细数语音识别中的几个former
随着Transformer在人工智能领域掀起了一轮技术革命,越来越多的领域开始使用基于Transformer的网络结构。目前在语音识别领域中,Tranformer已经取代了传统ASR建模方式。近几年关于ASR的研究工作很多都是基于Transformer的改进,本文将介绍其中应用较为广泛的几个former架构。?
?
1. Conformer

💡?Motivation?&?Method
Transformer模型擅长获取基于内容的全局信息但是对高细粒度的局部特征效果不佳,而CNN擅长获取局部特征信息对于全局信息则需要更多的层。他们希望将CNN和Transformer优势结合起来对音频序列的局部和全局依赖关系进行建模。
🌌?Model architecture
Conformer也是编码器-解码器结构,其中encoder由两个类似夹心饼干的前馈层组成,多头自注意力模块和卷积模块夹在两个前馈神经网络中间,紧接着Layernorm层。在本篇论文中,仅使用1层LSTM作为decoder。

卷积模块(CNN)
conformer的卷积模块包含点向卷积,GLU激活层,1-D深度卷积,Batchnorm,然后是swish激活层,其结构如下所示:

前馈模块(FFM)
前馈模块,第一个线性层使用4的扩展因子,第二个线性层将其投影回模型维度。使用了swish激活和pre-norm残差单元。

📊?Experiment results
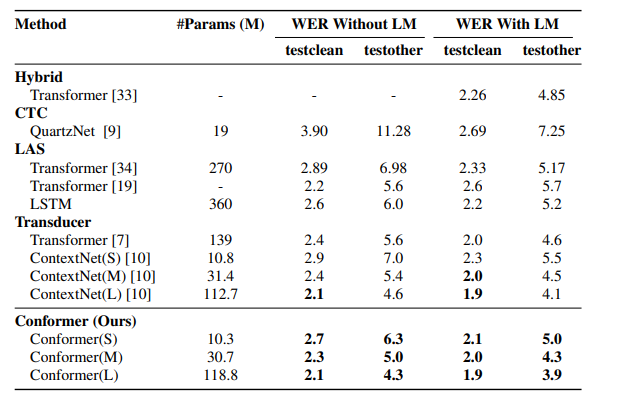
在参数量相当的情况下Confomer可以达到比ContextNet更低的WER。当Conformer参数量为30.7M时,其WER甚至优于参数量为139M的Transformer结构。
🧮?Ablation Studies
本文一系列的消融实验验证了如下的几个结构和参数的最优配置
-
马卡龙风格的FFN优于残差结构的FFN
-
深度卷积优于轻量卷积
-
多头注意力头heads数目为4最好
-
CNN卷积核大小32最佳
模型最终在LibriSpeech test clean/test other测试集上分别获得了1.9%和3.9%的WER。

2. Branchformer

💡?Motivation?&?Method
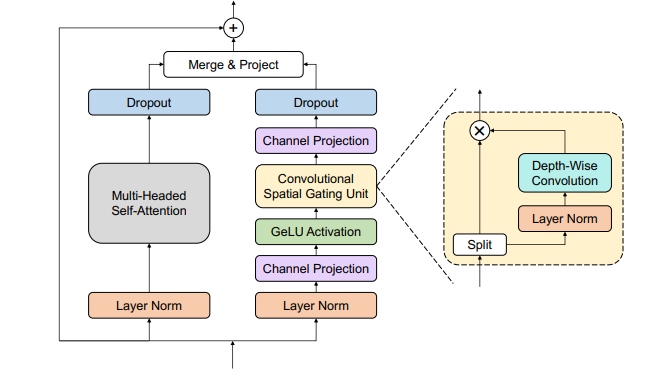
受Conformer启发,他们想提出了一种更灵活、可解释和可定制的encoder替代方案。Branchformer具有并行分支,可用于对端到端语音处理中的各种范围依赖关系进行建模。在每个encoder层中,一支使用self-attention来挖掘全局依赖关系,另一支使用带有卷积门控(cgMLP)的MLP模块来提取局部关系。
🌌?Model architecture
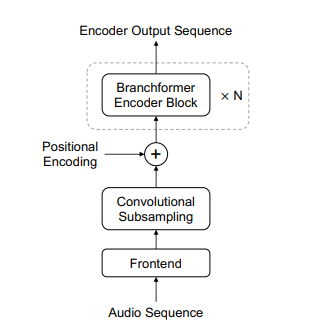
如下图所示,左边为encoder的总体结构。右边为Branchformer的结构。它由两个平行的分支组成。一个分支利用注意力捕获全局信息,而另一个分支利用带有卷积门控的MLP提取局部信息。
|
|
|
📊?Experiment?results

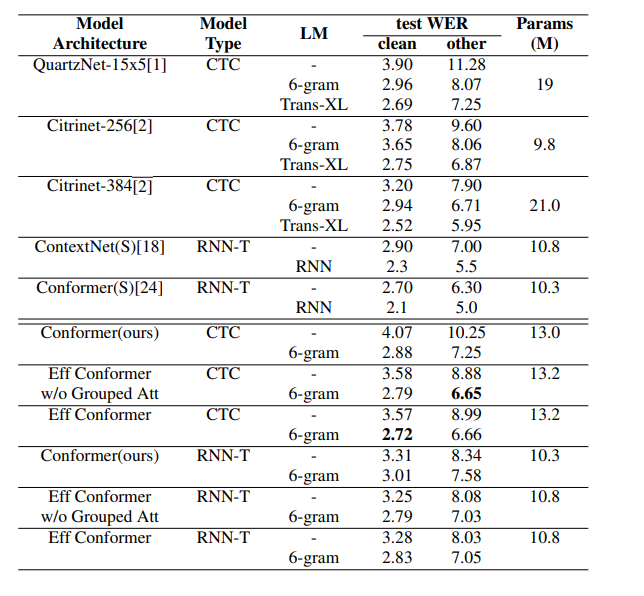
3. EfficientConformer

💡?Motivation?& Method
受Conformer启发,他们想在有限的计算预算下降低Conformer体系结构的复杂性。为了降低Conformer的复杂度,EfficientConformer进行了如下的优化:
-
使用渐进式下采样引入到Conformer编码器中
-
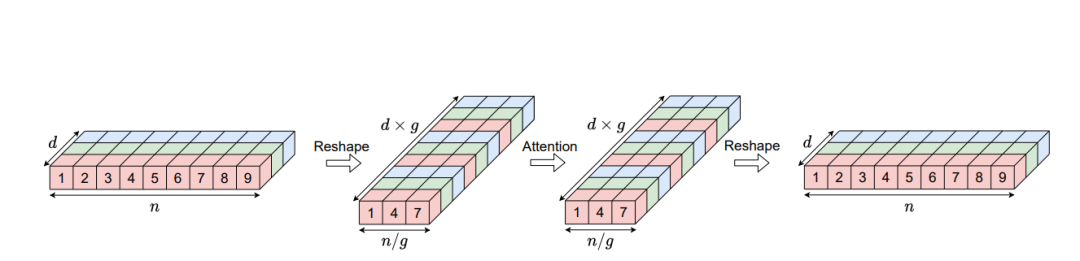
提出了一种名为分组注意力的新型注意力机制。增加grouped操作将自注意力模块的计算复杂度从O(n2d)降低为O(n2d/g),n为时间维度,d为隐层维度,g为group_size
🌌?Model architecture
EfficientConformer结构如下所示,它将原始的Conformer blocks分解为三步,前两个步在N个Conformer Block之后叠加Downsampling Block,沿着时间维度进行下采样;最后一步叠加N个Conformer Block,不再叠加Downsampling Block。

卷积模块(CNN)
上面是Conformer的CNN模块,下面是EfficientConformer的CNN模块。序列下采样是使用跨行深度卷积执行的。将DepthwiseConv的stride设置为大于1的值,从而实现时间维度下采样。因为下采样后输出的shape比输入的shape小,因此残差模块需要增加Pointwise Projection模块将输入和输出映射到相同的维度。

多头注意力模块(GMHA)
首先将Q、K、V的维度变换为(n/g, d*g),其中g为group_size,再进行attention计算,最后将维度变换为原始的(n, d)。变换后,注意力模块的计算复杂度可降低为O(n2d/g)
📊?Experiment?results
4. Squeezeformer

💡?Motivation?&?Method
他们发现Conformer架构的设计选择并不是最优的,它存在如下的一些问题:
-
Conformer学习到的网络深层相邻语音帧的特征表示具有很高的时间冗余性。
-
马卡龙结构以及背靠背多头注意力(MHA)和卷积模块过于复杂。这种复杂性使得很难在专用硬件平台上有效地部署模型进行推理而且对ASR效果是没必要的。
-
微观层面上的一些组件不够简洁且对ASR效果没帮助
在重新研究了Conformer的宏观和微观结构(宏观是指整体结构、微观指一些小的组件)的设计选择后,提出了Squeezeformer:
-
Temporal U-Net 结构: 结合Temporal U-Net,下采样层将网络中间的采样率减半,上采样层在最后恢复采样率以保持训练稳定性。
-
?MFCF block 结构: 作者推荐采用self-attention + ffn + conv module + ffn (MFCF)的组合替代标准Conformer中ffn + self-attention + conv module + ffn(这里的1/2也被取消)。
-
微观架构改动: GLU被替换为Swish;同时作者推荐adaptive scale + PostLN的方式,代替单纯的PreLN或PostLN;subsampling中部分conv被替换为depthwise conv
🌌?Model architecture
Conformer结构(左)和Squeezeformer(右)结构包括用于采样率下采样和上采样的Temporal U-Net结构,仅使用层后归一化的标准transformer风格块结构,以及深度可分离的子采样层。

📊?Experiment?results
条形图和线形图分别表示librisspeech test-other数据集上的WER和FLOPs。对于每次改进,都保持FLOPs差不多情况下对比Squeezeformer比Conformer模型降低1.40%的WER。

在LibriSpeech-960hr上进行实验。最后三列中包括了单个NVIDIA Tesla A100 GPU上的参数数量、FLOPs和吞吐量(Thp)

5. Zipformer

💡?Motivation?&?Method
受Conformer、Squeezeformer启发,他们想提出一种更快,更高效的内存,性能更好的Transformer。
-
类似u-net的编码器结构,其中中间层以较低的帧速率运行,不同层选择不同分辨率;
-
用更多的模块重组块结构,在块结构中重用注意力权重以提高效率;
-
将LayerNorm改进为BiasNorm用以保留一些长度信息;
-
使用功能比Swish更好的SwooshR和SwooshL激活函数。还提出了一个新的优化器,称为ScaledAdam,它按每个张量的当前规模缩放更新以保持相对变化大致相同,并且还显式学习参数规模。
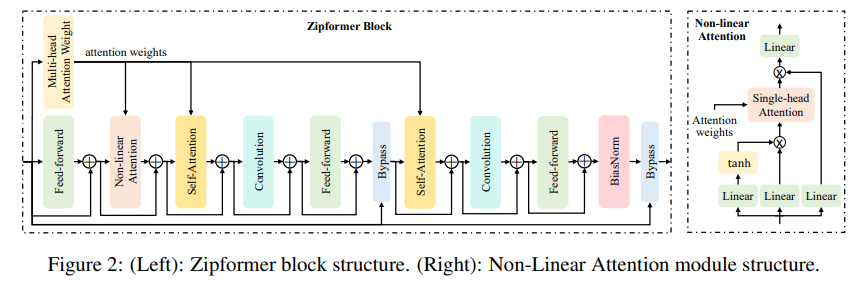
🌌?Model architecture
前面两个blocks用的是50Hz(20ms)这个比Squeezeformer要高,后面的才变低。就是说有更多的采样率种类。

MHSA通过两步学习全局信息:使用点积运算计算注意力权重,并使用这些注意力权重聚合不同的帧信息。这两步复杂度较高。因此,作者将MHSA分解为两个独立的模块:多头注意力权重(MHAW)和自我注意力(SA)。通过使用一个MHAW模块和两个SA模块,更有效地执行两次注意力计算。此外,还提出了一个新的模块非线性注意力(NLA),以充分利用已计算的注意力权重来学习全局信息。
📊?Experiment?results

🧮?Ablation Studies

6. Paraformer

💡?Motivation?&?Method
自回归解码效率很低。为加快推理速度,设计了非自回归(NAR)方法,以实现并行生成。目前NAR存在以下问题:
-
由于输出令牌的独立性假设,单步NAR的性能不如AR模型,特别是在大规模语料库中。
-
改进单步NAR存在两个挑战:一是准确预测输出令牌的数量并提取隐藏变量; 其次,增强对输出令牌之间相互依赖关系的建模。
-
旨在改进单步NAR模型,使其在大规模语料库上获得与AR模型相当的识别性能
为了解决上述问题,Paraformer的作者提出了如下的解决方案:
-
采用一个预测器(Predictor)来预测文字个数并通过Continuous integrate-and-fire (CIF)机制来抽取文字对应的声学隐变量。
-
受Glancing language model(GLM)启发,设计了一个基于GLM的 Sampler模块来增强模型对上下文语义的建模。
-
设计了一种生成负样本的策略来进行最小词错误率训练,以进一步提高性能。
自回归与非自回归结构如下所示,Transformer模型属于自回归模型,也就是说后面的token的推断是基于前面的token的。不能并行,如果使用非自回归模型的话可以极大提升其速度。

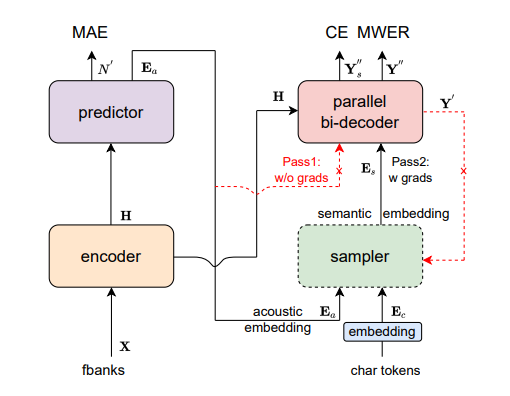
🌌?Model architecture
Paraformer可以分为5个部分,包括Encoder, Predictor, Sampler, Decoder 和Loss function。
-
Encoder 与自回归模型保持一致,可以为 Self-attention、SAN-M 或者 Conformer 结构
-
Predictor 为2层 DNN 模型,预测目标文字个数以及抽取目标文字对应的声学向量指导解码
-
Sampler 依据输入的声学向量和目标向量,生产含有语义的特征向量。(推理时不用)
-
Decoder 结构与自回归模型类似,为双向建模(自回归为单向建模)
-
Loss function 部分,除了交叉熵(CE)与 MWER 区分性优化目标,还包括了 Predictor 优化目标 MAE
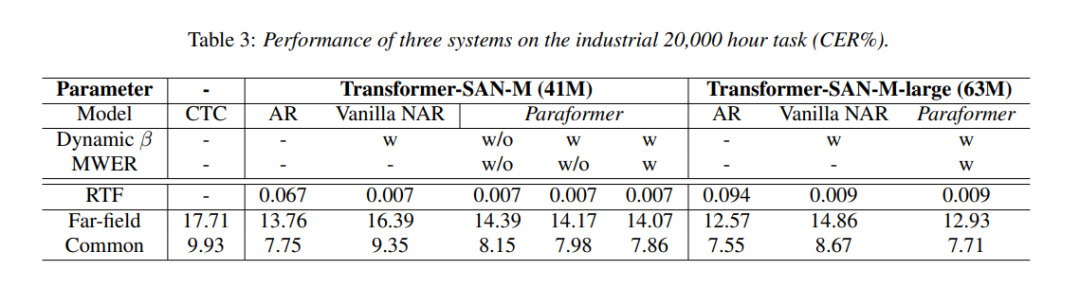
📊?Experiment?results
在Aishell-1上的实验结果表明Paraformer以牺牲一点点精度为代价的情况下,将RTF提升了近10倍。

7. 总结
-
Conformer:?解决语音全局和局部信息的建模。提出的方案是CNN学习局部信息,Transformer学习全局信息,使用夹心饼干的方式结合两者。结果确实比transformer更好了。
-
Branchformer:提出了另一个CNN和Transformer结合的结构,Conformer是串行夹心饼干,它则是并行结合。
-
EfficientConformer:Conformer在深层的时间尺度上下采样提升效率。
-
Squeezeformer:从数据角度证实了时间维度上的冗余,使用U-Net对中间层降采样,从实验角度证明夹心饼干结构是次优。
-
Zipformer:使用了更多种采样率对transformer进行降采样。
-
Paraformer:使用非自回归方式建模。用实验证实了Transformer中的全局信息用token数量和token之间的关系就可以代替。
根据学术界和工业界的研究现状,目前大家主要解决的两个问题:
-
提升ASR推理效率;
-
ASR-Encoder如何更好地学习语音中全局和局部信息
最后,谈一下个人对ASR任务一些可能的工作方向:
1、如何ASR中的去冗余
去冗余的操作有利于语音识别中的效果和推理效率。语音信号包含信息冗余(除语义信息外其他信息,生理、心理)。另一方面,包含时间冗余(短时不变性)。从信号中摒除冗余有助于关注到需要的语义相关信息。就目前来说FBANK+CNN简单有效地提取到语义局部信息,降采样(从粗到细)可以降低时间维度上的冗余。结合语言学知识或许有更简单有效的表征方式等待探索。
2、ASR研究范式
可以从ASR研究范式中学到什么。早期ASR研究范式是专家知识驱动的。语言学规律指导建模。现在的ASR研究范式是数据驱动的,使用大模型大数据以任务为导向学习。前者依赖人的经验总结,而人的经验必然有很多遗漏是粗糙的。后者依赖数据,仍未达到最优。那应该如何逼近最优呢?数据->原理->模型,利用大数据大模型中间结果分析重新细化和更正语言学理论,再利用规律重设计和精简网络。
参考文献:
[1].?Gulati, A., Qin, J., Chiu, C.-C., et al. Conformer: Convolution-augmented Transformer for Speech Recognition[C]// Interspeech 2020, 5036-5040.
[2].?Peng Y, Dalmia S, Lane I, et al. Branchformer: Parallel mlp-attention architectures to capture local and global context for speech recognition and understanding[C]//International Conference on Machine Learning. PMLR, 2022: 17627-17643.
[3].? Burchi M, Vielzeuf V. Efficient conformer: Progressive downsampling and grouped attention for automatic speech recognition[C]//2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2021: 8-15.
[4].? Kim S, Gholami A, Shaw A, et al. Squeezeformer: An efficient transformer for automatic speech recognition[J]. Advances in Neural Information Processing Systems, 2022, 35: 9361-9373.
[5].? Yao Z, Guo L, Yang X, et al. Zipformer: A faster and better encoder for automatic speech recognition[J]. arXiv preprint arXiv:2310.11230, 2023.
[6].?Gao, Z., Zhang, S., McLoughlin, I., Yan, Z. (2022) Paraformer: Fast and Accurate Parallel Transformer for Non-autoregressive End-to-End Speech Recognition. Proc. Interspeech 2022, 2063-2067.
[7].?EfficientConformer?https://zhuanlan.zhihu.com/p/573133117
[8].?Squeezeformer?https://zhuanlan.zhihu.com/p/581923274
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- (16)微信自动化测试-PC微信多开
- 【打卡】牛客网:BM80 买卖股票的最好时机(一)
- Python调用js,Python执行js,pyexecjs2使用方法
- 关于 Ant Design 如何给组件去掉/关闭动画效果的解决方案【Antd v5 已解决】
- 瑞芯微rv1126边缘计算盒子高性价比2.0TOPS INT8/INT16
- 三、04 nginx负载均衡
- 自行车商城网站网页设计与制作web前端设计html+css+js成品。电脑网站制作代开发。vscodeDrea
- 交互式笔记Jupyter Notebook本地部署并实现公网远程访问内网服务器
- Tomcat 部署论坛
- LeetCode 20.有效的括号(python版)