多尺度的学习
发布时间:2024年01月18日
文章目录
参考链接
在目标检测任务中,被测目标的大小经常是不固定的。在被测物体尺度相差极大时,模型通常难以对极大和极小的物体同时进行检测。
首先,要知道为什么被测物体尺度相差过大会造成模型精度降低。物体检测领域中各个模型的骨干网络,无外乎不是使用多层卷积逐步提取图像深层信息,生成多层特征图,并基于深层特征图做定位、分类等进一步处理。
在这“由浅至深”的特征提取过程中,浅层特征具有较高的分辨率,可以携带丰富的几何细节信息,但感受野很小且缺乏语义信息,与之相反的是,深层特征具备较大的感受野以及丰富的语义信息,但分辨率不高,难以携带几何细节信息。此时假设我们将模型继续加深,超深层特征中将具有极大的感受野,被测物体的语义信息也会因被周遭环境信息所稀释而降低。
如果训练数据中同时包含尺度极大和极小的被测物体,那么会发生什么呢?
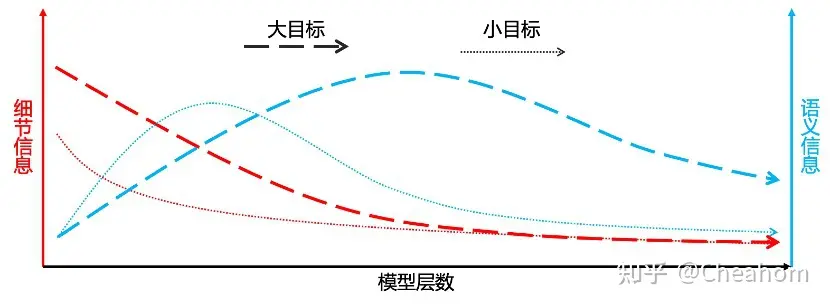
如上图所示,假设模型一共有100层,大小目标的细节信息都随着模型层数的加深而衰退。对于语义信息而言,由于小目标尺度小,随着模型层数的增多(下采样次数的增多),语义信息可能在25层即提取完毕,之后随着层数的继续增加,小目标的语义信息也会快速被环境信息所稀释;而大目标尺度大,可能要在50层才能提取到足够的语义信息,但此时小目标的语义信息已经丢失的差不多了。
那么这个网络的深度应定为25层,还是50层,亦或是37层呢?定25层则对小目标的检测效果好而大目标检测能力差;定50层则反之;定37层则两类目标的检测能力较为均衡但都不在最好的检测状态。而这就是多尺度”目标检测问题的根源所在。
os:根据具体任务和数据集的需求,需要综合考虑小目标和大目标的重要性以及数据集中目标的尺度范围,来选择合适的网络深度,或者说是从哪一层去提取到小尺度、大尺度的目标。
- 语义信息:图像中物体、场景或概念的语义表示,应该就是
类别 - 几何细节信息:图像中的边缘、角点、纹理或深度信息,应该就是
位置、目标大小
文章来源:https://blog.csdn.net/LWD19981223/article/details/135650603
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于java,springboot的学生成绩管理系统的设计与实现
- 什么叫反范式?数据库反范式设计
- 使用Java语言解决古典猴子分桃问题
- ATFX汇市:加拿大央行利率决议来袭,按兵不动概率较高
- STM32 USB DFU固件升级的设计与实现
- idea全局搜索时过滤掉不想要的文件
- 蓝桥杯一维差分 | 算法基础
- MoveCTF 2024参与指南
- 【My Rust Crate】obtaining Linux system device information
- MySQL夯实之路-事务详解