一线大厂面试真题——Redis和Mysql如何保证数据一致性
目录
概述
这个问题难倒了不少工作5年以上的程序员,难的不是问题本身,而是解决这个问题的思维模式。下面来看看普通人和高手对于这个问题的回答。
问题解答
一般情况下,Redis用来实现应用和数据库之间读操作的缓存层,主要目的是减少数据库IO,还可以提升数据的IO性能。这是它的整体架构。
当应用程序需要去读取某个数据的时候,首先会先尝试去Redis里面加载,如果命中就直接返回。如果没有命中,就从数据库查询,查询到数据后再把这个数据缓存到Redis里面。

在这架构中,会出现一个问题,就是一份数据,同时保存在数据库和Redis里面,当数据发生变化的时候,需要同时更新Redis和Mysql,由于更新是有先后顺序的,并且它不像Mysql中的多表事务操作,可以满足ACID特性。所以就会出现数据一致性问题。

在这种情况下,能够选择的方法只有几种:
1. ??先更新数据库,再更新缓存
2. ??先删除缓存,再更新数据库
如果先更新数据库,再更新缓存,如果缓存更新失败,就会导致数据库和Redis中的数据不一致。
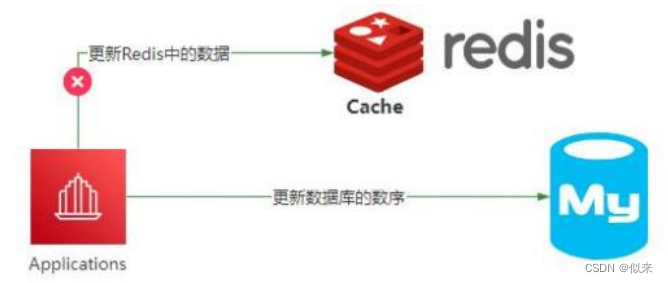
如果是先删除缓存,再更新数据库,理想情况是应用下次访问Redis的时候,发现Redis里面的数据是空的,就从数据库加载保存到Redis里面,那么数据是一致的。但是在极端情况下,由于删除Redis和更新数据库这两个操作并不是原子的,所以这个过程如果有其他线程来访问,还是会存在数据不一致问题。

所以,如果需要在极端情况下仍然保证Redis和MySQL的数据一致性,就只能采用最终一致性方案。
(如图)比如基于RocketMQ的可靠性消息通信,来实现最终一致性。

(如图)还可以直接通过Canal组件,监控MySQL中binlog的日志,把更新后的数据同步到Redis里面。
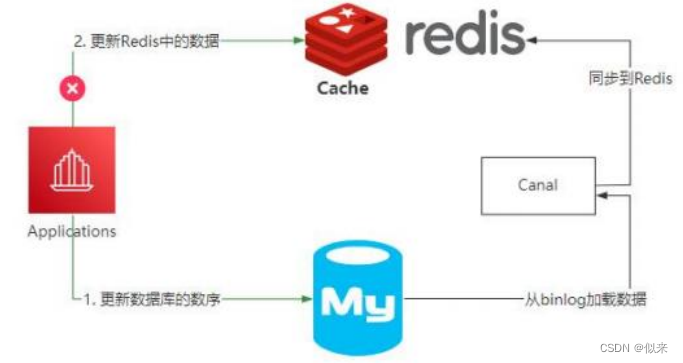
因为这里是基于最终一致性来实现的,如果业务场景不能接受数据的短期不一致性,那就不能使用这个方案来做。
结尾
在面试的时候,面试官喜欢问各种没有场景化的纯粹的技术问题,比如说:“你这个最终一致性方案”还是会存在数据不一致的问题啊?那怎么解决?
先不用慌,技术是为业务服务的,所以不同的业务场景,对于技术的选择和方案的设计
都是不同的,所以这个时候,可以反问面试官,具体的业务场景是什么?
一定要知道的是,一个技术方案不可能cover住所有的场景,明白了吗?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 李沐-《动手学深度学习》-- 01-预备知识
- 7 个95% 测试人员可能错过的不常见测试话题
- 群晖:storagepanel:群晖硬盘插槽显示面板修改插件使用说明(存储管理器/总览/硬盘信息)
- Spring之bean的生命周期
- 领略指针之妙
- 亚马逊SEO是什么意思?亚马逊标题的SEO方法是什么?-站斧浏览器
- MySQL主从复制与读写分离
- Likeshop单商户SaaS商城源码系统-商家用过都说太香啦!
- 这是一篇优雅的Springboot2.0使用手册
- RT-Thread 18. 互斥量例子