设计Twitter时间线和搜索功能
设计Twitter时间线和搜索功能
设计 facebook feed 和 设计 facebook search是相同的问题
第一步:定义用例和约束
定义问题的需求和范围,询问问题去声明用例和约束,讨论假设
ps: 没有一个面试官会展示详细的问题,我们需要定义一些用例和约束
用例:
我们定义问题的范围,只是去处理以下Use Cases
- User 发布一个 tweet
- Service push tweets 给 followers, 发送 push notification 和 email
- User 查看这个 user 的 timeline (行为发生来自 user)
- User 查看 home 的 timeline (行为发生来自 User follow的人)
- User 搜搜关键词
- Service 有高可用
问题域外
- Service 推送 tweets 到 Twitter Firehose 和其他的 stream
- Service 拉取 tweet 基于User的可视化设置
- 隐藏 @reply 如果这个 User 不能回复被这个人 follow 的人
- 添加 ‘hide retweets’ 设置
- Analystics
约束和假设:
状态假设
- 常用
- Traffic 最终不被分发出去
- 发布一个 tweet 应该是很快的
- 发广播给所有的 followers 应该是快的,除非你有数百万的 followers
- 1000 万活跃用户
- 5000 万 tweet 每天 或者 150 亿 tweet 每个月
每条推文的平均传播量为10次
50 亿个tweet被传播一天
1500亿tweet被传播每个月 - 2500 亿个读请求每个月
- 100 亿搜索每个月
- 时间线
- 展示这个时间线应该很快
- Twitter是读多写少 (优化为了快速的tweet的Read)
- Ingesting tweets是写重的
- 搜索
- 搜索应该很快
- 搜索是读重的
计算使用量:
和面试官说明你是否需要进行粗略使用量估算
- 每 tweet 尺寸:
- tweet_id - 8 bytes
- user_id - 32 bytes
- text - 140 bytes
- media - 10 kb average
- Total: ~10kb
- 每个月有150 TB的新 tweet 内容
- 10 kb/tweet * 5000 万 tweet / day * 30 天 / 月
- 三年内会有5.4 PB的新 tweet
- 10w read请求 / S
- 2500 亿读请求每个月 * (400 请求每秒 / 10亿 请求每个月)
- 6000 tweets / s
- 150 亿tweet每个月 * (400 请求每秒 / 10w 请求每个月)
- 6w 个 tweet 被广播 / 每秒
- 1500 亿 tweet 每个月 * (400 请求每秒 / 10 w请求每个月)
- 4000 搜索请求每秒
- 100亿搜索每个月 * (400 请求每秒 / 10 亿请求每个月)
转换规则:
250 万秒每个月
1 request/s = 250 万 request/ 月
40 request/s = 1000 万 request/月
400 request/s = 10 亿 request/月
高视角组件设计
描绘所有重要组件的 high level design
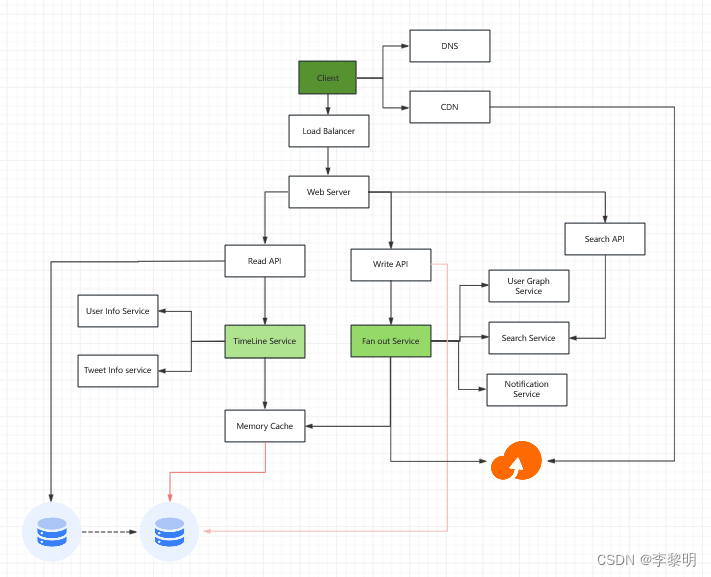
设计核心组件
Case01: User post a tweet
我们可以存储用户自己的tweet来填充这个用户时间线,我们应该讨论这个用户Case的取舍在SQL和NoSQL之间
传播tweets和构建这个home timeline 是一个笑话,传播tweets给所有的follower(6w tweets delivered on fanout per second) 将 过载一个传统的关系型数据库。我们或许想选择一个数据存储(速度快的写,比如No SQL数据库和内存),从内存中序列化的读1MB数据需要250微秒,当从SSD需要4X,从硬盘中读需要 80X.
我们可以存储媒体文件比如图片和视频在 Object Store
- Client 发送一个 tweet 到 Web Server
- Web Server 转发这个 request到 Write API server
- Write API 存储 tweet 进 SQL 数据库在用户的时间线
- Write API 连接 Fan Out Service,会做下面的事情:
- 使用 User Graph Service去查询这个User的 follower(存储在Cache中)
- 存储tweet进用户的follower的home timeline(在内存里面)
- 存储tweet进 Search Index Service,用来开启fast searching
- 存储 media 进 Object Store
- 使用 notification service去发送push 的notifications 给 follower
使用一个 Queue 去异步发送 notifications
向你的面试官说明多少代码你期望去写
如果Cache是使用Redis,我们可以使用原生的Redis List伴随着如下结构:
tweet n+2 tweet n+1 tweet n
| 8 bytes 8 bytes 1 byte | 8 bytes 8 bytes 1 byte | 8 bytes 8 bytes 1 byte |
| tweet_id user_id meta | tweet_id user_id meta | tweet_id user_id meta |
新的 tweet 将会被放进 Memory Cache, 将填充这个User 的 home timeline
我们将使用一个 public REST API:
$ curl -X POST --data '{ "user_id": "123", "auth_token": "ABC123", \
"status": "hello world!", "media_ids": "ABC987" }' \
https://twitter.com/api/v1/tweet
Response:
{
"created_at": "Wed Sep 05 00:37:15 +0000 2012",
"status": "hello world!",
"tweet_id": "987",
"user_id": "123",
...
}
内部的服务通信,我们可以使用 Remote Procedure Calls
Case02: User view the home timeline
- Client 发送一个 home timeline request 到 Web Server
- Web Server 转发请求到 Read API server
- Read API server 连接 Timeline Service,会做下面的事情:
- 得到存储在内存中的timeline数据,包含 tweet ids 和 user ids
- 查询 Tweet Info Service 去得到额外的喜喜关于 tweet ids
- 查询 User Info Service去得到额外的信息关于 user ids
REST API:
curl https://twitter.com/api/v1/home_timeline?user_id=123
Response:
{
"user_id": "456",
"tweet_id": "123",
"status": "foo"
},
{
"user_id": "789",
"tweet_id": "456",
"status": "bar"
},
{
"user_id": "789",
"tweet_id": "579",
"status": "baz"
}
Case03: User views the user timeline
- Client 发送一个 user timeline request 到 Web Server
- Web Server 转发这个 request 到 Read API server
- Read API 从SQL 数据库接收 User Timeline
这个 Rest API应该是和 home timeline相同的,除了所有的 tweets应该才子与 User,而不是User 的 follower
Case04: User searches keywords
- Client 发送一个 search request 到 Web Server
- Web Server 转发 request 到 Search API server
- Search API 和 Search Service通信,会做下面的事情:
- Parses/tokenizes 查询 query,决定什么需要被 search
- 移除 markup
- 分解 text 进 terms
- 修复 typos
- 格式化首字母
- 转换query去使用bool操作
- 查询 Search Cluster(比如 Lucene) 为了结果
- 去集群中查询 query
- 合并,排名,排序,然后返回结果
Rest API:
$ curl https://twitter.com/api/v1/search?query=hello+world
扩展设计
开始思考这四件事:
- 负载测试
- 分析系统瓶颈
- 定位瓶颈和分析不同方案和好处
- 重复
讨论初始化的Design,定位瓶颈的过程是非常重要的。比如:添加 Load Balancer到多Web Server会产生什么问题? CDN 呢?数据库主从架构呢?什么是最优解?
我么将介绍一些组件来完成这个Design并且去定位扩展性问题,内部的load balancer不被展示去减少
杂乱。
- DNS
- CDN
- Load balancer
- Horizontal scaling
- Web server (reverse proxy)
- API server (application layer)
- Cache
- Relational database management system (RDBMS)
- SQL write master-slave failover
- Master-slave replication
- Consistency patterns
- Availability patterns
分析设计发现,Fanout Service是潜在的瓶颈,Twitter 用户的数百万 follower会花费数分钟来完成广播流程。这可能导致推文 @replies 出现竞争状况,我们可以通过在服务时重新排序堆文件来缓解这种情况。
我们还可以避免将来自高关注度用户的推文散开,代替,我们可以搜索去找到高关注度用户的 tweet,合并搜索结果伴随着用户的 home timeline结果。然后重新排序 tweet 在服务器时间。
额外的优化包括:
- 保持每个 home timeline只有若百个 tweets 在内存中
- 保持只有活跃用户的 home timeline info在内存中
- 如果一个 user 在过去的30天不活跃的化,我们可以从 SQL Database重新构建timeline
- 查询 User Graph Service 去决定谁是这个 user 正在 following
- 从数据库获取到 tweets 然后添加他们进内存
- 如果一个 user 在过去的30天不活跃的化,我们可以从 SQL Database重新构建timeline
- 只存储一个月的tweets进 Tweet Info Service
- 只存储活跃用户进 User Info Service
- Search Cluster 有可能需要保存 tweets 进内存去保证低延迟
我们也想要定位在数据库中的瓶颈。
尽管 Memory Cache 可以减少数据库的负载,仅仅SQL读取副本不足以处理缓存缺失。我们可能需要采用额外的SQL扩展模式。
大量的写入将压倒单个SQL写主从,这也表明需要额外的扩展技术。
We should also consider moving some data to a NoSQL Database.
Additional talking points
Additional topics to dive into, depending on the problem scope and time remaining.
NoSQL
Caching
- Where to cache
- What to cache
- When to update the cache
Asynchronism and microservices
Communications
- Discuss tradeoffs:
- External communication with clients - HTTP APIs following REST
- Internal communications - RPC
- Service discovery
Security
Refer to the security section.
Latency numbers
See Latency numbers every programmer should know.
Ongoing
- Continue benchmarking and monitoring your system to address bottlenecks as they come up
- Scaling is an iterative process
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- mysql如何取出json里某一个字段或计算两数
- 机器学习-线性回归实践
- leetcode 525. 连续数组(优质解法)
- 网络通信(9)-C#TCP服务端实例
- 感恩客户相伴23载,泛微2024持续向上!
- 合道篇--(2)-高速PCB评审关键点
- 《PCI Express体系结构导读》随记 —— 第II篇 第13章 PCI总线与虚拟化技术(1)
- 云服务器租用价格表,阿里云腾讯云华为云2024年优惠对比
- 利用阿里通义千问和Semantic Kernel,10分钟搭建大模型知识助手!
- Python入门介绍