什么是缓存击穿、缓存穿透、缓存雪崩?
发布时间:2024年01月04日
在redis中,我们在使用缓存时一般都是:读请求来了,先查下缓存,缓存有值命中,就直接返回;缓存没命中,就去查数据库,然后把数据库的值更新到缓存,再返回。
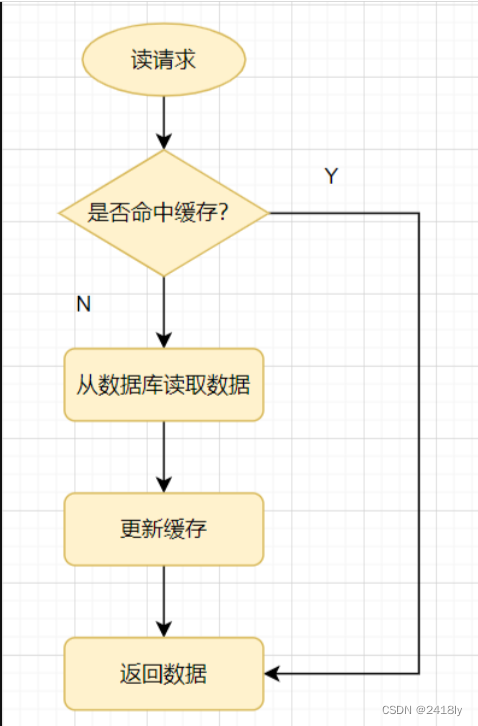
但我们如果有一个一定不会存在的数据呢?那它就会每次调用数据库读取数据,每次都失败,这样就会降低我们的性能,这就是缓存穿透
缓存穿透一般都是这几种情况产生的:
- 业务不合理的设计,比如大多数用户都没开守护,但是你的每个请求都去缓存,查询某个userid查询有没有守护。
- 业务/运维/开发失误的操作,比如缓存和数据库的数据都被误删除了。
- 黑客非法请求攻击,比如黑客故意捏造大量非法请求,以读取不存在的业务数据。
如何避免缓存穿透呢? 一般有三种方法。
1.如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。
2.如果查询数据库为空,我们可以给缓存设置个空值,或者默认值。但是如有有写请求进来的话,需要更新缓存,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。
3.使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据库压力过大甚至宕机就是缓存雪崩
- 一般是由于大量数据同时过期造成的,所以我们可均匀设置过期时间,让过期时间相对分散一些。
热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db就是缓存击穿
缓存击穿和缓存雪崩看着有点像,区别是,缓存雪崩是指数据库压力过大甚至宕机,缓存击穿只是大量并发请求到了DB数据库层面。
文章来源:https://blog.csdn.net/m0_64792179/article/details/135365060
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!