AIGC专题报告:ChatGPT的工作原理
今天分享的AIGC系列深度研究报告:《AIGC专题报告:ChatGPT的工作原理》。
(报告出品方:省时查)
报告共计:107页
前言
ChatGPT 能够自动生成一些读起来表面上甚至像人写的文字的东西,这非常了不起,而且出乎意料。但它是如何做到的? 为什么它能发挥作用? 我在这里的目的是大致介绍一下 ChatGPT 内部的情况,然后探讨一下为什么它能很好地生成我们认为是有意义的文本。
我首先要说明一下,我将把重点放在正在发生的事情的大的方向上,虽然我会提到一些工程细节,但我不会深入研究它们。 (我所说的实质内容也同样适用于目前其他的“大型语言模型”LLM 和 ChatGPT)。
首先要解释的是,ChatGPT 从根本上说总是试图对它目前得到的任何文本进行“合理的延续”,这里的“合理”是指“在看到人们在数十亿个网页上所写的东西之后,人们可能会期望某人写出什么”。
因此,假设我们已经得到了“人工智能最好的是它能去做的文本......”(“The best thing about AI is its ability to”) 。想象一下,扫描数十亿页的人类书写的文本 (例如在网络上和数字化书籍中) ,并找到这个文本的所有实例 一- 然后看到什么词在接下来的时间里出现了多少。
ChatGPT 有效地做了类似的事情,除了 (正如我将解释的) 它不看字面文本;它寻找在某种意义上“意义匹配”的东西。但最终的结果是,它产生了一个可能出现在后面的词的排序列表,以及“概率”。
值得注意的是,当 ChatGPT 做一些事情,比如写一篇文章时,它所做的基本上只是反复询问“鉴于到目前为止的文本,下一个词应该是什么?, 而且每次都增加一个词。 (更准确地说,正如我将解释的那样,它在添加一个“标记”,这可能只是一个词的一部分,这就是为什么它有时可以“编造新词”)。
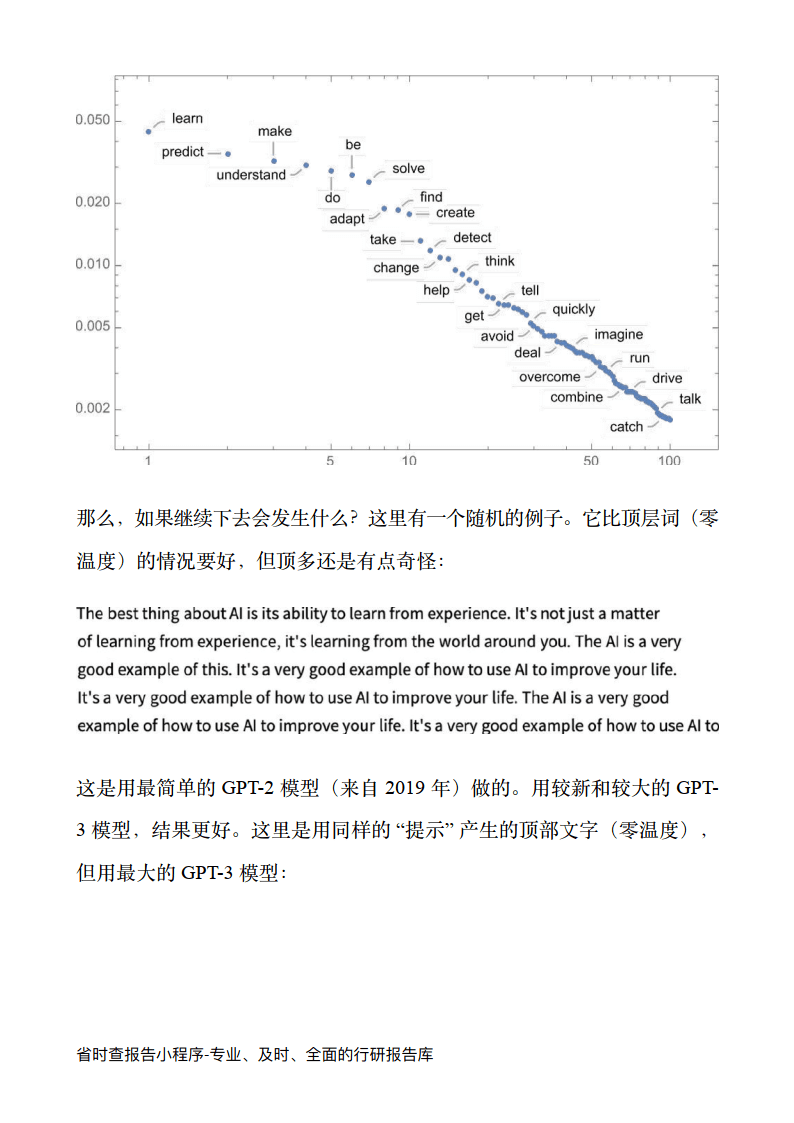
在每一步,它得到一个带有概率的单词列表。但是,它究竟应该选择哪一个来添加到它正在写的文章 (或其他什么) 中呢? 人们可能认为它应该是排名最高”的词 (即被分配到最高“概率”的那个)。
但是,这时就会有一点巫术开始悄悄出现。因为出于某种原因 -- 也许有一天我们会有一个科学式的理解 - 如果我们总是挑选排名最高的词,我们通常会得到一篇非常“平淡”的文章,似乎从来没有“显示出任何创造力”(甚至有时一字不差地重复) 。但是,如果有时 (随机的) 我们挑选排名较低的词,我们会得到一篇“更有趣”的文章。
这里有随机性的事实意味着,假如我们多次使用同一个提示,我们也很可能每次都得到不同的文章。而且,为了与巫术的想法保持一致,有一个特定的所谓“温度”参数 (temperature parameter) ,它决定了以什么样的频率使用排名较低的词,而对于论文的生成,事实证明,0.8 的“温度”似乎是最好的。 (值得强调的是,这里没有使用任何 “理论”; 这只是一个在实践中被发现可行的问题) 。例如,“温度” 的概念之所以存在,是因为恰好使用了统计物理学中熟悉的指数分布,但没有“物理”联系- 至少到目前为止我们如此认为。)
在我们继续之前,我应该解释一下,为了论述的目的,我大多不会使用ChatGPT 中的完整系统;相反,我通常会使用更简单的 GPT-2 系统,它有一个很好的特点,即它足够小,可以在标准的台式电脑上运行。
因此,对于我展示的所有内容,包括明确的沃尔弗拉姆语言 (WolframLanguage) 代码,你可以立即在你的计算机上运行。






概率从何而来?
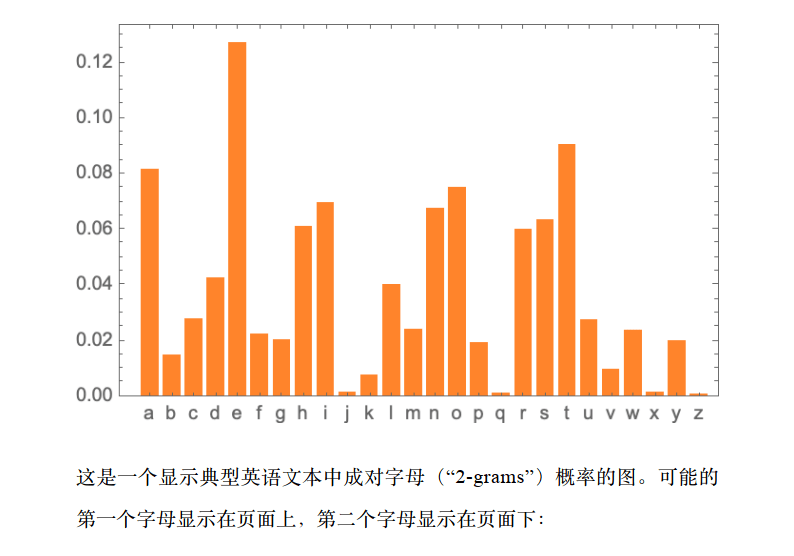
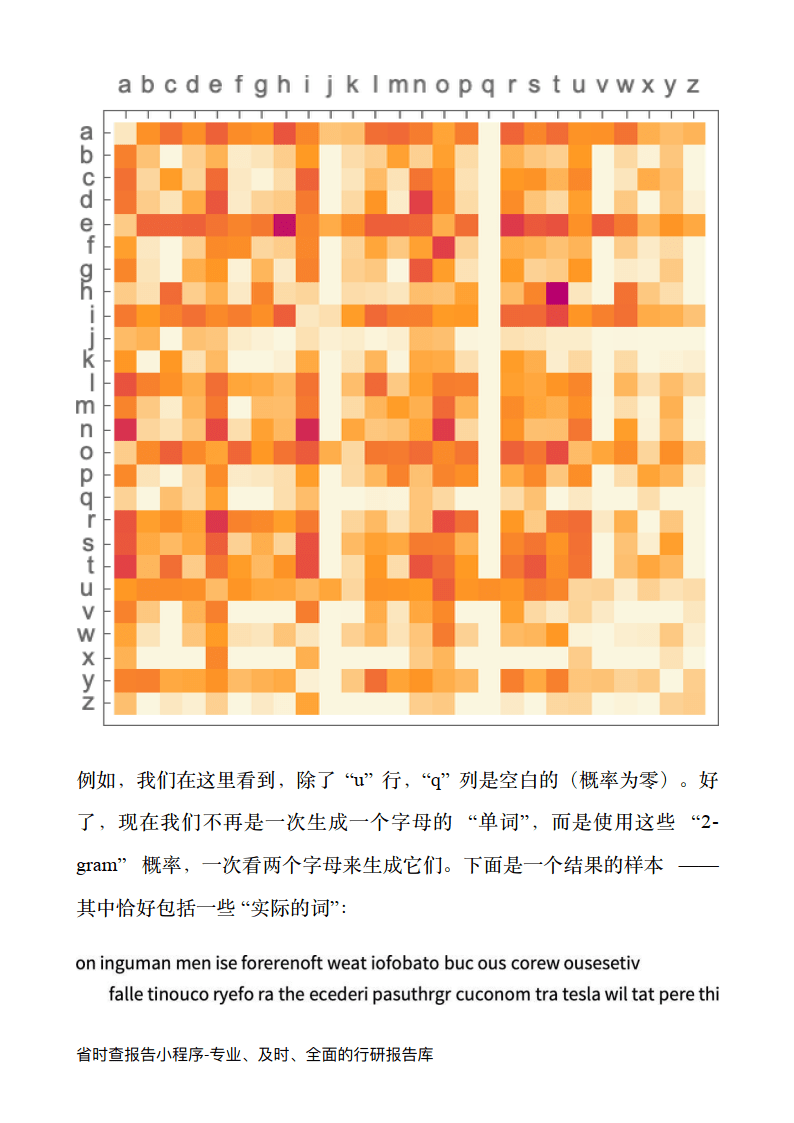
好吧,ChatGPT 总是根据概率来选择下一个词。但是这些概率从何而来?让我们从一个更简单的问题开始。让我们考虑一次生成一个字母 (而不是单词) 的英语文本。我们怎样才能算出每个字母的概率呢?
在网络的抓取中,可能有几千亿个单词;在已经数字化的书籍中,可能有另外几千亿个单词。但是有了 4 万个常用词,即使是可能的 2grams 的数量也已经是 16 亿了,可能的 3-grams 的数量是 60 万亿。
所以我们没有办法从现有的文本中估计出所有这些的概率。而当我们达到20 个字的“文章片段”时,可能性的数量比宇宙中的粒子数量还要多,所以从某种意义上说,它们永远不可能全部被写下来。
那么我们能做什么呢? 最大的想法是建立一个模型,让我们估计序列出现的概率-即使我们在所看的文本语料库中从未明确见过这些序列。而ChatGPT 的核心正是一个所谓的“大型语言模型”(LLM) ,它的建立可以很好地估计这些概率。





什么是模型?
假设你想知道(就像伽利略在 15 世纪末所做的那样) ,从比萨塔的每一层落下的炮弹要多长时间才能落地。那么,你可以在每一种情况下测量它并将结果制成表格。或者你可以做理论科学的精髓: 建立一个模型,给出某种计算答案的程序,而不是仅仅测量和记住每个案例。
让我们想象一下,我们有 (有点理想化的) 数据,说明炮弹从不同楼层落下需要多长时间。
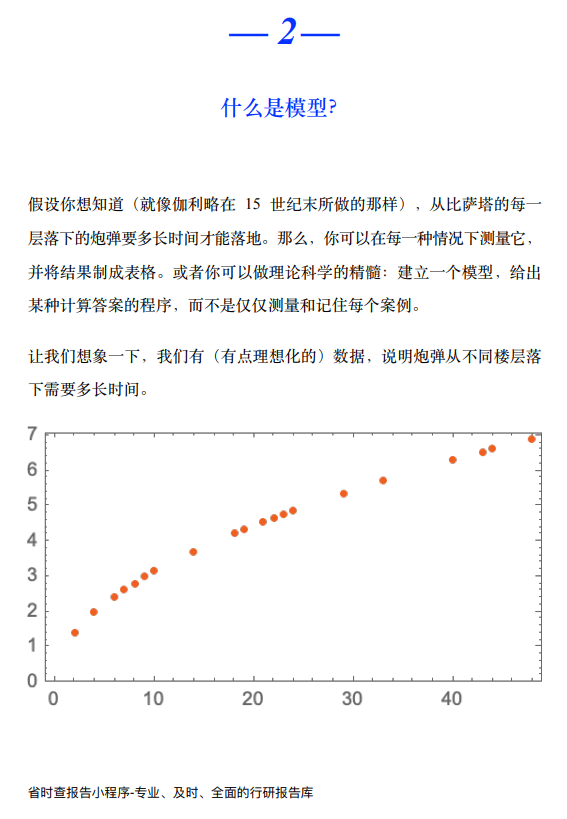
我们如何计算出它从一个我们没有明确数据的楼层落下需要多长时间? 在这种特殊情况下,我们可以用已知的物理学定律来计算。但是,如果说我们所得到的只是数据,而我们不知道有什么基本定律在支配它。那么我们可以做一个数学上的猜测,比如说,也许我们应该用一条直线作为模型。

我们可以选择不同的直线。但这是平均来说最接近我们所给的数据的一条而根据这条直线,我们可以估算出任何楼层的下降时间。
我们怎么知道要在这里尝试使用一条直线呢? 在某种程度上我们不知道这只是数学上简单的东西,而我们已经习惯了这样的事实: 我们测量的很多数据都被数学上简单的东西很好地拟合了。我们可以尝试一些数学上更复杂的东西 -- 比如说 a + bx + cx2,然后在这种情况下,我们做得更好:

不过,事情可能会出大问题。比如这里是我们用 a + b/c + x sin(x) 最多也就做成:
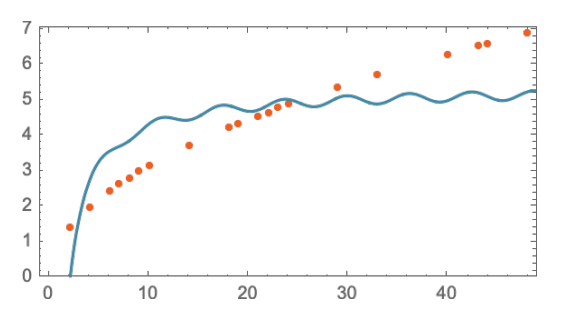
值得理解的是,从来没有一个“无模型的模型”。你使用的任何模型都有些特定的基础结构,然后有一组 “你可以转动的旋钮”(即你可以设置的参数)来适应你的数据。而在 ChatGPT 的案例中,使用了很多这样的“旋钮”-实际上,有 1750 亿个。
但令人瞩目的是,ChatGPT 的底层结构——“仅仅”有这么多的参数足以使一个计算下一个单词概率的模型“足够好”,从而为我们提供合理的文章长度的文本。
类人的任务模型
我们上面举的例子涉及到为数字数据建立模型,这些数据基本上来自于简单的物理学几个世纪以来我们都知道 “简单数学适用”。但是对于ChatGPT 来说,我们必须为人类语言文本建立一个模型,即由人脑产生的那种模型。而对于这样的东西,我们 (至少现在) 还没有类似“简单数学”的东西。那么,它的模型可能是什么样的呢?
当我们为上面的数字数据建立一个模型时,我们能够取一个给定的数字值然后为特定的 a和 b 计算 a + bx。
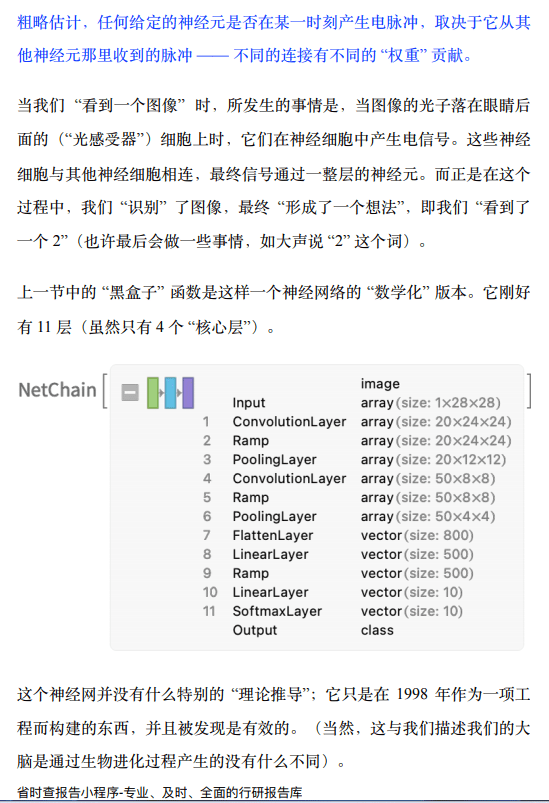
因此,如果我们把这里的每个像素的灰度值当作某个变量 xi,是否有一些所有这些变量的函数,在评估时告诉我们这个图像是什么数字? 事实证明有可能构建这样一个函数。不足为奇的是,这并不特别简单。一个典型的例子可能涉及 50 万次数学运算。


神经网路
好吧,那么我们用于图像识别等任务的典型模型究竟是如何工作的呢? 目前最流行、最成功的方法是使用神经网络。在 20 世纪 40 年代,神经网络的发明形式与今天的使用非常接近,它可以被认为是大脑似乎工作方式的简单理想化。
在人类的大脑中,有大约 1000 亿个神经元 (神经细胞) ,每个神经元都能产生电脉冲,每秒可能有一千次。这些神经元在一个复杂的网络中连接起来,每个神经元都有树状的分支,允许它将电信号传递给可能有成千上万的其他神经元。

机器学习和神经网络的训练
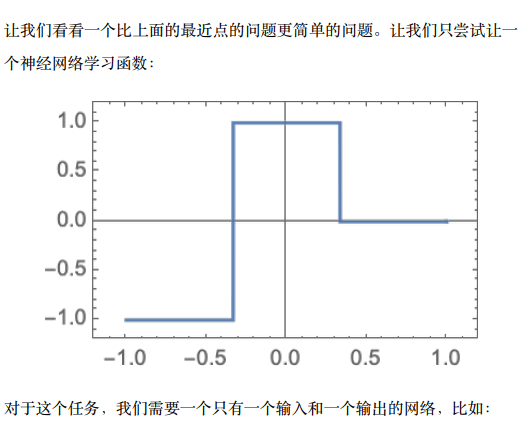
到目前为止,我们一直在谈论那些“已经知道”如何完成特定任务的神经网络。但是,神经网络之所以如此有用(估计也是在大脑中) ,是因为它们不仅在原则上可以完成各种任务,而且可以逐步“根据实例训练”来完成这些任务。
当我们制作一个区分猫和狗的神经网络时,我们实际上不需要写一个程序来 (比如说) 明确地找到胡须;相反,我们只需要展示大量关于什么是猫和什么是狗的例子,然后让网络从这些例子中“机器学习”如何去区分它们。
重点是,训练有素的网络从它所展示的特定例子中“概括”出来。正如我们在上面看到的,这并不是简单地让网络识别它所看到的猫咪图像的特定像素模式;而是让神经网络以某种方式设法在我们认为是某种“一般猫性”的基础上区分图像
那么,神经网络的训练究竟是如何进行的呢? 从本质上讲,我们一直在努力寻找能够使神经网络成功重现我们所给的例子的权重。然后,我们依靠神经网络以“合理”的方式在这些例子之间进行“插值”(或“概括”)。

嵌入的概念
神经网络- 至少在它们目前的设置中一- 从根本上说是基于数字的。因此,如果我们要用它们来处理像文本这样的东西,我们就需要一种方法来用数字表示我们的文本。
当然,我们可以开始 (基本上就像 ChatGPT 那样)为字典中的每个词分配一个数字。但是,有一个重要的想法——例如,它是 ChatGPT 的核心超出了这个范围。这就是“嵌入”的概念。我们可以把嵌入看作是一种尝试用数字阵列来表示事物“本质”的方式 - 其特性是“附近的事物由附近的数字来表示。

报告共计:107页
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 1944. 队列中可以看到的人数
- 【万字解析】Webpack 优化构建性能(分析->优化)
- C/C++学习笔记十三 C++中的重载运算符
- 开源项目go-admin的代码生成功能使用
- CUDA笔记2
- Github 2023-12-30 开源项目日报 Top10
- 1042: 数列求和3 和 1057: 素数判定 和 1063: 最大公约与最小公倍
- python使用requests+excel进行接口自动化测试
- 深入了解 npm 命令
- 鸿蒙开发之增大点击响应热区responseRegion