内存了,当然,某一个整数能节省的内存非常有限,如果需要分配内存的小整数非常大,那么节省下来的内存就非常客观了。
当然,也不只是能节省内存这唯一的优点,从另一方面说,它也节省了垃圾回收器回收内存的开销,因为不需要管理那么多内存。
我们来看看 Java 中的例子:
class Test {
public static void main(String[] args) {
Integer k1 = 127;
Integer k2 = 127;
System.out.println(k1 == k2); // true
System.out.println(k1.equals(k2)); // true
Integer k10 = 128;
Integer k20 = 128;
System.out.println(k10 == k20); // false
System.out.println(k10.equals(k20)); // true
}
}
Java 里面有点不一样,它是对 -128~127 范围内的整数做了享元模式的处理,而 go 里面是 0~255。
上面的代码中,当我们使用 == 来比较 Integer 的时候,值相等的两个数,在 -128~127 的范围的时候,返回的是 true,超出这个范围的时候比较返回的是 false。
这是因为在 -128~127 的时候,值相等的两个数字指向了相同的内存地址,超出这个范围的时候,值相等的两个数指向了不同的地址。
Java 的详细实现可以看 java.lang.Integer.IntegerCache。
总结
- go 的的接口(
interface)本质上是一种结构体,底册实现是iface和eface,iface表示我们通过type i interface{}定义的接口,而eface表示interface{}/any,也就是空接口。 iface里面保存的itab中保存了具体类型的方法指针列表,data保存了具体类型值的内存地址。eface里面保存的_type包含了具体类型的所有信息,data保存了具体类型值的内存地址。itab是底层保存接口类型跟具体类型方法交集的结构体,如果具体类型实现了接口的所有方法,那么这个itab里面的保存有指向具体类型方法的指针。如果具体类型没有实现接口的全部方法,那么itab中的不会保存任何方法的指针(从itab的作用上看,我们可以看作是一个空的itab)。- 不管
itab的方法列表是否为空,interfacetype和_type比较之后生成的itab会缓存下来,在后续比较的时候可以直接使用缓存。 _type是 go 底层用来表示某一个类型的结构体,包含了类型所需空间大小等信息。- 类型断言
i.(T)本质上是iface到iface的转换,或者是eface到iface的转换,如果没有第二个返回值,那么转换失败的时候会引发panic。 switch i.(type) { case ...}本质上也是iface或eface到iface的转换,但是转换失败的时候不会引发panic。- 全局的保存
itab的缓存结构体,底层是使用了一个哈希表来保存itab的,在哈希表使用超过75%的时候,会触发扩容,新的哈希表容量为旧的2倍。 staticuint64s使用了享元模式,Java 中也有类似的实现。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- props配置项,scoped样式,localStorage和sessionStorage
- 深入理解Spark编程中的map方法
- 19. 蒙特卡洛强化学习之策略控制
- 解锁数据之门:Roxlabs全球住宅IP赋能海外爬虫与学术研究
- 基于梯度和频率域的深度超分辨率新方法笔记二
- 使用Java VisualVM实现细粒度代码执行时间测量:深入分析每行代码的性能
- 程序包org.junit.jupiter.api不存在
- day2 生成lua代码
- Ubuntu重启后进入initramfs导致无法开机
- 膛目结舌的代码技巧!一看就是冷暴力~~~~