特征抽取-----机器学习pycharm软件
发布时间:2024年01月25日
导入包
from sklearn.datasets import load_iris # 方法datasets_demo()数据集使用
from sklearn.feature_extraction import DictVectorizer # 方法dict_demo()字典特征抽取用
from sklearn.feature_extraction.text import CountVectorizer # 方法count_demo()文本特征抽取、count_chinese_demo中文文本特征抽取使用
from sklearn.feature_extraction.text import TfidfVectorizer # 方法使用tfidf_demo()文本特征抽取
import jieba # 方法count_chinese_demo文本特征抽取使用
import logging # 方法count_chinese_demo文本特征抽取使用
sklearn数据集的使用
def datasets_demo():
"""
sklearn数据集的使用
:return:
"""
iris = load_iris()
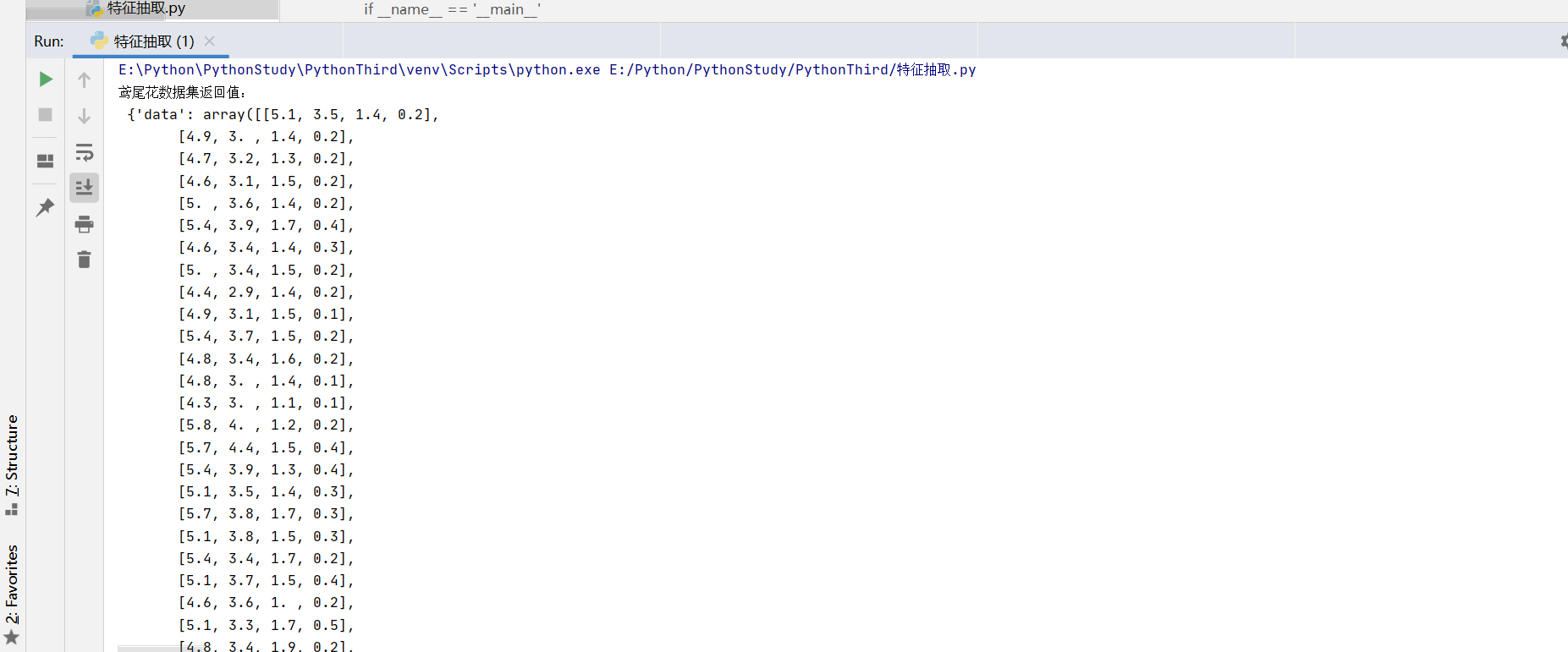
print("鸢尾花数据集返回值:\n",iris) #返回值是一个继承自字典的Bench
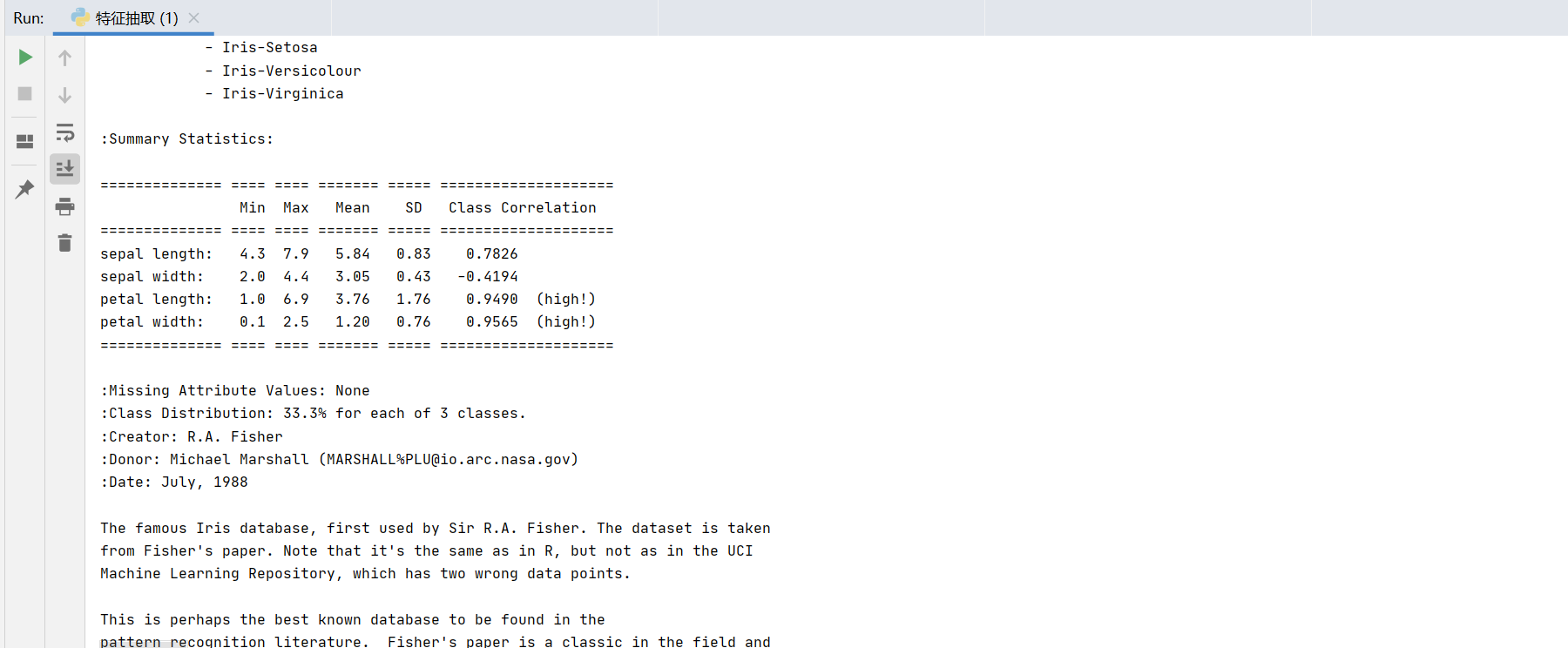
print("查看数据集描述:\n",iris["DESCR"]) #通过字典属性查看
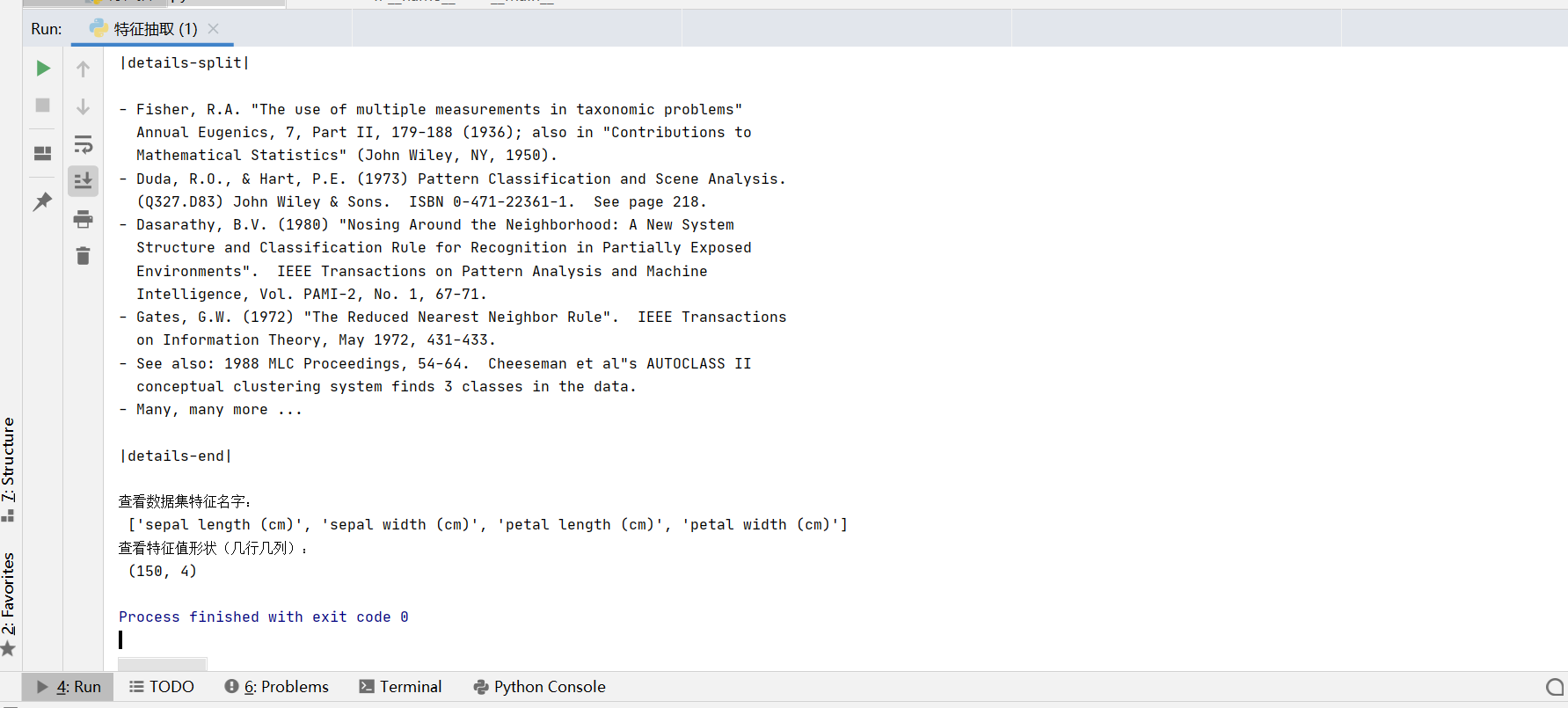
print("查看数据集特征名字:\n",iris.feature_names)
print("查看特征值形状(几行几列):\n",iris.data.shape)
return None
部分效果展示:

字典特征抽取
def dict_demo():
"""
字典特征抽取
:return:
"""
data = [{'city': '上海', 'temperature': 100}, {'city': '上海', 'temperature': 60},{'city': '北京', 'temperature': 60}]
# 1.实例化一个转换器类
transfer = DictVectorizer() # 参数默认True,即返回值是稀疏矩阵
# 2.调用fit_transform()方法
data_new = transfer.fit_transform(data)
print("特征名字:\n", transfer.get_feature_names_out())
print("data_new:\n",data_new) # 输出为稀疏矩阵,输出 值 没有0 ,即非零值按位置表示出来,
return None
效果展示:

文本特征抽取
def count_demo():
"""
文本特征提取:以单词作为特征值
:return:
"""
data = ["life is beautiful,i like it very very much","life is not beatiful,but i am smile"]
# 1.实例化一个转换器类
transfer = CountVectorizer()
# 2.调用fit_transform()方法
data_new = transfer.fit_transform(data)
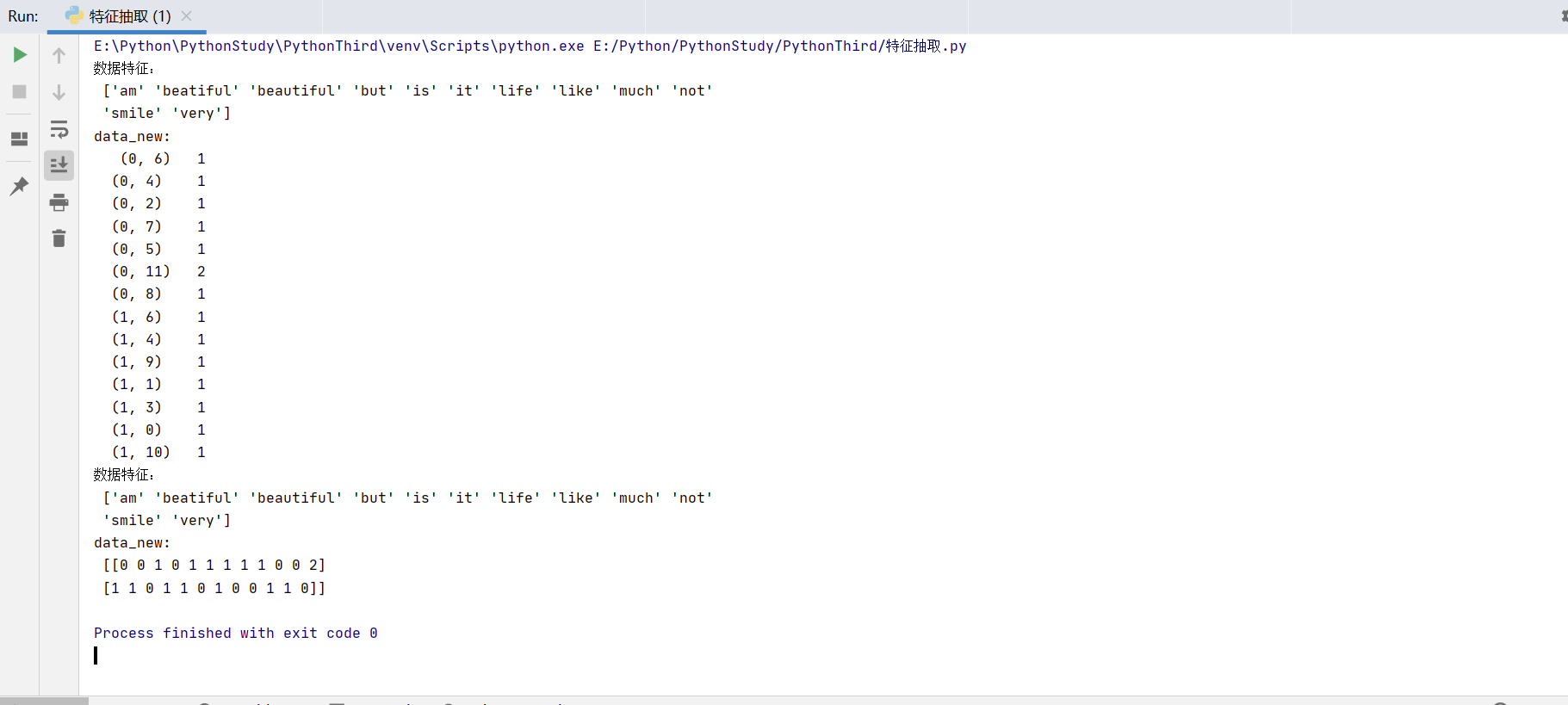
print("数据特征:\n",transfer.get_feature_names_out())
print("data_new:\n",data_new) # 返回稀疏矩阵
print("数据特征:\n", transfer.get_feature_names_out())
print("data_new:\n",data_new.toarray()) # 看二维数据,对样本出现特征词的个数进行统计
return None
效果展示:
中文文本特征抽取
def count_chinese_demo():
"""
中文文本特征提取 : 以短语作为特征值, 如果需要实现单词作为特征值的效果,有两种方法.
1.手动实现,需要用空格隔开实现,eg:生活 美好,我 非常 非常 喜欢
2.jieba分词
:return:
"""
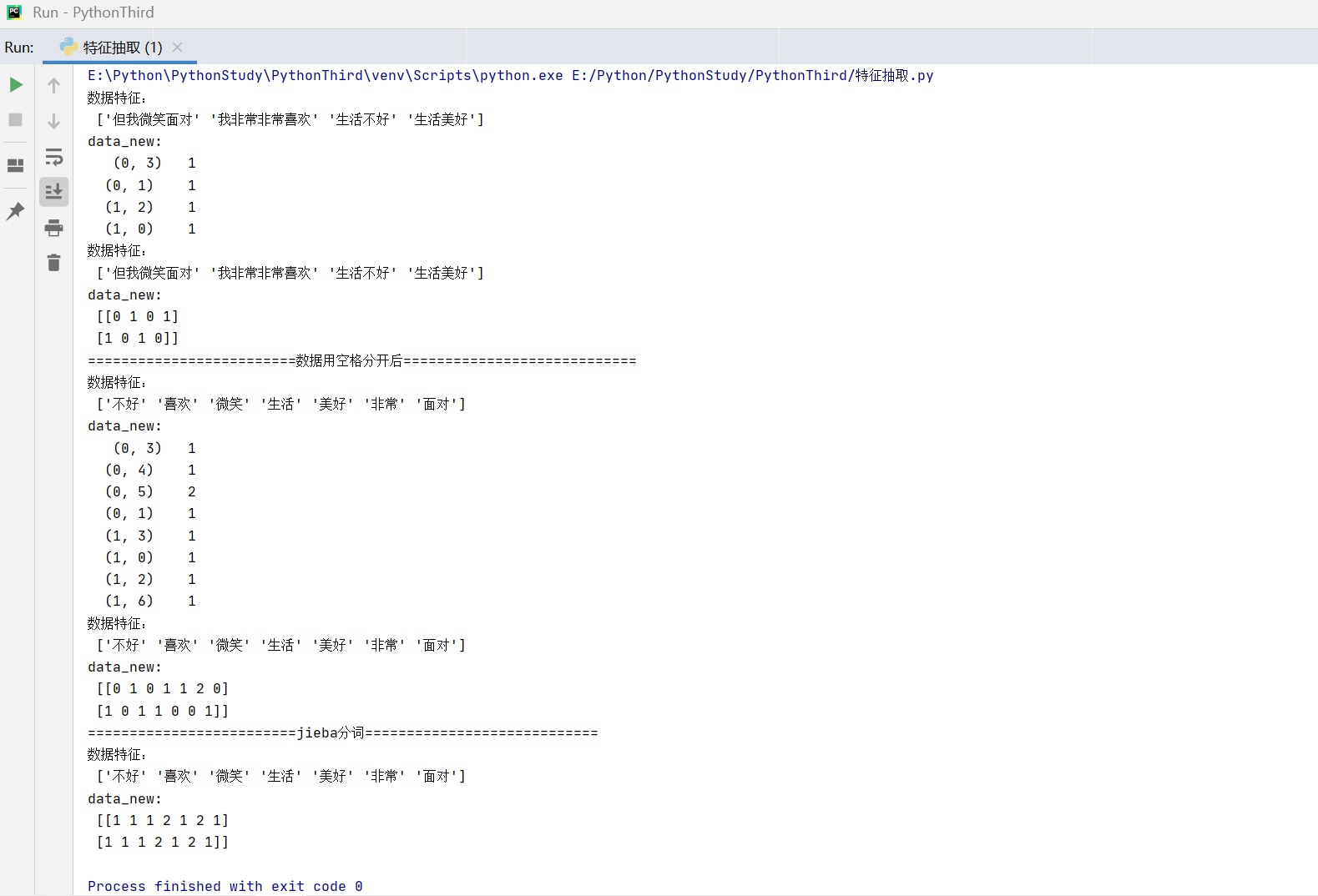
data = ["生活美好,我非常非常喜欢", "生活不好,但我微笑面对"]
data2 = ["生活 美好,我 非常 非常 喜欢","生活 不好,但 我 微笑 面对"]
# 1.实例化一个转换器类
transfer = CountVectorizer()
transfer2 = CountVectorizer()
# 2.调用fit_transform()方法
data_new = transfer.fit_transform(data)
print("数据特征:\n",transfer.get_feature_names_out())
print("data_new:\n",data_new) # 返回稀疏矩阵
print("数据特征:\n", transfer.get_feature_names_out())
print("data_new:\n", data_new.toarray()) # 看二维数据,对样本出现特征词的个数进行统计
print("=========================数据用空格分开后============================")
data_new2 = transfer2.fit_transform(data2)
print("数据特征:\n", transfer2.get_feature_names_out())
print("data_new:\n", data_new2) # 返回稀疏矩阵
print("数据特征:\n", transfer2.get_feature_names_out())
print("data_new:\n", data_new2.toarray()) # 看二维数据,对样本出现特征词的个数进行统计
print("=========================jieba分词============================")
# """
# 代码
# a = [list(jieba.cut(sentence)) for sentence in data]
# print(a)
# 输出中包含了关于jieba分词库的信息.这是因为在第一次运行jieba.cut时,它会加载分词所需的词典和模型文件,这些文件会被缓存起来以提高后续的分词速度。
# 因此,会看到类似"Building prefix dict from the default dictionary"、"Dumping model to file cache"、"Loading model cost"和"Prefix dict has been built successfully"这样的信息。
# 这些信息表明分词库已经成功加载并准备好使用,
# 而最后的输出[['生活', '美好', ',', '我', '非常', '非常', '喜欢'], ['生活', '不好', ',', '但', '我', '微笑', '面对']]则是分词后的结果。
# 在调用jieba.cut之前,使用ieba.setLogLevel(logging.INFO)代码来关闭jieba的日志输出,控制jieba输出的日志信息,使其只输出INFO级别及以上的日志,而不输出DEBUG级别的日志。
# 要注意,使用此代码要导入所需日志包 import logging
# """
# jieba.setLogLevel(logging.INFO) # 关掉日志信息
# a = [list(jieba.cut(sentence)) for sentence in data] # 此时a是一个列表
# b = " ".join([" ".join(jieba.cut(sentence)) for sentence in data] ) # 此时b是字符串,首先使用列表推导式将每个句子分词后得到的列表通过空格连接成一个字符串,然后再使用空格将这些字符串连接成一个大的字符串,最终将结果赋值给变量b
# print(a,type(a),"\n",b,type(b))
# #根据这些测试 总结为一个方法cut_word方便使用
# 1.将中文文本进行分词
jieba.setLogLevel(logging.INFO) # 关掉日志信息
data_new3 = []
for sent in data:
data_new3.append(cut_word(data))
# print(data_new3)
# 2.实例化转换器
transfer3 = CountVectorizer()
# 3.调用方法
data_final = transfer3.fit_transform(data_new3)
print("数据特征:\n", transfer3.get_feature_names_out())
print("data_new:\n", data_final.toarray()) # 看二维数据,对样本出现特征词的个数进行统计
return None
def cut_word(text):
"""
jieba分词 进行中文分词
:param text:
:return:
"""
return " ".join([" ".join(jieba.cut(sentence)) for sentence in text] )
print("==============用TF-IDF的方法进行文本特征抽取================")
def tfidf_demo():
"""
用TF-IDF的方法进行文本特征抽取
:return:
"""
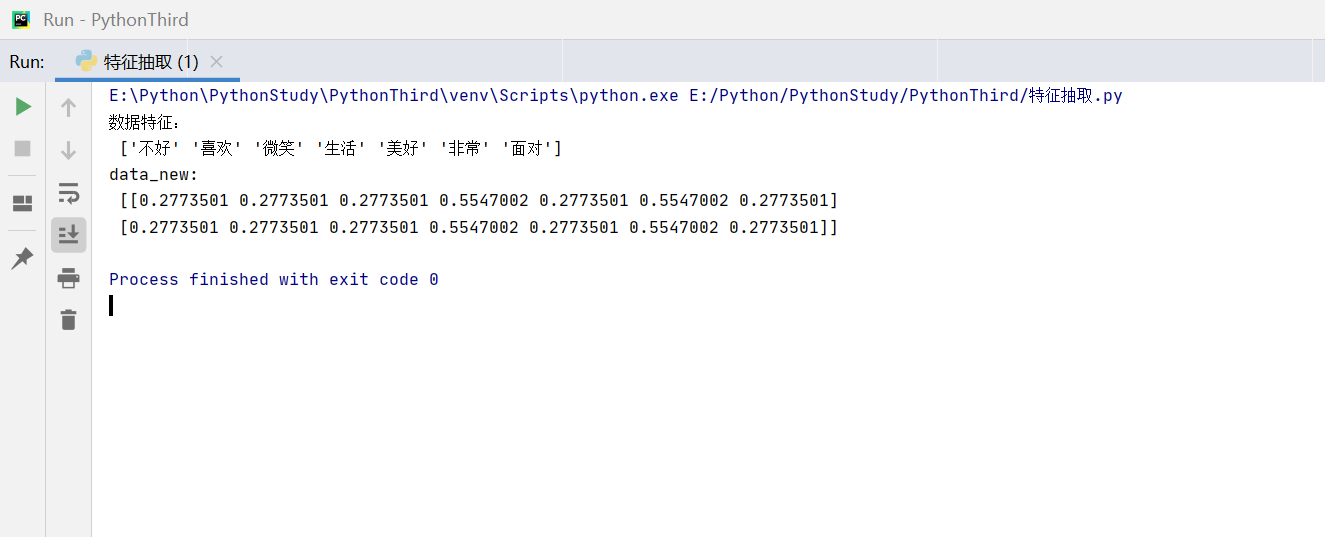
data = ["生活美好,我非常非常喜欢", "生活不好,但我微笑面对"]
# 1.将中文文本进行分词
jieba.setLogLevel(logging.INFO) # 关掉日志信息
data_new = []
for sent in data:
data_new.append(cut_word(data))
# print(data_new3)
# 2.实例化转换器
transfer3 = TfidfVectorizer()
# 3.调用方法
data_final = transfer3.fit_transform(data_new)
print("数据特征:\n", transfer3.get_feature_names_out())
print("data_new:\n", data_final.toarray()) # 看二维数据,对样本出现特征词的个数进行统计
return None
调用方法
什么抽取都写成了方法需要调用才可以输出,输出效果如“效果展示”所示
if __name__ == '__main__':
#skilearn数据集的使用
datasets_demo()
#字典特征提取
dict_demo()
# 文本特征抽取
count_demo()
#中文文本特征抽取
count_chinese_demo()
#用TF-IDF的方法进行文本特征抽取
tfidf_demo()
文章来源:https://blog.csdn.net/m0_46222433/article/details/135824710
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- JVM 如何判断一个对象可以被回收
- go基础问题
- 云服务器部署Stable Diffusion Webui从0到1总结:反复重启+循环debug
- Jwt 如何在 springboot 项目中进行接口访问鉴权
- test Symbolic Execution-03-Soot - A Java optimization framework
- 逻辑回归(LR)----机器学习
- Python下划线的五个作用介绍,初学者的妙招
- 上传文件到七牛云的相关代码(可直接用)
- Pandas实战:3分钟玩转数据加载技巧(附代码示例)
- 基础数论二:分解质因数、筛质数