BPF 程序与信号交互大揭秘
本文地址 :?BPF 程序与信号交互大揭秘 | 深入浅出 eBPF
原文:Signaling from within: how eBPF interacts with signals
- 1. 背景
- 2. 动机
- 3. 场景:拦截 openat(2)
- 4. 内核如何处理 SIGKILL 信号?
- 5. 什么信号要后置处理
- 6. 通过 BPF程序触发 SIGKILL
- 7. 自愿信号检查
- 8. open & write 操作竞争(Racing)
- 9. 其他影响
- 10. 结论
本文探讨了 eBPF 程序生成的 UNIX 信号的一些语义。
1. 背景
信号自 1971 年 UNIX 第一版问世以来就一直存在,虽然其语义和系统调用在这些年间经历了改变,但其用途和应用基本保持不变。通常情况下谈论信号语义时,我们所讨论的是用户空间可以观察和与之交互的内容。毕竟,我们主要生成和处理与用户空间进程有关的信号。
在本文中,我们将探讨在 eBPF 程序内部触发信号的语义。此外,我们还将确定和观察在处理这些信号背后我的影响。你可以在这里中找到关于 eBPF 的更多信息。
2. 动机
在容器防御中,我们利用 eBPF 在 Linux 安全模块 (LSM) 在钩子函数中限制对系统资源的访问。使用 LSM 是进行资源限制访问的首选:eBPF 程序可返回类似?EPERM(尝试进行了操作,但没有足够的权限)?的错误,并会传播到系统调用的返回值。
但使用 eBPF+LSM 方式的问题是对内核要求比较新,而且大部分场景仅适用于 AMD64。 因此,我们希望在较旧的内核或其他非 AMD64 内核架构上使用 eBPF 辅助函数?bpf_send_signal()?实现类似同样的目的。 取代返回 EPERM 失败,我们使用?bpf_send_signal()?函数向当前进程发送 SIGKILL 信号并终止进程,这可以说更激进,但考虑到上述限制仍然是个可取的方式。
一般来说,我们的目标是回答以下问题:
- 程序收到?
SIGKILL?后会观察到哪些负面影响(如果有) - 负面影响(如果有)是由信号子系统设计与实现引起的
- 如果将来内核代码发生变化,负面影响会是怎么样
3. 场景:拦截 openat(2)
想象一下,如果我们希望阻止某些进程打开文件,简单起见则可以阻止进程调用打开文件的?openat(2)?系统调用。
如 LSM BPF 适用,我们可在 LSM?security_file_open()?钩子函数中加载 eBPF 程序, 并返回 EPERM,从而达到阻止?openat(2)?调用的结果。 在 LSM BPF 方式不可用时,我们可以选择使用?SIGKILL?终止进程,但首先我们需要找到一个在内核中可挂载 eBPF 程序的位置。
我们可以选择像?syscalls:sys_enter_openat2?这样的跟踪点,或使用?kprobes?在选择的内核函数运行时执行对应的 eBPF 程序。针对后者可选择的内核函数有?vfs_open,?do_sys_openat2( 稍早发生 ),或者?__x64_sys_openat( 更早,但与机器架构有关 )。为了验证,我们可使用?bpftrace?进行测试验证 :
在测试前 /tmp/__noopen 文件已经存在
|
我们可以看到?cat(1)?在尝试打开文件时被?SIGKILL?终止。乍看之下,这似乎是正确的,但当前直接给出结论还为时过早。
需重点注意的是,这里的信号不是由外部进程出发,而是来自执行系统调用的?cat(1)?进程本身。在内核中执行了?kill(0, SIGKILL)?的等效操作,其中 0 表示进程本身。
通过测试,我们的确证明的是程序确实被终止了,但这也带来了一些疑问:
- 我们是否阻止了?
openat(2)函数调用? - 如果我们成功阻止了?
openat(2),结果会不会发生了变化吗? - 是否存在更多可观察的其他影响?
同一路径上进行同样的实验,但这次我们使用一个不存在的文件,这将会让?openat(2)?添加?O_CREAT?标志,那么文件是否会被创建出来?应用程序是否仍然会被终止吗?让我们用测试结果来回答:
|
在这种情况下,我们执行的进程正常被?SIGKILL?终止了。但我们检查文件系统时,却发现有一个空文件被创建了出来,测试结果结果表明?openat(2)?的确被执行了。那么为什么会发生这种情况呢? 这个原因我们得从 SIGKILL 信号的处理流程上寻找答案。
4. 内核如何处理 SIGKILL 信号?
在内核中信号并不会直接被处理,相反,信号必须在某个安全点后被处理。所谓不能直接处理是指:如进程进行一个系统调用时收到了SIGKILL 信号,进程并不能直接被杀掉。信号必须在安全点被检查,而在大多数 UNIX 系统中,在系统调用返回到用户空间之前进行信号量触发检查。
在系统调用函数之后执行的函数?exit_to_user_mode_loop()?,会检查当前任务?thread_info?结构中检查是否设置了标志位?TIG_SIGPENDING,如该标记被设置,进程将进入信号处理代码逻辑。如果?SIGKILL(致命信号)处于 pending 状态,进程将进入?do_group_exit()?后续调用不再返回,进程终止。
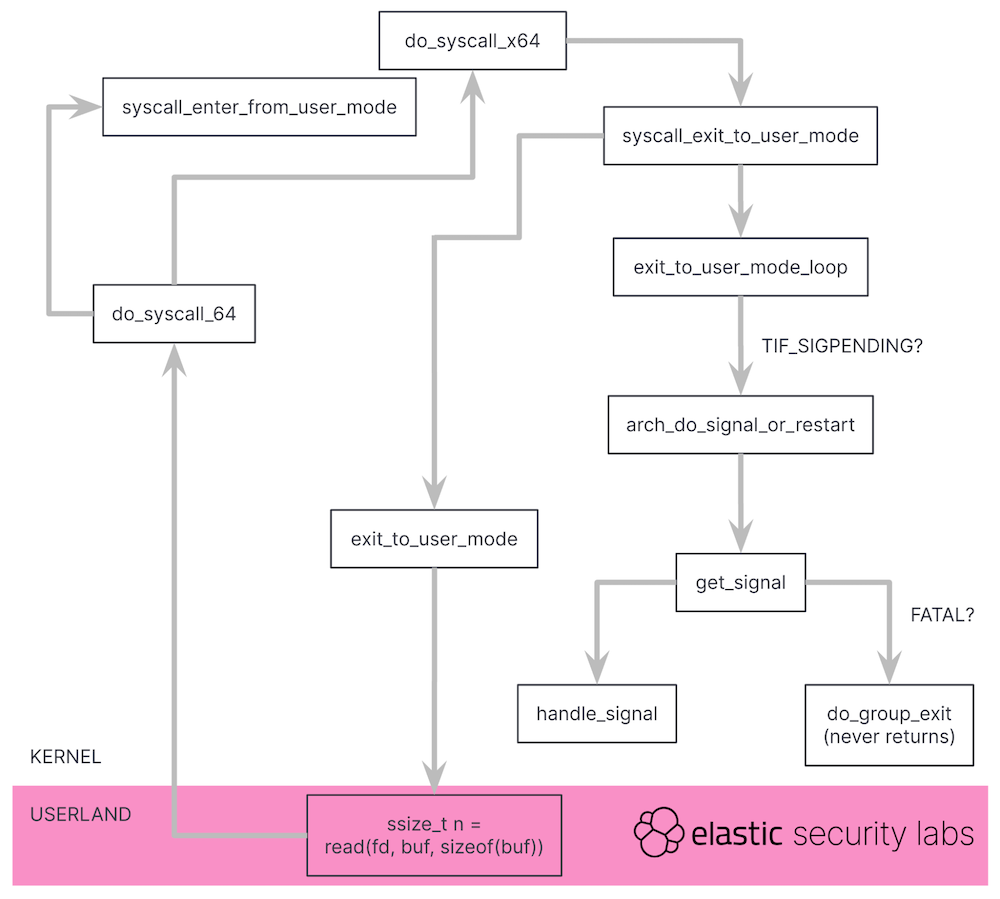
5. 什么信号要后置处理
信号在后置的安全点位置被处理是设计所需,否则内核将不得不考虑由于致命信号而导致进程退出的各种场景。这里我们尝试假设如果信号到达时会发生什么,可通过中断运行进程并强制其从中断上下文退出来实现,处理流程如下所示:
cpu0?上运行的进程 A 执行一个系统调用cpu1?上运行的进程 B 向进程 A 发送?SIGKILL- 从?
cpu1?发送一个 IPI 到?cpu0 cpu0?陷入中断帧,由于接收到进程 A 的致命信号,退出当前进程

但事实上执行并非如此,我们无法从中断上下文中退出 - 在不对资源管理进行重大修改的情况,也无法实现从中断下文退出进程。这是因为当一个进程退出时,内核必须保障进程持有的资源必须被释放 - 如锁、引用计数或任何其他可能影响的可变数据。
我们可以将其与内核抢占做个类比,当 Linux 配置?CONFIG_PREEMPT_FULL?开启抢占式时,这将允许调度器在运行进程位于内核空间时将其挂起而执行其他进程。从被抢占的进程的角度来看,这是一种非自愿的上下文切换,因为其并未自愿释放 CPU。这与抢占式用户空间是正交的,在抢占式用户空间中,调度器抢占运行在用户模式的进程。在历史上,UNIX 系统并未设计为抢占式内核,保持维持低延迟的策略仅依赖于快速的系统调用和中断优先级。
使用抢占式编程更加困难,内核程序员必须时刻考虑被抢占的影响,并判断何时禁用抢占。例如,在自旋锁上没有在正确的时机禁用抢占可能导致另一个进程无限期地在抢占的进程的锁上自旋。
如果我们允许进程从一个陷阱帧中被迫退出,这有点类似于抢占,但要困难得多 —— 甚至来讲不可能实现。内核程序员现在必须时刻考虑 “如果我的进程在这里被迫退出会发生什么?",而这可能涉及注册回调以在退出时释放资源。
经过上述分析可得知,很明显信号不能直接被处理。Linux 系统中的信号,需要在返回用户空间之前被处理。
6. 通过 BPF程序触发 SIGKILL
这里,我们尝试跟踪由 eBPF 程序发起的?SIGKILL?的生命周期,包括进程被终止。当一个 eBPF 程序调用特殊辅助函数?bpf_send_signal(SIGKILL)?时,会进入?bpf_send_signal_common(SIGKILL, PIDTYPE_TGID)。PIDTYPE_TGID?是 “ 任务组 ID”,指定当前进程的任何任务(即任何线程)都可以接受信号。但 eBPF 还提供了?bpf_send_signal_thread(),可以通过指定?PIDTYPE_PID?只将信号发送给当前任务。
bpf_send_signal_common()?必须谨慎使用,因为它必须能够从内核中的任何可以附加 eBPF 程序中生成信号;这是一项棘手的工作,曾经在过去导致了一些错误,比如这里的死锁:这是 eBPF 实现时候的要求;在此之前,从内核生成的信号是在受控点完成的。
信号传递的主要工作是在?__send_signal_locked()?和?complete_signal()?中完成的:
complete_signal() ^
__send_signal_locked() |
send_signal_locked() |
do_send_sig_info() |
group_send_sig_info() |
bpf_send_signal() |
在我们的情况下,在?__send_signal_locked?中:sig?是?SIGKILL,info?是?SEND_SIG_PRIV,t?是当前任务(正在运行的线程),type?是?PIDTYPE_TGID,force?为 true,当?info?为?SEND_SIG_PRIV?时总是设置为 true,这意味着这是一个源自内核而非用户程序的信号。
|
__send_signal_locked()?将在当前任务的结构中注册?SIGKILL?为待处理信号(我们的?t),这是一个进程范围的结构,由该进程中的所有任务(pthread)共享(因为我们使用了?PIDTYPE_TGID),然后控制权转交给?complete_signal()。
SIGKILL?在?complete_signal()?中有点特殊,因为它是一个致命信号,进程的共享结构中设置的待处理信号位会被复制到每个任务的待处理集合中。这意味着?SIGKILL?对当前进程的每个 pthread 都被标记为待处理。
然后,complete_signal()?通过?signal_wake_up + signal_wake_up_state()?唤醒所有线程,以便它们可以被终止。每个线程必须自行终止并发送一个信号,用户通知线程 “下次请退出而不是返回用户态”。
在?signal_wake_up()?调用栈中,一个?TIG_SIGPENDING?标志将被设置,警告任务检查其待处理信号。可能是线程在我们尝试唤醒它时处于用户态,甚至更糟糕的是可能无限循环。在这种情况下,它不会进入内核,直到调度程序决定抢占它或者中断触发。通过强制线程通过?kick_process()?进入内核,发送?IPI?到远程 CPU 来防止这种情况发生,强迫它陷入内核,然后尝试返回到用户态,检查?TIG_SIGPENDING,找到?SIGKILL?并终止。
7. 自愿信号检查
虽然系统中信号只有在返回用户空间时才会被处理,但检查信号是否设置可以在任何地方进行。tmpfs、ext4、xfs 和许多其他文件系统在开始写操作之前会检查是否有致命信号设置。如果有致命信号设置,它们会向调用方返回错误,将系统调用栈展开直到返回用户空间的那一点,然后程序会像我们之前看到的那样终止。可以在此处看到对 tmpfs 和 ext4 写操作的自愿检查。
现在我们可以推断,在 tmpfs 中如果安装一个在内核入口早期生成?SIGKILL?的 eBPF 程序会发生什么:写操作将不会被执行,因为信号会被注意到,操作会被中止。
然而,Btrfs 的行为与其他文件系统不同。在发出写入或进一步读取 IO 栈之前,它不会检查信号。当收到?SIGKILL?时,它会完成 IO 操作然后终止。
如果我们试图通过从 eBPF 程序中生成?SIGKILL?来阻止 Btrfs 进行写入,当程序进入写系统调用时,这是行不通的。假设这是我们想要做的,考虑在?openat(2)?上更早地生成?SIGKILL?可能是更合理的:这样我们可以在程序有机会发出写操作之前就更早地终止程序。然而,不幸的是,正如后面的部分所示,这也是不可靠的。
8. open & write 操作竞争(Racing)
如果我们在?openat(2)?中生成了?SIGKILL,至少在 Btrfs 中,仍然可以对即将返回的文件描述符进行写操作。下面的?bpftrace?命令将在?vfs_open()?装置了一个 eBPF 程序,用于生成?SIGKILL?信号,并终止任何试图打开名为?__nowrite?的文件的进程。
|
仍然有可能让内核发生竞争,并写入将要返回的文件描述符,这意味着即使我们可以终止进程,却也不能依靠这种机制来完全防止文件被修改。
现在应该很明显open?操作已经触发,就像本文开头讨论的那样。使用?O_CREAT?标志创建文件,然后可以观察到在打开操作和进程终止之间发生的影响。重要的观测效果是,进程文件表在终止之前会被填充。
进程文件表是一个每个进程的内核表,将文件描述符号映射到文件对象。例如,文件描述符 1 引用代表标准输出的文件对象,因此,如果用户程序调用?write(1, "foo", strlen("foo")),内核将查找由文件描述符 1 引用的对象,并对其调用?vfs_write()。文件结构具有回调函数,知道如何将内容写入标准输出,我们将其称为文件描述符的支持。
常见的想法是打开操作返回的文件描述符号,并在进程终止之前但打开操作生效后尝试写入。
第一个诀窍是弄清楚文件描述符号值,这可通过以下方法完成:
|
通过?dup(2)、open(2)、accept(2)、socket(2)?或其他任何系统调用创建文件描述符号的时,会保证使用最低可用的编号。如果我们?dup?任何文件描述符并关闭它,下一个系统调用创建的文件描述符可能会使用我们之前从?dup(2)?得到的相同索引。对于多线程程序并不一定如此,因为可能有其他线程创建文件描述符使得猜测失败。正是因为这些竞争,才出现?dup2(2)?函数,其以允许多线程程序拥有无竞争的?dup。 多线程是 UNIX 系统后来添加的,因此必须保留文件描述符编号的旧语义。
猜测在我们拥有受控环境的情况下并不是必要的。然而,它很有趣,因为可以作为尝试利用这个竞争条件的攻击的基本模块。
现在我们有了目标文件描述符,我们可以生成一堆工作线程来尝试向它写入!
|
这里的 writer-worker 的代码非常简单:
|
完整的程序可以在这里找到。在大多数情况下,我们无法触发竞争条件,程序会以?SIGKILL?终止。不过,通过在循环中运行程序足够多次,我们大约可以在一分钟内触发这个竞争条件。
|
值得指出的是,这种行为并非任何方式上的内核漏洞,而只会在 Btrfs 中出现。我们尝试在其他文件系统(如 ext4、tmpfs 和 xfs)中触发这种竞争条件均未成功,因为这些实现在进行写入操作之前明确检查是否存在致命信号。
9. 其他影响
我们已经讨论了?open?和?write,也检查了通过生成?SIGKILL?来阻止其他系统调用效果的行为。
下表中,BLOCKED?表示效果未发生,例如,unlink?没有删除文件。你可能猜到了,UNBLOCKED?表示效果确实发生了 ——?unlink?删除了文件。在这两种情况下,程序都会被?SIGKILL?杀掉,这表明信号生效。
| 6.5.5-200.fc38.x86_64 | Btrfs | tmpfs | Ext4 |
|---|---|---|---|
| chmod(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| link(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| mknod(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| write(2) | UNBLOCKED | BLOCKED | BLOCKED |
| race-open-write | UNBLOCKED | BLOCKED | BLOCKED |
| rename(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| truncate(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| unlink(2) | UNBLOCKED | UNBLOCKED | UNBLOCKED |
| 6.1.55-75.123.amzn2023.aarch64 | XFS |
|---|---|
| chmod(2) | UNBLOCKED |
| link(2) | UNBLOCKED |
| mknod(2) | UNBLOCKED |
| write(2) | BLOCKED |
| race-open-write | BLOCKED |
| rename(2) | UNBLOCKED |
| truncate(2) | UNBLOCKED |
| unlink(2) | UNBLOCKED |
| 指令 | 6.5.5-200.fc38.x86_64 | 6.1.55-75.123.amzn2023.aarch64 |
|---|---|---|
| write(2) on a pipe(2) | UNBLOCKED | UNBLOCKED |
| fork(2) | BLOCKED | BLOCKED |
对于所有等效的?at?系统调用,比如?openat(2),renameat(2),观察到相同的行为 …
10. 结论
我们演示了使用?SIGKILL?作为 eBPF 的安全机制时的一些陷阱,尽管大多数情况下可靠地使用,但我们的确需要对它们运行的环境有深刻的理解。本文的主要观点有:
- 从 eBPF 内部生成的信号是同步的,因为它是在同一个进程上下文中生成和产生的
- 信号是在系统调用发生后在内核中处理的
- 特定的系统调用和组合将避免在存在致命信号的情况下启动操作
- 即使我们在?
open(2)?从内核返回之前终止程序,我们不能可靠地阻止在 Btrfs 上进行?write(2)
尽管我们的研究很彻底,但这些是可能取决于外部因素的微妙语义。如果你认为我们遗漏了某些内容,请不要犹豫与我们联系。
本研究中使用的程序和脚本是公开的,可在ebpf-sig-exp 仓库中获取。如果你想深入了解内核,可移步查看这个深度分析有关调用堆栈的信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- c语言:求n门课程的平均分|练习题
- 数据结构栈、队列、链表、散列表
- 盘点一款强大的网络工具集:Netwox
- 2023/12/19 work
- 智能优化算法应用:基于材料生成算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- 操作系统详解(5.1)——信号(Signal)的相关题目
- 振动传感器:M-A342VD10 / M-A542VR10
- vue中高德地图使用
- IntelliJ IDEA - 快速去除 mapper.xml 告警线和背景
- Kubernetes Gateway API V1.0:您应该切换吗?