浅谈Redis分布式锁(下)
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
自定义Redis分布式锁的弊端
在上一篇我们自定义了一个Redis分布式锁,用来解决多节点定时任务的拉取问题(避免任务重复执行):

但仍然存在很多问题:
- 加锁操作不是原子性的(setnx和expire两步操作不是原子性的,中间宕机会导致死锁)
public boolean tryLock(String lockKey, String value, long expireTime, TimeUnit timeUnit) {
// 1.先setnx
Boolean lock = redisTemplate.opsForValue().setIfAbsent(lockKey, value);
if (lock != null && lock) {
// 2.再expire
redisTemplate.expire(lockKey, expireTime, timeUnit);
return true;
} else {
return false;
}
}
当然啦,高版本的SpringBoot Redis依赖其实提供了加锁的原子性操作:
/**
* 尝试上锁:setNX + expire
*
* @param lockKey 锁
* @param value 对应的值
* @param expireTime 过期时间
* @param timeUnit 时间单位
* @return
*/
@Override
public boolean tryLock(String lockKey, String value, long expireTime, TimeUnit timeUnit) {
try {
// 高版本SpringBoot的setIfAbsent可以设置4个参数,一步到位
redisTemplate.opsForValue().setIfAbsent(lockKey, value, expireTime, timeUnit);
return true;
} catch (Exception e) {
e.printStackTrace();
}
return false;
}从 Redis 2.6.12 版本开始(现在6.x了...),?SET 命令的行为可以通过一系列参数来修改,也因为 SET 命令可以通过参数来实现和 SETNX 、 SETEX 和 PSETEX 三个命令的效果,所以将来的 Redis 版本可能会废弃并最终移除 SETNX 、 SETEX 和 PSETEX 这三个命令。
- 解锁操作不是原子性的(可能造成不同节点之间互相删锁)

虽然上一篇设计的unLock()不是原子操作,但可以避免不同节点之间互相删锁
public boolean unLock(String lockKey, String value) {
// 1.获取锁的value,存的是MACHINE_ID
String machineId = (String) redisTemplate.opsForValue().get(lockKey);
if (StringUtils.isNotEmpty(machineId) && machineId.equals(value)) {
// 2.只能删除当前节点设置的锁
redisTemplate.delete(lockKey);
return true;
}
return false;
}- 畏难情绪作祟,不想考虑锁续期的问题,企图采用队列的方式缩减定时任务执行时间,直接把任务丢到队列中。但实际上可能存在任务堆积,个别情况下会出现:上次已经拉取某个任务并丢到Redis队列中,但由于队列比较繁忙,该任务还未被执行,数据库状态也尚未更改为status=1(已执行),结果下次又拉取一遍,重复执行(简单的解决策略是:虽然无法阻止入队,但是出队消费时可以判断where status=0后执行)

引入Redis Message Queue会让系统变得更加复杂,我之前就因为使用了上面的模型导致各种偶发性的BUG,非常不好排查。一般来说,定时任务应该设计得简单点:

也就是说,绕来绕去,想要设计一个较完备的Redis分布式锁,必须至少解决3个问题:
- 加锁原子性(setnx和expire要保证原子性,否则会容易发生死锁)
- 解锁原子性(不能误删别人的锁)
- 需要考虑业务/定时任务执行的时间,并为锁续期
如果不考虑性能啥的,加解锁原子性都可以通过lua脚本实现(利用Redis单线程的特性):

一次执行一个脚本,要么成功要么失败,不会和其他指令交错执行。
最难的是如何根据实际业务的执行时间给锁续期!虽然我们已经通过判断MACHINE_ID避免了不同节点互相删除锁:
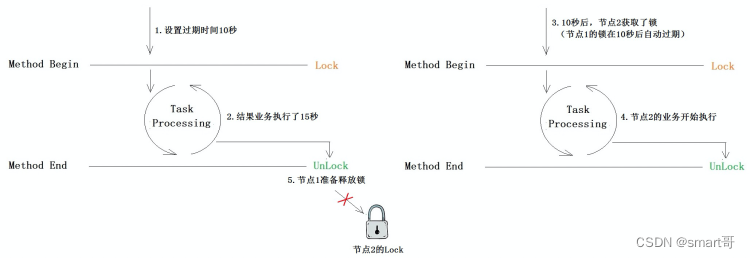
但本质上我们需要的是:
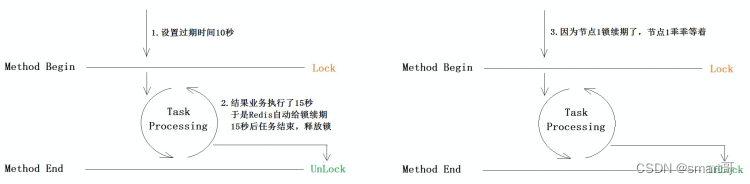
本文我们的主要目标就是实现锁续期!
好在Redisson已经实现了,所以目标又变成:了解Redisson的锁续期机制。
Redisson案例
Redisson环境搭建
server:
port: 8080
spring:
redis:
host:
password:
database: 1
# 调整控制台日志格式,稍微精简一些(非必要操作)
logging:
pattern:
console: "%d{yyyy-MM-dd HH:mm:ss} - %thread - %msg%n"<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--大家也可以单独引入Redisson依赖,然后通过@Configuration自己配置RedissonClient-->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.6</version>
</dependency>
</dependencies>然后就可以在test包下测试了~
lock()方法初探
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class RLockTest {
@Autowired
private RedissonClient redissonClient;
@Test
public void testRLock() throws InterruptedException {
new Thread(this::testLockOne).start();
new Thread(this::testLockTwo).start();
TimeUnit.SECONDS.sleep(200);
}
public void testLockOne(){
try {
RLock lock = redissonClient.getLock("bravo1988_distributed_lock");
log.info("testLockOne尝试加锁...");
lock.lock();
log.info("testLockOne加锁成功...");
log.info("testLockOne业务开始...");
TimeUnit.SECONDS.sleep(50);
log.info("testLockOne业务结束...");
lock.unlock();
log.info("testLockOne解锁成功...");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public void testLockTwo() {
try {
RLock lock = redissonClient.getLock("bravo1988_distributed_lock");
log.info("testLockTwo尝试加锁...");
lock.lock();
log.info("testLockTwo加锁成功...");
log.info("testLockTwo业务开始...");
TimeUnit.SECONDS.sleep(50);
log.info("testLockTwo业务结束...");
lock.unlock();
log.info("testLockTwo解锁成功...");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}结果
2023-12-21 14:24:33 - Thread-3 - testLockTwo尝试加锁...
2023-12-21 14:24:33 - Thread-2 - testLockOne尝试加锁...
=====> testLockOne()执行过程中,testLockTwo()一直阻塞 <=====
2023-12-21 14:24:33 - Thread-2 - testLockOne加锁成功...
2023-12-21 14:24:33 - Thread-2 - testLockOne业务开始...
2023-12-21 14:25:23 - Thread-2 - testLockOne业务结束...
2023-12-21 14:25:23 - Thread-2 - testLockOne解锁成功...
=====> testLockOne()执行结束释放锁,testLockTwo()抢到锁 <=====
2023-12-21 14:25:23 - Thread-3 - testLockTwo加锁成功...
2023-12-21 14:25:23 - Thread-3 - testLockTwo业务开始...
2023-12-21 14:26:13 - Thread-3 - testLockTwo业务结束...
2023-12-21 14:26:13 - Thread-3 - testLockTwo解锁成功...
通过上面的代码,我们有以下疑问:
- lock()方法是原子性的吗?
- lock()有设置过期时间吗?是多少?
- lock()实现锁续期了吗?
- lock()方法怎么实现阻塞的?又怎么被唤醒?
先忘了这些,跟着我们走一遍lock()源码就明白了。
lock()源码解析
lock()加锁,去除异常的情况,无非加锁成功、加锁失败两种情况,我们先看加锁成功的情况。
流程概览
我们从这段最简单的代码入手:
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest
public class RLockTest {
@Autowired
private RedissonClient redissonClient;
@Test
public void testLockSuccess() throws InterruptedException {
RLock lock = redissonClient.getLock("bravo1988_distributed_lock");
log.info("准备加锁...");
lock.lock();
log.info("加锁成功...");
TimeUnit.SECONDS.sleep(300);
}
}大家跟着我们先打几个断点(SpringBoot2.3.4):



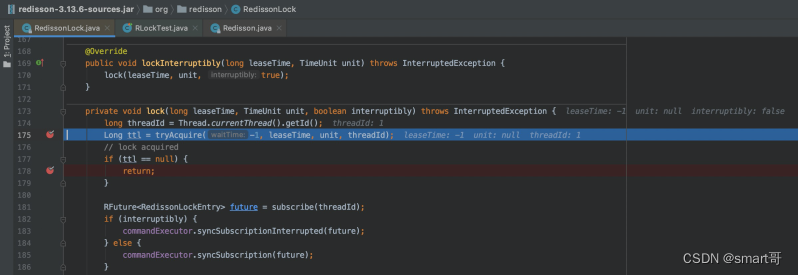




注意啊,把截图中能看到的断点都打上。
OK,接着大家自己启动DEBUG,感受一下大致流程,然后看下面的注释:
// redisson.lock()
Override
public void lock() {
try {
lock(-1, null, false);
} catch (InterruptedException e) {
throw new IllegalStateException();
}
}
// 为了方便辨认,我直接把传进来的参数写在参数列表上
private void lock(long leaseTime=-1, TimeUnit unit=null, boolean interruptibly=false) throws InterruptedException {
// 获取当前线程id
long threadId = Thread.currentThread().getId();
// 尝试上锁。上锁成功返回null,上锁失败返回ttl
Long ttl = tryAcquire(-1, leaseTime=-1, unit=null, threadId=666);
// 上锁成功,方法结束,回到主线程执行业务啦(后台有个定时任务在给当前锁续期)
if (ttl == null) {
return;
}
// 上锁成功就不走下面的流程了,所以这里直接省略
// 略:加锁失败后续流程...
}
// 尝试上锁。上锁成功返回null,上锁失败返回【当前已经存在的锁】的ttl,方便调用者判断多久之后能重新获取锁
private Long tryAcquire(long waitTime=-1, long leaseTime=-1, TimeUnit unit=null, long threadId=666) {
/**
* 有两次调用:1.tryAcquireAsync()返回Future 2.从Future获取异步结果(异步结果就是ttl)
* 重点是tryAcquireAsync()
*/
return get(tryAcquireAsync(waitTime=-1, leaseTime=-1, unit=null, threadId=666));
}
// 获取过期时间(非重点)
protected final <V> V get(RFuture<V> future) {
return commandExecutor.get(future);
}
// 重点,加锁后返回RFuture,内部包含ttl。调用本方法可能加锁成功,也可能加锁失败,外界可以通过ttl判断
private <T> RFuture<Long> tryAcquireAsync(long waitTime=-1, long leaseTime=-1, TimeUnit unit=null, long threadId=666) {
// lock()默认leaseTime=-1,所以会跳过if
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 执行lua脚本,尝试加锁并返回RFuture。这个方法是异步的,其实是把任务提交给线程池
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(
waitTime=-1,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()=30秒,
TimeUnit.MILLISECONDS,
threadId=666,
RedisCommands.EVAL_LONG);
// 设置回调方法,异步线程与Redis交互得到结果后会回调BiConsumer#accept()
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
// 发生异常时直接return
if (e != null) {
return;
}
// 说明加锁成功
if (ttlRemaining == null) {
// 启动额外的线程,按照一定规则给当前锁续期
scheduleExpirationRenewal(threadId);
}
});
// 返回RFuture,里面有ttlRemaining
return ttlRemainingFuture;
}
// 执行lua脚本尝试上锁
<T> RFuture<T> tryLockInnerAsync(long waitTime=-1, long leaseTime=30*1000, TimeUnit unit=毫秒, long threadId=666, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
/**
* 大家去看一下evalWriteAsync()的参数列表,看看每个参数都代表什么,就能理解KEYS[]和ARGV[]以及整个脚本什么意思了
* 如果你仔细看lua脚本,就会明白:加锁成功时返回ttlRemaining=null,加锁失败时返回ttlRemaining=xxx(上一个锁还剩多少时间)
*
* 另外,我们自定义的Redis分布式锁采用了IdUtil生成节点id,和getLockName(threadId)本质是一样的
*/
return evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
// 向Redis服务器发送脚本并返回RFuture,大家可以近似看成:往线程池提交一个任务,然后将异步结果封装到CompletableFuture
protected <T> RFuture<T> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object... params) {
CommandBatchService executorService = createCommandBatchService();
RFuture<T> result = executorService.evalWriteAsync(key, codec, evalCommandType, script, keys, params);
if (!(commandExecutor instanceof CommandBatchService)) {
executorService.executeAsync();
}
return result;
}示意图:
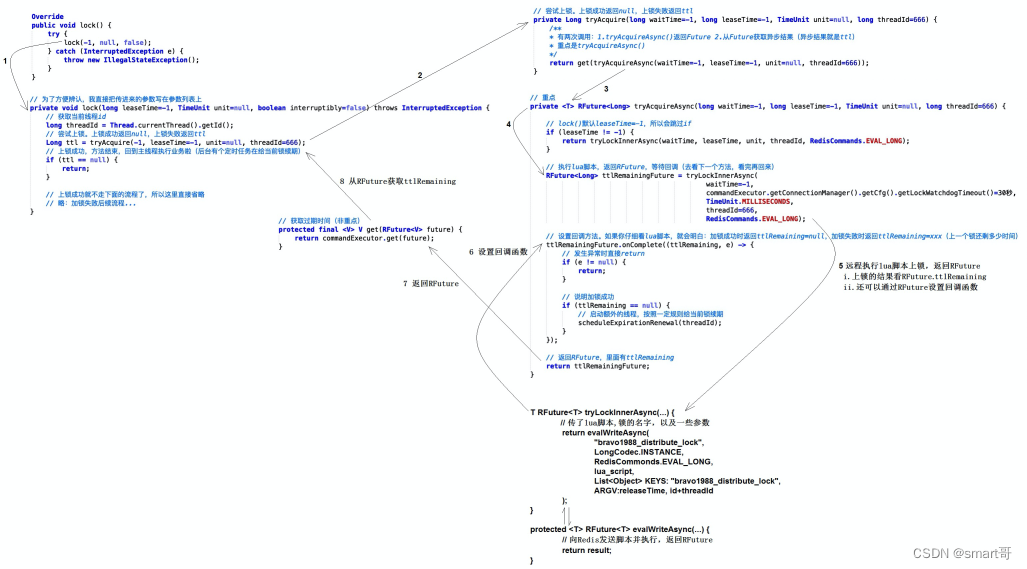
整个流程比较简单,只有两个难点:
- lua脚本写了啥
- ttlRemainingFuture.onComplete()有什么作用
lua脚本解读
大家可以通过evalWriteAsync()的参数列表推导出KEYS、ARGV分别是什么:
KEYS[] => Collections.singletonList(getName())
ARGV[] => internalLockLeaseTime, getLockName(threadId)
-- 如果不存在锁:"bravo1988_distributed_lock"
if (redis.call('exists', KEYS[1]) == 0) then
-- 使用hincrby设置锁:hincrby bravo1988_distributed_lock a1b2c3d4:666 1
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 设置过期时间。ARGV[1]==internalLockLeaseTime
redis.call('pexpire', KEYS[1], ARGV[1]);
-- 返回null
return nil;
end;
-- 如果当前节点已经设置"bravo1988_distributed_lock"(注意,传了ARGV[2]==节点id)
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
-- 就COUNT++,可重入锁
redis.call('hincrby', KEYS[1], ARGV[2], 1);
-- 设置过期时间。ARGV[1]==internalLockLeaseTime
redis.call('pexpire', KEYS[1], ARGV[1]);
-- 返回null
return nil;
end;
-- 已经存在锁,且不是当前节点设置的,就返回锁的过期时间ttl
return redis.call('pttl', KEYS[1]);总的来说,Redisson设计的分布式锁是采用hash结构:
LOCK_NAME(锁的KEY)+ CLIENT_ID(节点ID)+ COUNT(重入次数)

回调函数的作用
之前我们已经学过CompletableFuture的回调机制:

RFuture#onComplete()和它很相似:
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
// 发生异常时直接return
if (e != null) {
return;
}
// 说明加锁成功
if (ttlRemaining == null) {
// 启动额外的线程,按照一定规则给当前锁续期
scheduleExpirationRenewal(threadId);
}
});onComplete()应该也是把回调函数推到stack中,方便后面异步线程弹栈执行。
至此,我们已经解决了之前的两个问题:
- lua脚本是什么意思(见注释)
- ttlRemainingFuture.onComplete()有什么作用(设置回调函数,等会儿会有线程调用)
虽然在CompletableFuture中已经强调过,这里还是要提一下:被回调的不是onComplete(BiConsumer),而是BiConsumer#accept()。主线程在调用onComplete(BiConsumer)时把它作为参数传入,然后被推入栈中:
BiConsumer consumer = (ttlRemaining, e) -> {
// 发生异常时直接return
if (e != null) {
return;
}
// 说明加锁成功
if (ttlRemaining == null) {
// 启动额外的线程,按照一定规则给当前锁续期
scheduleExpirationRenewal(threadId);
}
}Redisson异步回调机制
现在已经确定了尝试加锁后会返回RFuture,并且我们可以通过RFuture做两件事:
- 通过RFuture获取ttlRemaining,也就是上一个锁的过期时间,如果为null则本次加锁成功,否则加锁失败,需要等待
- 通过RFuture设置回调函数
现在疑问是:
- 异步线程是谁,哪来的?
- onComplete()设置的回调函数是干嘛的?
- 回调时的参数(ttlRemaining, e)哪来的?
1、3两个问题非常难,源码比较绕,这里就带大家感性地体验一下,有兴趣可以自己跟源码了解。清除刚才的全部断点,只留下:

再次DEBUG,线程会先到达return ttlRemainingFuture,随后回调BiConsumer#accept():

回调时线程变了:

大家有兴趣可以自己顺着调用栈逆推回去,还是比较复杂的,涉及到NIO、Promise等,源头还是在线程池,但其中又设计了Listeners的收集和循环唤醒:
protected <T> RFuture<T> evalWriteAsync(String key, Codec codec, RedisCommand<T> evalCommandType, String script, List<Object> keys, Object... params) {
CommandBatchService executorService = createCommandBatchService();
RFuture<T> result = executorService.evalWriteAsync(key, codec, evalCommandType, script, keys, params);
if (!(commandExecutor instanceof CommandBatchService)) {
executorService.executeAsync();
}
return result;
}总之,目前为止我们只需要知道:

我们虽然不知道onComplete()具体如何实现回调(比CompletableFuture复杂得多),但是我们知道锁续期和RFuture的回调机制相关!
Redisson如何实现锁续期

最终会进入:
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
/**
* 启动一个定时器:Timeout newTimeout(TimerTask task, long delay, TimeUnit unit);
* 执行规则是:延迟internalLockLeaseTime/3后执行
* 注意啊,每一个定时任务只执行一遍,而且是延迟执行。
*
* 那么问题就来了:
* 1.internalLockLeaseTime/3是多久呢?
* 2.如果定时任务只执行一遍,似乎解决不了问题啊,本质上和我们手动设置过期时间一样:多久合适呢?
*/
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
// 定时任务的目的是:重新执行一遍lua脚本,完成锁续期,把锁的ttl拨回到30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
// 设置了一个回调
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
// 如果宕机了,就不会续期了
return;
}
// 如果锁还存在(没有unLock,说明业务还没结束),递归调用当前方法,不断续期
if (res) {
// reschedule itself
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
/**
* 重新执行evalWriteAsync(),和加锁时的lua脚本比较类似,但有点不同
* 这里设置expire的参数也是internalLockLeaseTime
*
* 看来我们不得不去调查一下internalLockLeaseTime了!
*/
protected RFuture<Boolean> renewExpirationAsync(long threadId) {
return evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return 1; " +
"end; " +
"return 0;",
Collections.singletonList(getName()),
internalLockLeaseTime, getLockName(threadId));
}如果你给renewExpirationAsync()打上断点,会发现每隔10秒,定时任务就会执行一遍:
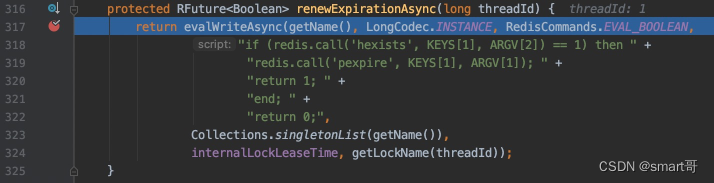
联想到定时任务的delay是internalLockLeaseTime/3,所以推测internalLockLeaseTime为30秒。
点击internalLockLeaseTime,很容易跳转到对应的字段:
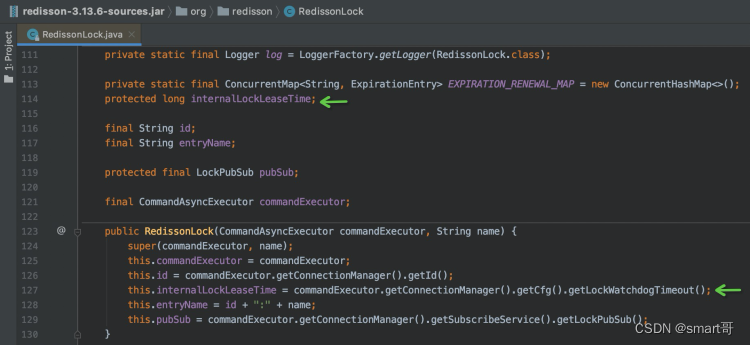
再顺着getLockWatchdogTimeout()跳转,很快就会发现



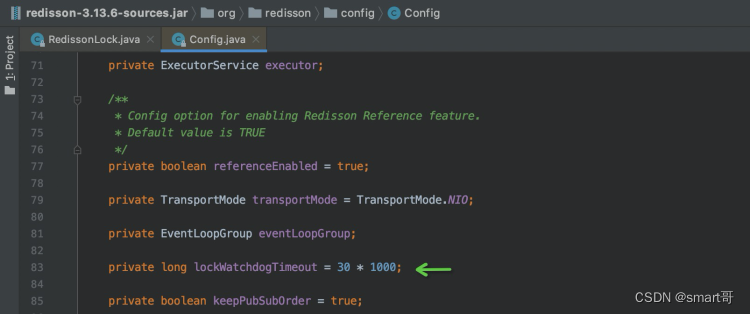
确实是30秒。
梳理一下所谓的Watchdog锁续期机制:
- lock()第一次成功加锁时,设置的锁过期时间默认30秒,这个值来自Watchdog变量
// 重点
private <T> RFuture<Long> tryAcquireAsync(long waitTime=-1, long leaseTime=-1, TimeUnit unit=null, long threadId=666) {
// lock()默认leaseTime=-1,所以会跳过if
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 执行lua脚本加锁,返回RFuture。第二个参数就是leaseTime,来自LockWatchdogTimeout!!!
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(
waitTime=-1,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()=30秒,
TimeUnit.MILLISECONDS,
threadId=666,
RedisCommands.EVAL_LONG);
// 设置回调方法
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
// 发生异常时直接return
if (e != null) {
return;
}
// 说明加锁成功
if (ttlRemaining == null) {
// 启动额外的线程,按照一定规则给当前锁续期
scheduleExpirationRenewal(threadId);
}
});
// 返回RFuture,里面有ttlRemaining
return ttlRemainingFuture;
}
// 执行lua脚本上锁
<T> RFuture<T> tryLockInnerAsync(long waitTime=-1, long leaseTime=30*1000, TimeUnit unit=毫秒, long threadId=666, RedisStrictCommand<T> command) {
// 略...
}- onComplete()设置回调,等Redis调用回来后,异步线程回调BiConsumer#accept(),进入scheduleExpirationRenewal(threadId),开始每隔internalLockLeaseTime/3时间就给锁续期

和加锁一样,执行lua脚本其实很快,所以这里的future.onComplete()虽说是异步,但很快就会被调用,然后就会递归调用renewExpiration(),然后又是一个TimerTask(),隔internalLockLeaseTime/3后又给锁续期。
也就是说,Redisson的Watchdog定时任务虽然只延迟执行一次,但每次调用都会递归,所以相当于:重复延迟执行。
还记得之前学习CompletableFuture时我写的一行注释吗:

也就是说,只要主线程的任务不结束,就会一直给锁续期。
锁释放有两种情况:
- 任务结束,主动unLock()删除锁
redisson.lock();
task();
redisson.unLock();- 任务结束,不调用unLock(),但由于守护线程已经结束,不会有后台线程继续给锁续期,过了30秒自动过期
上面我们探讨的都是加锁成功的流程,直接ttl=null就返回了,后面一大坨都是加锁失败时的判断逻辑,其中涉及到:
- while(true)死循环
- 阻塞等待
- 释放锁时Redis的Publish通知(在后面的unLock流程会看到)
- 其他节点收到锁释放的信号后重新争抢锁

整个过程还是非常复杂的,大家有精力可以自行百度了解,后面介绍unLock()时也会涉及一部分加锁失败相关内容。
unLock()源码解析
有了lock()的经验,unLock()就简单多了:


相信大家还是能推断出KEYS[]和ARGV[],这里就直接给出答案了:
-- 参数解释:
-- KEYS[1] => "bravo1988_distributed_lock"
-- KEYS[2] => getChannelName()
-- ARGV[1] => LockPubSub.UNLOCK_MESSAGE
-- ARGV[2] => internalLockLeaseTime
-- ARGV[3] => getLockName(threadId)
-- 锁已经不存在,返回null
if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then
return nil;
end;
-- 锁还存在,执行COUNT--(重入锁的反向操作)
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1);
-- COUNT--后仍然大于0(之前可能重入了多次)
if (counter > 0) then
-- 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[2]);
return 0;
-- COUNT--后小于等于0,删除锁,并向对应的Channel发送消息(NIO),消息类型是LockPubSub.UNLOCK_MESSAGE(锁释放啦,快来抢~)
else
redis.call('del', KEYS[1]);
redis.call('publish', KEYS[2], ARGV[1]);
return 1;
end;
return nil;也就是说,当一个锁被释放时,原先持有锁的节点会通过NIO的Channel发送LockPubSub.UNLOCK_MESSAGE,告诉其他订阅的Client:我已经释放锁啦,快来抢啊!此时原本阻塞的其他节点就会重新竞争锁。
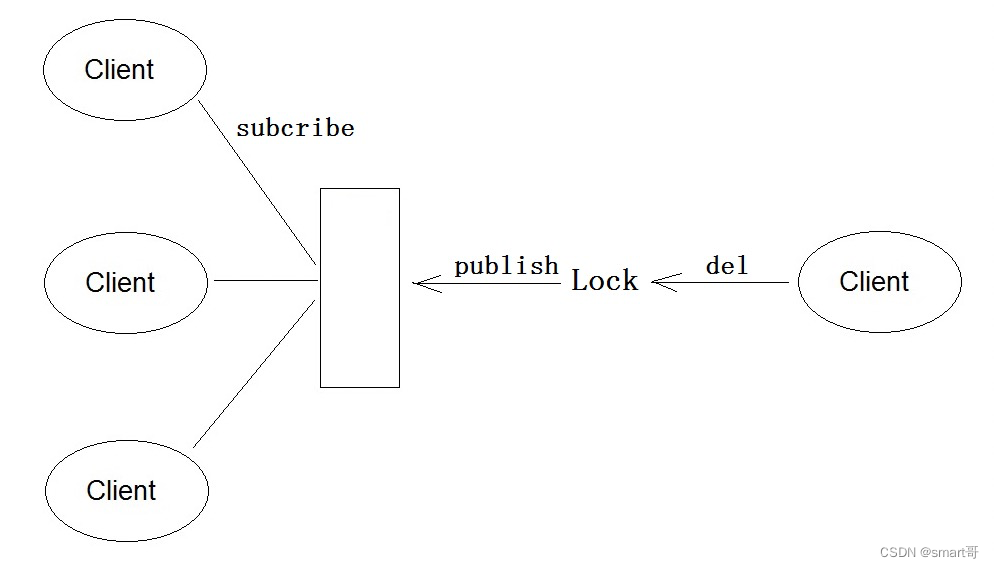

而所谓重入和反重入,简单来说就是:
// 加锁三次
redisson.lock();
redisson.lock();
redisson.lock();
// 执行业务
executeTask();
// 相应的,就要解锁三次
redisson.unLock();
redisson.unLock();
redisson.unLock();实际开发不会这样调用,但有时会出现子父类方法调用或者同一个线程反复调用使用同一把锁的多个方法,就会发生锁的重入(COUNT++),而当这些方法执行完毕逐个弹栈的过程中就会逐个unLock()解锁(COUNT--)。
lock(leaseTime, unit):自定义过期时间、且不续期
lock()默认会开启定时任务对锁进行续期,但Redisson还提供了另一个lock方法:

两个lock()唯一的区别是,内部调用lock()时,一个传了leaseTime=-1,另一个传了我们自己的leaseTime。对于外部调用者来说:
redisson.lock();
redisson.lock(-1, null);这两种写法其实一样。
当然了,通常会传入有意义的leaseTime:

这种写法除了更改了锁的默认ttl时间外,还阉割了锁续期功能。也就是说,10秒后如果任务还没执行完,就会和我们手写的Redis分布式锁一样,自动释放锁。
为什么锁续期的功能失效了呢?留给大家自己解答,这里只给出参考答案:
// 重点
private <T> RFuture<Long> tryAcquireAsync(long waitTime=-1, long leaseTime=-1, TimeUnit unit=null, long threadId=666) {
// lock()默认leaseTime=-1,会跳过这个if执行后面的代码。但如果是lock(10, TimeUnit.SECONDS),会执行if并跳过后面的代码。
if (leaseTime != -1) {
// 其实和下面的tryLockInnerAsync()除了时间不一样外,没什么差别
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 但由于上面直接return了,所以下面的都不会执行!!
/*
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(
waitTime=-1,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()=30秒,
TimeUnit.MILLISECONDS,
threadId=666,
RedisCommands.EVAL_LONG);
// 设置回调方法(不会执行!!)
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
// 发生异常时直接return
if (e != null) {
return;
}
// 说明加锁成功
if (ttlRemaining == null) {
// 启动额外的线程,按照一定规则给当前锁续期
scheduleExpirationRenewal(threadId);
}
});
// 不会执行!!
return ttlRemainingFuture;
*/
}
// 执行lua脚本加锁
<T> RFuture<T> tryLockInnerAsync(long waitTime=-1, long leaseTime=30*1000, TimeUnit unit=毫秒, long threadId=666, RedisStrictCommand<T> command) {
// 略...
}也就是说,直接执行lua加锁就返回了,没有机会启动定时任务和递归...
tryLock()系列:让调用者自行决定加锁失败后的操作
之前我们已经观察到,如果多个节点都调用lock(),那么没获取到锁的节点线程会阻塞,直到原先持有锁的节点删除锁并publish LockPubSub.UNLOCK_MESSAGE 。
但如果调用者不希望阻塞呢?他有可能想着:如果加锁失败,我就直接放弃。
是啊,毕竟尝试加锁的目的可能完全相反:
- 在保证线程安全的前提下,尽量让所有线程都执行成功
- 在保证线程安全的前提下,只让一个线程执行成功
前者适用于秒杀、下单等操作,希望尽最大努力达成;后者适用于定时任务,只要让一个节点去执行,没有获取锁的节点应该fast-fail(快速失败)。
也就是说,节点获锁失败后,理论上可以有各种各样的处理方式:
- 阻塞等待
- 直接放弃
- 试N次再放弃
- ...
但lock、lock(leaseTime, timeUnit)替我们写死了:阻塞等待。即使lock(leaseTime, unit),其实也是阻塞等待,只不过不会像lock()一样不断续期。
究其原因,主要是lock()这些方法对于加锁失败的判断是在内部写死的:

而tryLock()方法则去掉了这层中间判断,把结果直接呈递到调用者面前,让调用者自己决定加锁失败后如何处理:

tryLock()直接返回true(加锁成功)和false(加锁失败),后续如何处理,全凭各个节点自己做出决定。
@Test
public void testTryLock() {
RLock lock = redissonClient.getLock("bravo1988_distributed_lock");
boolean b = lock.tryLock();
if (b) {
// 业务操作...
}
// 调用立即结束,不阻塞
}这样讲可能有点抽象,大家可以分别点进lock()和tryLock(),自行体会。总之,tryLock()中间少了一大块逻辑,因为它不插手结果的判断。

另外,tryLock()在加锁成功的情况下,其实和lock()是一样的,也会触发锁续期:

如果你不希望触发锁续期,可以像lock(leaseTime, unit)一样指定过期时间,还可以指定加锁失败后等待多久:
@Test
public void testLockSuccess() throws InterruptedException {
RLock lock = redissonClient.getLock("bravo1988_distributed_lock");
// 基本等同于lock(),加锁成功也【会自动锁续期】,但获锁失败【立即返回false】,交给调用者判断是否阻塞或放弃
lock.tryLock();
// 加锁成功仍然【会自动锁续期】,但获锁失败【会等待10秒】,看看这10秒内当前锁是否释放,如果是否则尝试加锁
lock.tryLock(10, TimeUnit.SECONDS);
// 加锁成功【不会锁续期】,加锁失败【会等待10秒】,看看这10秒内当前锁是否释放,如果是否则尝试加锁
lock.tryLock(10, 30, TimeUnit.SECONDS);
}注意哈,只传两个参数时,那个time其实是传给waitTime的:

我们之前操作的都是leaseTime,此时还是-1,也就是说如果加锁成功,还是会锁续期。

那waitTime是用来控制什么的呢?

简而言之:
- tryLock()加锁失败会立即返回false,而加了waitTime可以手动指定阻塞等待的时间(等一等,万一行呢)
- leaseTime的作用没变,控制的是加锁成功后要不要续期


至此,分布式锁章节暂时告一段段落。大家有兴趣的话,可以把上一篇花里胡哨的定时任务用Redisson改写,去掉Redis Message Queue(但定时任务最好还是用xxl-job等)。
Redisson分布式锁的缺陷
在哨兵模式或者主从模式下,如果master实例宕机,可能导致多个节点同时完成加锁。
以主从模式为例,由于所有的写操作都是先在master上进行,然后再同步给各个slave节点,所以master与各个slave节点之间的数据具有一定的延迟性。对于Redisson分布式锁而言,比如客户端刚对master写入Redisson锁,然后master异步复制给各个slave节点,但这个过程中master节点宕机了,其中一个slave节点经过选举变成了master节点,好巧不巧,这个slave还没同步到Reddison锁,所以其他客户端可能再次加锁。
具体情况,大家可以百度看看,解决方案也比较多。
还是那句话,但凡涉及到分布式,都没那么简单。有时引入一个解决方案后,我们不得不面对另一个问题。
作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
进群,大家一起学习,一起进步,一起对抗互联网寒冬
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!