大创项目推荐 深度学习+opencv+python实现车道线检测 - 自动驾驶
文章目录
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的自动驾驶车道线检测算法研究与实现 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
从汽车的诞生到现在为止已经有一百多年的历史了,随着车辆的增多,交通事故频繁发生,成为社会发展的隐患,人们的生命安全受到了严重威胁。多起事故发生原因中,都有一个共同点,那就是因为视觉问题使驾驶员在行车时获取不准确的信息导致交通事故的发生。为了解决这个问题,高级驾驶辅助系统(ADAS)应运而生,其中车道线检测就是ADAS中相当重要的一个环节。利用机器视觉来检测车道线相当于给汽车安装上了一双“眼睛”,从而代替人眼来获取车道线信息,在一定程度上可以减少发生交通事故的概率。
本项目基于yolov5实现图像车道线检测。
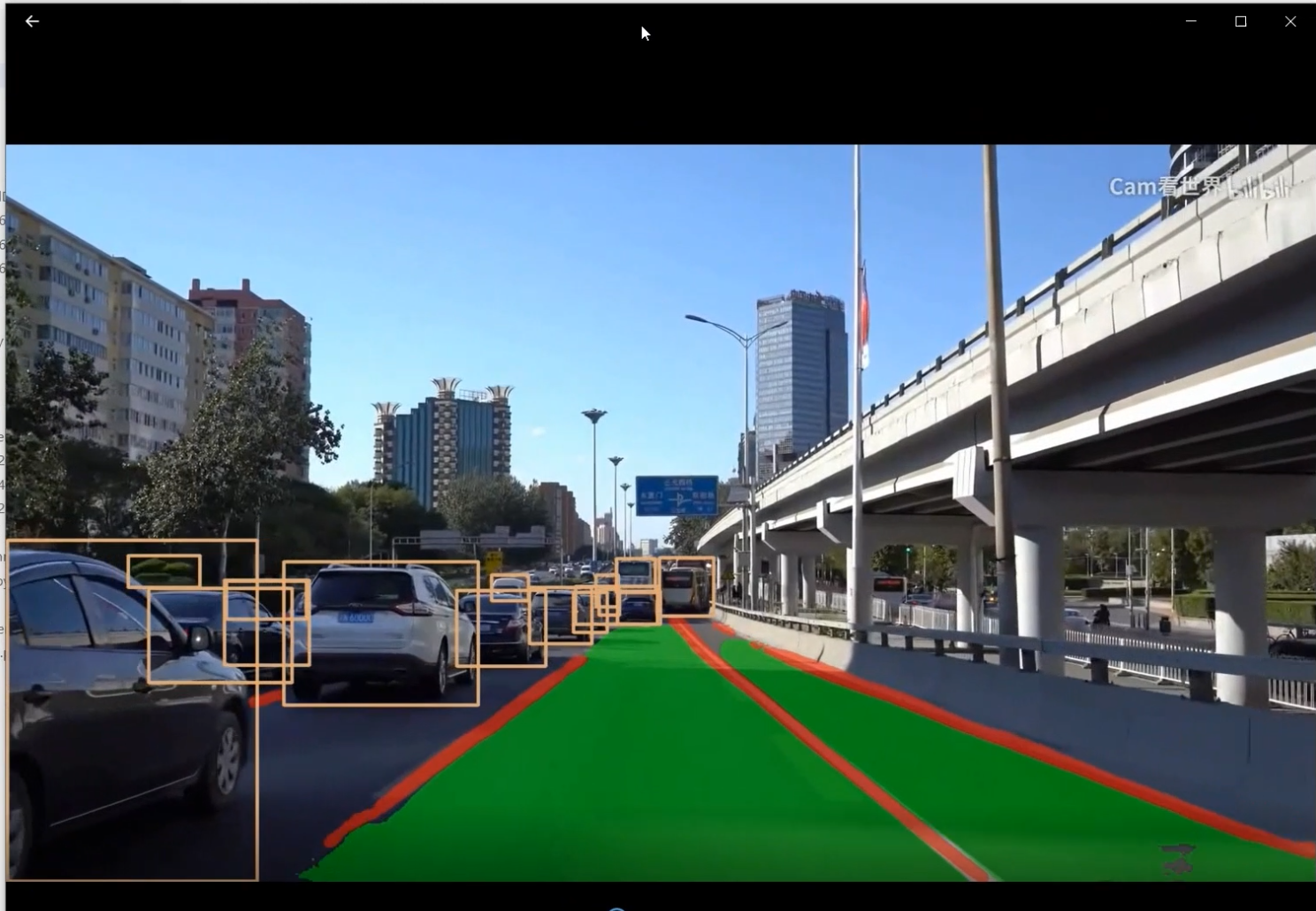
2 实现效果
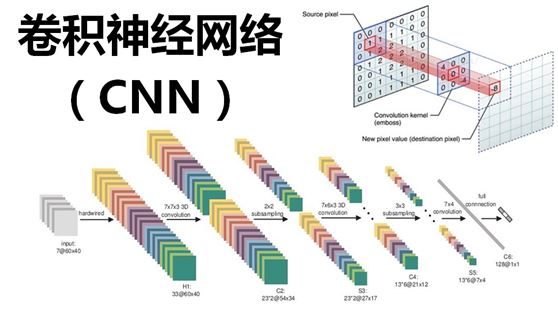
3 卷积神经网络
受到人类大脑神经突触结构相互连接的模式启发,神经网络作为人工智能领域的重要组成部分,通过分布式的方法处理信息,可以解决复杂的非线性问题,从构造方面来看,主要包括输入层、隐藏层、输出层三大组成结构。每一个节点被称为一个神经元,存在着对应的权重参数,部分神经元存在偏置,当输入数据x进入后,对于经过的神经元都会进行类似于:y=w*x+b的线性函数的计算,其中w为该位置神经元的权值,b则为偏置函数。通过每一层神经元的逻辑运算,将结果输入至最后一层的激活函数,最后得到输出output。
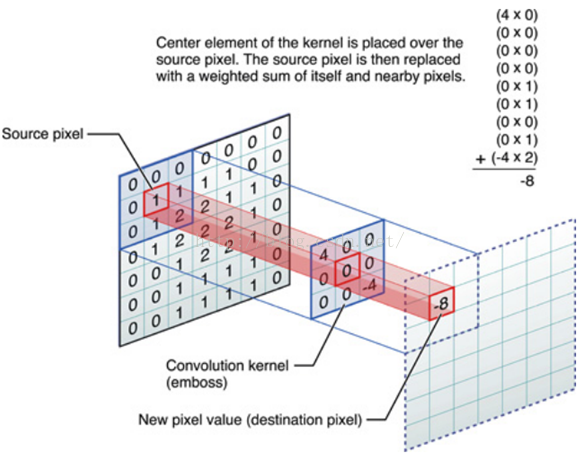
3.1卷积层
卷积核相当于一个滑动窗口,示意图中3x3大小的卷积核依次划过6x6大小的输入数据中的对应区域,并与卷积核滑过区域做矩阵点乘,将所得结果依次填入对应位置即可得到右侧4x4尺寸的卷积特征图,例如划到右上角3x3所圈区域时,将进行0x0+1x1+2x1+1x1+0x0+1x1+1x0+2x0x1x1=6的计算操作,并将得到的数值填充到卷积特征的右上角。
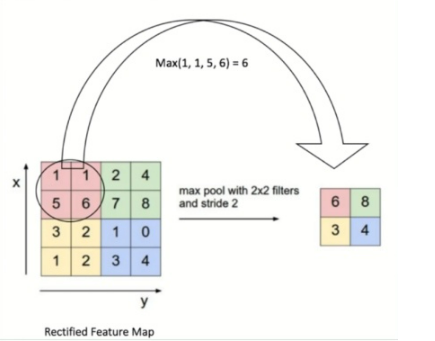
3.2 池化层
池化操作又称为降采样,提取网络主要特征可以在达到空间不变性的效果同时,有效地减少网络参数,因而简化网络计算复杂度,防止过拟合现象的出现。在实际操作中经常使用最大池化或平均池化两种方式,如下图所示。虽然池化操作可以有效的降低参数数量,但过度池化也会导致一些图片细节的丢失,因此在搭建网络时要根据实际情况来调整池化操作。
3.3 激活函数:
激活函数大致分为两种,在卷积神经网络的发展前期,使用较为传统的饱和激活函数,主要包括sigmoid函数、tanh函数等;随着神经网络的发展,研宄者们发现了饱和激活函数的弱点,并针对其存在的潜在问题,研宄了非饱和激活函数,其主要含有ReLU函数及其函数变体
3.4 全连接层
在整个网络结构中起到“分类器”的作用,经过前面卷积层、池化层、激活函数层之后,网络己经对输入图片的原始数据进行特征提取,并将其映射到隐藏特征空间,全连接层将负责将学习到的特征从隐藏特征空间映射到样本标记空间,一般包括提取到的特征在图片上的位置信息以及特征所属类别概率等。将隐藏特征空间的信息具象化,也是图像处理当中的重要一环。
3.5 使用tensorflow中keras模块实现卷积神经网络
?
class CNN(tf.keras.Model):
def __init__(self):
super().__init__()
self.conv1 = tf.keras.layers.Conv2D(
filters=32, # 卷积层神经元(卷积核)数目
kernel_size=[5, 5], # 感受野大小
padding='same', # padding策略(vaild 或 same)
activation=tf.nn.relu # 激活函数
)
self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.conv2 = tf.keras.layers.Conv2D(
filters=64,
kernel_size=[5, 5],
padding='same',
activation=tf.nn.relu
)
self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)
self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))
self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)
self.dense2 = tf.keras.layers.Dense(units=10)
def call(self, inputs):
x = self.conv1(inputs) # [batch_size, 28, 28, 32]
x = self.pool1(x) # [batch_size, 14, 14, 32]
x = self.conv2(x) # [batch_size, 14, 14, 64]
x = self.pool2(x) # [batch_size, 7, 7, 64]
x = self.flatten(x) # [batch_size, 7 * 7 * 64]
x = self.dense1(x) # [batch_size, 1024]
x = self.dense2(x) # [batch_size, 10]
output = tf.nn.softmax(x)
return output
4 YOLOV5
简介
基于卷积神经网络(convolutional neural network, CNN)的目标检测模型研究可按检测阶段分为两类,一 类 是 基 于 候 选 框
的 两 阶 段 检 测 , R-CNN 、 Fast R-CNN、Faster R-CNN、Mask R-CNN都是基于
目标候选框的两阶段检测方法;另一类是基于免候选框的单阶段检测,SSD、YOLO系列都是典型的基于回归思想的单阶段检测方法。
YOLOv5 目标检测模型 2020年由Ultralytics发布的YOLOv5在网络轻量化 上贡献明显,检测速度更快也更加易于部署。与之前
版本不同,YOLOv5 实现了网络架构的系列化,分别 是YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、
YOLOv5x。这5种模型的结构相似,通过改变宽度倍 数(Depth multiple)来改变卷积过程中卷积核的数量, 通 过 改 变 深 度 倍 数
(Width multiple) 来 改 变 BottleneckC3(带3个CBS模块的BottleneckCSP结构)中
C3的数量,从而实现不同网络深度和不同网络宽度之 间的组合,达到精度与效率的平衡。YOLOv5各版本性能如图所示:

模型结构图如下:

YOLOv5s 模型算法流程和原理
YOLOv5s模型主要算法工作流程原理:
(1) 原始图像输入部分加入了图像填充、自适应 锚框计算、Mosaic数据增强来对数据进行处理增加了 检测的辨识度和准确度。
(2) 主干网络中采用Focus结构和CSP1_X (X个残差结构) 结构进行特征提取。在特征生成部分, 使用基于SPP优化后的SPPF结构来完成。
(3) 颈部层应用路径聚合网络和CSP2_X进行特征融合。
(4) 使用GIOU_Loss作为损失函数。
关键代码:
6 数据集处理
获取摔倒数据集准备训练,如果没有准备好的数据集,可自己标注,但过程会相对繁琐
深度学习图像标注软件众多,按照不同分类标准有多中类型,本文使用LabelImg单机标注软件进行标注。LabelImg是基于角点的标注方式产生边界框,对图片进行标注得到xml格式的标注文件,由于边界框对检测精度的影响较大因此采用手动标注,并没有使用自动标注软件。
考虑到有的朋友时间不足,博主提供了标注好的数据集和训练好的模型,需要请联系。
数据标注简介
通过pip指令即可安装
?
pip install labelimg
在命令行中输入labelimg即可打开

打开你所需要进行标注的文件夹,点击红色框区域进行标注格式切换,我们需要yolo格式,因此切换到yolo
点击Create RectBo -> 拖拽鼠标框选目标 -> 给上标签 -> 点击ok
数据保存
点击save,保存txt。

7 模型训练
配置超参数
主要是配置data文件夹下的yaml中的数据集位置和种类:

配置模型
这里主要是配置models目录下的模型yaml文件,主要是进去后修改nc这个参数来进行类别的修改。

目前支持的模型种类如下所示:

训练过程

8 最后
🧿 更多资料, 项目分享:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 分布式锁实现(mysql,以及redis)以及分布式的概念
- 卧推40kg是极限重量了
- 浪花 - 添加队伍业务开发
- bullet3 三种碰撞检测及实现
- 大数据开发之Scala
- QCA9880: A multi-dimensional engine driving wireless communications
- 动态规划--使用最小花费爬楼梯
- 第9章-用户分群方法-层次聚类
- 八股文打卡day11——计算机网络(11)
- 2. 回归树