go基础问题
go基础问题
Go相关:
1、协程与线程
线程拥有自己的独立的栈和共享的堆,也是由操作系统进行调度。
协程共享堆,不共享栈,协程的调度由用户控制。
协程优点:
1)代码编辑简单,可以用同步的方式去写异步代码。
2)单线程模式,没有线程安全的问题,不需要加锁操作。
3)性能好,协程是用户态线程,切换更加高效。
4)线程无法掌控生命周期等要素。
2、go适合做什么
高并发的工作(如爬虫),微服务通信(grpc框架)
3、数据一致性?
在Go语言中,保证数据的一致性通常需要使用互斥锁(Mutex)或读写锁(RWMutex)等机制来实现。这些机制可以防止多个goroutine同时对同一个数据进行读写操作而出现数据不一致的情况。
4、你为什么选择学习Go语言?*
①Go语言具有简洁、易读和高效的语法。
语法简洁,没有java那么多的关键字和语法规则(如静态成员变量、继承),并且能推断类型;
快速编译,由于其静态类型系统和简洁的语法;
具有高性能和并发特性,使用协程和并发非常简单;
第三方库导入简单,与java相比,java下载导入依赖都很麻烦。
②庞大的开发者社区。
Go是谷歌开发的语言,有谷歌背书,使得社区非常活跃。
数据库相关:
1、数据库设计原则
三大范式:属性不可分、属性全依赖任一关键属性、不传递依赖。
索引:常用主键索引,主键索引=唯一索引+非空。
2、数据库注入问题
使用ORM框架(参数化查询,不使用SQL语句),限制输入格式,密码加密。
扩展->效验器(反射实现)
3、多级分类的设计
一般来说,一个分类就要设计一张表,联表查询效率低。
在同一张表中,我们可以使用类似二进制的方式定义字段,00,10,11。
4、mysql优化
建立索引。把数据量最大的表放到最外层,建立子表的查询路径。
其他:
1、git几个操作
查看/创建/删除分支:
git branch;git branch ;git branch -d
切换分支:git checkout
创建+切换分支:git checkout -b
合并某分支到当前分支:git merge
一、
1、
const cl = 100
func main() {
println(&cl,cl)
}
报错: cannot take the address of cl
常量不同于变量的在运行期分配内存,常量通常会被编译器在预处理阶段直接展开,作为指令数据使用。
2、
func main() {
type MyInt1 int
type MyInt2 = int
var i int =9
var i1 MyInt1 = i
var i2 MyInt2 = i
fmt.Println(i1,i2)
}
考点:**Go 1.9 新特性 Type Alias **
基于一个类型创建一个新类型,称之为defintion;基于一个类型创建一个别名,称之为alias。 MyInt1为称之为defintion,虽然底层类型为int类型,但是不能直接赋值,需要强转; MyInt2称之为alias,可以直接赋值。
3、
var ErrDidNotWork = errors.New(“did not work”)
func DoTheThing(reallyDoIt bool) (err error) {
if reallyDoIt {
result, err := tryTheThing()
if err != nil || result != “it worked” {
err = ErrDidNotWork
}
}
return err
}
func tryTheThing() (string,error) {
return “”,ErrDidNotWork
}
func main() {
fmt.Println(DoTheThing(true))
fmt.Println(DoTheThing(false))
}
if 语句块内的 err 变量会遮罩函数作用域内的 err 变量,结果:
4、fallthrough关键字的作用是什么?(重点)
其他语言中,switch-case 结构中一般都需要在每个 case 分支结束处显式的调用 break 语句以防止 前一个 case 分支被贯穿后调用下一个 case 分支的逻辑,go 编译器从语法层面上消除了这种重复的工作,让开发者更轻松;但有时候我们的场景就是需要贯穿多个 case,但是编译器默认是不贯穿的,这个时候 fallthrough 就起作用了,让某个 case 分支再次贯穿到下一个 case 分支。
ps: golang 的 select是一个面向channel的IO操作。
5、go 中除了加 Mutex 锁以外还有哪些方式安全读写共享变量?**
1、go -Channel,可以理解为先进先出的队列。
2、redis并发锁。
3、CAS无锁编程。
7、值传递和指针传递有什么区别
值传递:会创建一个新的副本并将其传递给所调用函数或方法
指针传递:将创建相同内存地址的新副本
需要改变传入参数本身的时候用指针传递,否则值传递
值传递或者指针传递都有可能发生逃逸,关键是有没有外部引用
8、defer语句(只)注册了一个函数调用,这个调用会延迟到defer语句所在的函数执行完毕后执行
s:=newSlice()
defer s.Add(1).Add(2).Add(4)
s.Add(3)
// 输出1234
9、pprof
pprof可以记录程序的运行信息,用于检查内存泄漏。内存泄漏会导致系统崩溃。我们还可以使用浏览器来查看系统的实时内存信息(包括CPU、内存、goroutine等的信息)。
参考: https://www.liwenzhou.com/posts/Go/performance_optimisation
net/http/pprof:使用服务器的场景
runtime/pprof:使用在非服务器应用程序的场景
http场景:
你的 HTTP 服务都会多出/debug/pprof,访问它会得到类似下面的内容:


使用命令go tool pprof url就可以获取指定profile文件,下载到本地,使用命令行进行分析:
如:
下载 cpu profile
go tool pprof http://127.0.0.1:6060/debug/pprof/profile
go tool pprof是个好用的工具:
go tool pprof [binary] [source]
binary 是应用的二进制文件,用来解析各种符号;
source 表示 profile 数据的来源,可以是本地的文件,也可以是 http 地址。
例子:
go build
./runtime_pprof.exe -cpu
//cpu.pprof是生成的本地文件
go tool pprof cpu.pprof
(pprof) 交互式界面常用命令:
topN:列出cpu占用高的函数
traces:列出函数调用栈
list 函数名:命令查看具体的函数分析
web
quit
此外,还可以通过go-torch生成火焰图
11、
panic需要等defer结束后才会向上传递。出现panic的时候,会先按照defer的后入先出的顺序执行,最后才会执行panic。
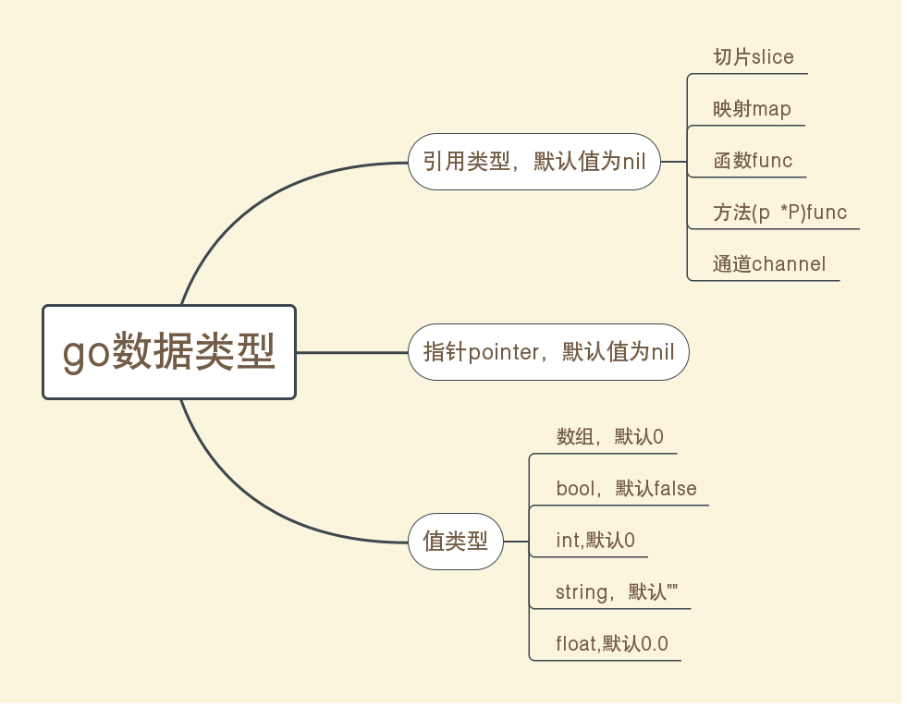
12、
Go语言中的引用类
型只有五个:
切片 映射 函数 方法 通道
nil只能赋值给上面五种引用类型的变量以及指针变量。
13、
go语言的指针不支持指针运算,指针运算包括:可以通过“&”取指针的地址、可以通过“*”取指针指向的数据
14、基本排序,哪些是稳定的
冒泡排序、直接插入排序、归并排序是稳定的排序算法。
快速排序、希尔排序、堆排序不是稳定的排序算法。
15、go struct能不能比较
可以能,也可以不能。
因为go存在不能使用==判断类型:map、slice,如果struct包含这些类型的字段,则不能比较。
这两种类型也不能作为map的key。
16、defer可以操作返回值吗?
defer类似栈操作,后进先出。
因为go的return是一个非原子性操作,比如语句 return i,实际上分两步进行,即将i值存入栈中作为返回值,然后执行跳转,而defer的执行时机正是跳转前,所以说defer执行时还是有机会操作返回值的。
17、select可以做什么
goroutine超时设置。
判断channel是否已满或空。如实现一个线程池。
18、结构体struct
一个命名为S的结构体类型将不能再包含S类型的成员:因为一个聚合的值不能包含它自身。(该限制同样适用于数组。)但是S类型的结构体可以包含*S指针类型的成员,这可以让我们创建递归的数据结构,比如链表和树结构等。
二、
1、golang 中 make 和 new 的区别?(基本必问)***
二者都是内存的分配(堆上),但是make只用于slice、map以及channel的初始化(非零值);而new用于类型的内存分配,并且内存置为零。new不常用.
- **对于引用类型(slice、map、channel)的变量,我们不光要声明它,还要为它分配内容空间,否则报错:
var s1 *S = new(S)
相当于
new(File) 和 &File{}
func main() {
var i *int
// i=new(int)
//不声明内存类型会报错
- i=10
fmt.Println(*i)
}
2、数组和切片的区别 (基本必问)***
| 数组 | 切片 | |
|---|---|---|
| 零值 | 元素类型的零值 | nil |
| 长度 | 固定长度 | 可变长度 |
| 类型 | 值类型 | 引用类型 |
nil 也是唯一可以和切片类型作比较的值
3、for range 的时候它的地址会发生变化么?
通过使用 for range 遍历切片,每次遍历操作实际上是对遍历元素的拷贝。而使用 for 遍历切片,每次遍历是通过索引访问切片元素,性能会远高于通过 for range 遍历。
因此想要优化使用 for range 遍历切片的性能,可以使用空白标识符 _ 省略每次遍历返回的切片元素,改为使用切片索引取访问切片的元素。
4、go defer,多个 defer 的顺序,defer 在什么时机会修改返回值?
①多个defer的执行顺序为“后进先出”;
②defer、return、返回值三者的执行逻辑应该是:return最先执行,return负责将结果写入返回值中;接着defer开始执行一些收尾工作;最后函数携带当前返回值退出。
无名返回值和最初的返回值相同
有名返回值和函数返回值为地址可能和最初的返回值不相同
5、 uint 类型溢出#
var a uint8 = 1
var b uint8 = 255
a-b=2
6、介绍 rune 类型?和byte的区别?(基本必问)***
在 Go 语言中支持两个字符类型,一个是 byte (实际上是 uint8 的别名),代表字符串 的单个字节的值,用来储存ASCII码,表示一个ASCII码字符;另一个是 rune(实际上是int32),代表单个 Unicode字符,常用来处理unicode或utf-8字符(一切字符),就是rune的使用范围更大。
s:=“3”;s[0] //uint8
a:=‘(’ //rune
rune字符类型int32,专用于存储unicode编码
byte字节型uint8
golang中默认存储字符串是采用utf8格式,如果直接len(中文字符), 那么会当成byte来进行处理,会乱码。使用[]rune()将utf8转换成4个字节的int32存储,可以直接计算汉字个数。
此外,range遍历字符串会按照rune为单位自动去处理。
8、调用函数传入结构体时,应该传值还是指针?
值传递:会创建一个新的副本并将其传递给所调用函数或方法
指针传递:将创建相同内存地址的新副本
需要改变传入参数本身的时候用指针传递,否则值传递
值传递或者指针传递都有可能发生逃逸,关键是有没有外部引用
9、JSON 标准库对 nil slice 和 empty slice 的处理是一致的吗?
nil slice :var s1 []int
empty slice : s1:=[]int{} || s1 := make([]int,0)
JSON 标准库对 nil slice 和 empty slice 的处理是不一致.
nil slice用于需要返回slice的函数,当函数出现异常的时候,保证函数依然会有nil的返回值。
当我们查询或者处理一个empty slice的时候,它会告诉我们返回的是一个slice,但是slice内没有任何值。
10、slice的len,cap,共享,扩容(基本必问)***
slice:=make([]int,len,cap)
slice := make([]type, len)
容量是指底层数组的大小,长度指可以使用的大小
len:切片的长度。
cap:切片的容量。默认扩容是2倍,当达到1024的长度后,按1.25倍。
扩容:每次扩容slice底层都将先分配新的容量的内存空间,再将老的数组拷贝到新的内存空间。这个操作不是并发安全的,可能导致append的数据丢失。
共享:slice的底层是对数组的引用,因此如果两个切片引用了同一个数组片段,就会形成共享底层数组。当slice发生内存的重新分配(如扩容)时,会对共享进行隔断。
11、孤儿进程,僵尸进程#
僵尸进程:
即子进程先于父进程退出后,子进程的PCB需要其父进程释放,但是父进程并没有释放子进程的PCB,这样的子进程就称为僵尸进程,僵尸进程实际上是一个已经死掉的进程。
孤儿进程:
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程。孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
但孤儿进程与僵尸进程不同的是,由于父进程已经死亡,系统会帮助父进程回收处理孤儿进程。所以孤儿进程实际上是不占用资源的,因为它终究是被系统回收了。不会像僵尸进程那样占用ID,损害运行系统。
12、go程序初始化顺序
main包->import->全局const->全局var->init()->main()
13、闭包的生命周期和作用范围
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
闭包的作用:
延长局部变量的生命周期
让函数外部能操作内部的局部变量
闭包的生命周期:
产生:在嵌套内部函数定义执行完成时就产生了闭包
死亡:在嵌套的内部函数成为垃圾对象时
例:
i := incr()
println(i()) //会递增
println(incr()()) //不会递增
14、测试文件必须以什么结尾?功能测试函数必须以什么开头?压力测试函数必须以什么开头?
_test.go
Test
Benchmark
15、panic
panic 能够改变程序的控制流,函数调用panic 时会立刻停止执行函数的其他代码,并在执行结束后在当前 Goroutine 中递归执行调用方的延迟函数调用 defer;
recover 可以中止 panic 造成的程序崩溃。它是一个只能在 defer 中发挥作用的函数,在其他作用域中调用不会发挥任何作用
Q:若干个Goroutine,其中一个panic,会发生什么?
1.运行时恐慌,当panic被抛出异常后,如果我们没有在程序中添加任何保护措施的话,程序就会打印出panic的详细情况之后,终止运行。
2.有panic的子协程里的defer能执行,主协程和其他子协程里的defer不执行或者只能执行一半,这打破了【defer函数一定执行】的规则。
Q:defer可以捕获go协程的子协程的panic吗?
不能
1、recover 只能获取同协程内的panic
2、defer 获取recover 只能在直接func 内获取,不能再跨一个func
例:
- 不能获取panic
func main() {
defer recover()
go test()
}
- 可以获取同协程内的panic
func main() {
defer recover()
test()
}
Q:recover能处理所有的异常吗?
recover并非万能的,它只对用户态下的panic关键字有效
实际上在Go语言中,是存在着一些无法恢复的“恐慌”事件的,如fatalthrow方法、fatalpanic方法等,这些都是直接通过调用 exit() 方法进行中断的,属于无法恢复的“恐慌”事件,比如:对于go1.6以上版本,如果出现 并发map读写 程序会直接崩溃
15、restful API
统一资源标识符(Uniform Resource Identifier, URI)
统一资源定位符(Uniform Resource Locator, URL)
REST是一种基于HTTP的网络应用程序的设计架构风格和开发方式。
API 是两个计算机通过互联网交换信息的接口。
RESTful架构是对MVC架构改进后所形成的一种架构,通过使用事先定义好的接口与不同的服务联系起来。在RESTful架构中,浏览器使用 GET 、POST等请求方式分别对指定的URL资源进行增删改查操作。因此,RESTful是通过URI实现对资源的管理及访问,具有扩展性强、结构清晰的特点。
RESTful常用在前后端分离应用中,后端服务器为前端服务器提供接口。浏览器向前端服务器请求视图,通过视图中包含的AJAX函数发起接口请求获取模型,即使获取后端数据失败也能呈现视图。
(与RESTful相对应的风格有JSP,RPC API)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言实验3:函数的定义
- 挑选知识付费平台不再迷茫:掌握这些技巧,轻松找到适合自己的平台
- 2024年网络安全竞赛-页面信息发现任务解析
- js原生超好用的数组分类方法Object.groupBy()
- Xilinx FPGA 权威书籍指南 基于Vivado 2018 集成开发环境
- Eureka 本机集群实现
- Jenkins创建maven项目
- Servlet重定向转发及自动加载
- Linux iostat命令
- java集合(4)