C++初阶 | [七] (下) string类模拟实现
摘要:string类的模拟实现【设计思路+代码示例】;string类底层设计的补充说明【sizeof(string),string类设计上的效率问题:深拷贝的浪费】;扩展【写时拷贝】
1. 创建命名空间
目的:为了和 std 中的 string 区分。
namespace Bottle
{
class string
{
public:
private:
char* _str;
size_t _size;
size_t _capacity;
static size_t npos;
};
size_t string::npos = -1;
}2. Constructor
- 无参的:_str(new char[1] {'\0'}) 这里用?new char[1] {'\0'} 而不是 new char('\0') 是为了和析构函数中的 delete[] 匹配使用。
- 全缺省的:参数缺省值 →?const char* str = ""??空字符串(不含空格) —— 缺省值给空字符串同样默认以 '\0' 字符串结尾,如果这里缺省值给 "\0" 字符串会有两个 '\0' 字符,结尾默认跟 '\0'。
注意:capacity 不算结尾的 '\0' ,但开空间要预留 '\0' 的位置。
示例:?
//Constructor
string()//无参的构造函数
:_str(new char[1] {'\0'})
, _size(0)
, _capacity(0)
{
}
string(const char* str = "")//全缺省的构造函数
:_size(strlen(str))
, _capacity(strlen(str))
{
_str = new char[_capacity + 1];
strcpy(_str, str);
}
3. Destructor
~string()//Destructor
{
delete[]_str;
_str = nullptr;
_size = _capacity = 0;
}4. 遍历string_iterator
1)capacity() ,size()
2)operator[] and const 版本(ps.检查下标的合法性)
3)iterator :用指针实现 → typedef char* iterator;
4)范围for:对 iterator 有严格的要求,本质上就是简单地替换成 iterator ,例如——如果对 begin() 函数改名为 Begin() 都会使范围for不支持。
示例:?
typedef char* iterator;
typedef const char* const_iterator;
///
size_t capacity()const
{
return _capacity;
}
size_t size()const
{
return _size;
}
///
//operator[]
char operator[](size_t i)
{
if (i < _size)
return _str[i];
else
{
std::cout << "非法下标" << std::endl;//也可以选择用asset暴力检查
exit(-1);
}
}
char operator[](size_t i)const
{
if (i < _size)
return _str[i];
else
{
std::cout << "非法下标" << std::endl;
exit(-1);
}
}
///
//iterator
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
const_iterator cbegin()const
{
return _str;
}
const_iterator cend()const
{
return _str + _size;
}5. 增删查改
1)尾插:
插入数据肯定涉及到要扩容的问题,为了先解决扩容的问题——实现 reserve?函数:
-
reserve

//reserve void reserve(size_t n)//可以存储的有效数据个数为'n'个 { if (n > _capacity) { char* tmp = new char[n + 1];//多开一个给''\0' strcpy(tmp, _str);//拷贝数据到新空间(ps.strcpy 会 copy 结尾的'\0') delete[]_str;//释放旧空间 _str = tmp;//指向新空间 _capacity = n; } }
①push_back(char c)
关于扩容的问题:
- reserve(_size + 1);?//每插入一个数据就多开一个数据的空间,可能导致频繁扩容。但是这样写不会出现给 reserve 传的参数为 0 而不扩容的情况。
- reserve(_capacity * 2);//如果 _capacity == 0,就会没扩容,没扩容后面再执行插入数据的操作,会导致访问越界,越界访问会导致delete处崩溃。
综上,最终选择如下这样的写法:
//push_back
void push_back(char c)
{
if (_size == _capacity)//check capacity
{
reserve((_capacity == 0) ? 4 : (_capacity * 2));
}
_str[_size] = c;//push data
++_size;
_str[_size] = '\0';
}②append(const char* str)
//append
void append(const char* str)
{
size_t len = strlen(str);
reserve(_size + len);//check capacity
strcpy(_str + _size, str);//append data
_size += len;
}③operator+=
复用 push_back 和 append 函数即可。
//operator+=
string& operator+=(const char c)
{
push_back(c);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}2)insert
思路:①检查 pos 位置的有效性;②检查容量;③挪动数据;④插入数据(strncpy)。
特殊情况:头插(pos==0)ps.下面的 pos 和 end 都是指下标
 ①size_t end 是无符号整型,-1即为整型的最大值,以 end >= pos 作为循环判断条件,在 pos ==0 时会出现?“-1>0”?的情况,于是进入死循环;
①size_t end 是无符号整型,-1即为整型的最大值,以 end >= pos 作为循环判断条件,在 pos ==0 时会出现?“-1>0”?的情况,于是进入死循环;
②即使定义?int end,仍以 end >= pos 作为循环判断条件,>=操作符左右操作数的类型不同,会发生类型转换,通常是比较范围小的向范围大的转换,即在该情况下,有符号整型一般转化为无符号整型。
有两种方式解决上述情况:
①强制类型转换成 int 进行比较;(int)end>=(int)pos;
②让 end 所指数据?将要被挪动到的位置?而不是指将要被挪动的数据。_str[end+len] = _str[end]? ?_str[end] = _str[end - len]


代码示例:?
//insert
string& insert(size_t pos, const char c)//在pos位置插入c
{
//check
assert(pos < _size);
//capacity
reserve(_size + 1);
//move
size_t end = _size + 1;
for (; end >= pos + 1; --end)
{
_str[end] = _str[end - 1];
}
//insert
_str[pos] = c;
_size += 1;
return *this;
}
string& insert(size_t pos, const char* str)//在pos位置插入串str
{
//check
assert(pos < _size);
//capacity
size_t len = strlen(str);
reserve(_size + len);
//move
size_t end = _size + len;
for (; end >= pos + len; --end)
{
_str[end] = _str[end - len];
}
//insert
strncpy(_str + pos, str, len);
_size += len;
return *this;
}3)erase
//erase
string& erase(size_t pos, size_t len = npos)
{
//check
assert(pos < _size);
if ((pos + len >= _size) || (npos == -1))//如果len足够长,长到删完pos位置后面所有的数据
{
_size = pos;
}
else
{ //数据从后往前挪动覆盖删除
for (size_t i = pos + len; i < _size; ++i)
{
_str[i - len] = _str[i];
}
_size -= len;
}
_str[_size] = '\0';
return *this;
}注意:?(pos + len >= _size) || (npos == -1) 这两个情况 pos + len >= _size?与?npos == -1?要分开判断,因为 -1已经是无符号整型的最大值,再在其上加上数据会溢出——超出无符号整型能存储的最大数值。
4)操作符重载
-
比较操作符重载
这些比较操作符库里实现的是全局函数,而非成员函数,是考虑到除了 string类(char) 以外还要匹配其他的类型(Types),这里我们简单地实现为成员函数。
代码示例:
//Compare
bool operator==(const string& s)const
{
return (strcmp(this->_str, s._str) == 0);
}
bool operator<(const string& s)const
{
return (strcmp(this->_str, s._str) < 0);
}
bool operator>(const string& s)const
{
return (strcmp(this->_str, s._str) > 0);
}
bool operator>=(const string& s)const
{
return ((*this > s) || (*this == s));
}
bool operator<= (const string& s)const
{
return (!(*this > s));
}-
流插入和流提取重载
不一定要写成友元函数,因为这里不用访问私有函数。
- 流插入重载代码示例:
namaspace Bottle { class string { //…… }; std::ostream& operator<<(std::ostream& out, const string& s) { for (size_t i = 0; i < s.size(); ++i) { out << s[i]; } return out; } } -
?流提取重载
注意:cin 和 scanf 都是以空格和换行为一段输入的间隔,如下图所示。为了解决下示问题,可以采用 get 函数。get - C++ Reference (cplusplus.com) ?
?流提取代码示例:(注意:流提取之前要清空string对象中原有的数据,不然就会变成?流提取重载?就会变成?尾插数据?)
std::istream& operator>>(std::istream& in, string& s) { s.clear();//clear existing data char ch = in.get(); while (ch != ' ' && ch != '\n') { s += ch; ch = in.get(); } return in; }
流提取中关于扩容的问题:可以通过创建缓冲区数组优化频繁扩容的问题。先把读到的数据存到缓冲区数组,如果缓冲区数据满了就插入到原本要插入的string类对象中,这样就避免了每次单个单个插入字符而导致的频繁扩容。代码示例如下:
std::istream& operator>>(std::istream& in, string& s)
{
s.clear();//clear existing data
char buff[129] = { 0 };
size_t i = 0;
char ch = in.get();
while (ch != ' ' && ch != '\n')
{
buff[i] = ch;//读到的数据先存到buff数组中
++i;
if (i == 128)//buff数组存满后插入到string& s中
{
buff[i] = '\0';
s += buff;
i = 0;
}
}
if (i != 0)//如果缓冲区数据内还有剩余数据,记得把剩下的数据插入string& s中
{
buff[i] = '\0';
s += buff;
}
return in;
}
5)resize
resize 改变 size 的大小,分以下三种情况讨论:
- new_size <= now_size:delete data
- new_size > now_size && new_size < capacity:insert data
- new_size >= capacity:reserve and inser data
后两种情况可以合并,因为即使?reserve(new_size) 当 new_size < capacity 时也不会缩容。
代码示例:
//resize
void resize(const size_t sz, const char c = '\0')
{
if (sz < _size)
{
//delete
_str[_size] = '\0';
_size = sz;
}
else
{
reserve(sz);//检查容量,必要时扩容
//insert
for (size_t i = _size; i < sz; ++i)
{
_str[i] = c;
}
_str[_size] = '\0';
_size = sz;
}
}6)find
- 找某一个元素:size_t find(const char c, size_t pos = 0) const
- 找字串:size_t find(const char* s, size_t pos = 0) const
?? ? ? ? ? ? ?①暴力匹配:挨个找? → strstr;(示例代码采用暴力匹配)
? ? ? ? ? ? ? ②kmp(算法):理论上效率高,但现实中很少用,实际上实现效率没有很高;
? ? ? ? ? ? ? ③BM(算法):好用,但难。
? ? ? ? ? ? ?
代码示例:?
// 返回c在string中第一次出现的位置
size_t find(const char c, size_t pos = 0) const
{
assert(pos < _size);//check pos
size_t i = pos;
for (; i < _size; ++i)
{
if (_str[i] == c)
return i;
}
return -1;
}
// 返回子串s在string中第一次出现的位置
size_t find(const char* s, size_t pos = 0) const
{
assert(pos < _size);//check pos
size_t len = strlen(s);
for (size_t i = pos; i + len < _size; ++i)
{
char* p = strstr(_str + i, s);
if (p != nullptr)
{
return p - _str;
}
}
return -1;
}7)substr
substr:从 pos 位置取 len 长度的字符串
思路:1. pos+len >= size or len == npos:from pos to size
? ? ? ? ? ?2. else:from pos to pos+len
注意:传值返回,需要写 拷贝构造? → 涉及深拷贝的问题(详见下一部分?8)深拷贝?)
代码示例:
//从pos位置取len长度的字符串
string substr(const size_t pos, const size_t len = npos)const
{
if ((len == npos) || (pos + len >= _size))
{
string tmp(_str + pos);//从pos往后的数据全部copy
return tmp;
}
else
{
string tmp;
tmp.reserve(len);//check capacity
for (size_t i = 0; i < len; ++i)
{
tmp += _str[pos + i];
}
return tmp;
}
}8)深拷贝
copy constructor
代码示例:
string(const string& s)//copy constructor
{
_str = new char[s._capacity + 1];
strcpy(_str, s._str);
_size = s._size;
_capacity = s._capacity;
}赋值重载
如下图所示,赋值重载函数的实现思路:①开新空间;②将右操作数的数据拷贝到新空间;③释放旧空间——左操作数原本指向的空间;④让做左操作数指向新空间。
注意:自己给自己赋值的情况!(如果第一步就是释放旧空间,而此时是自己给自己赋值时,会导致错误的结果)
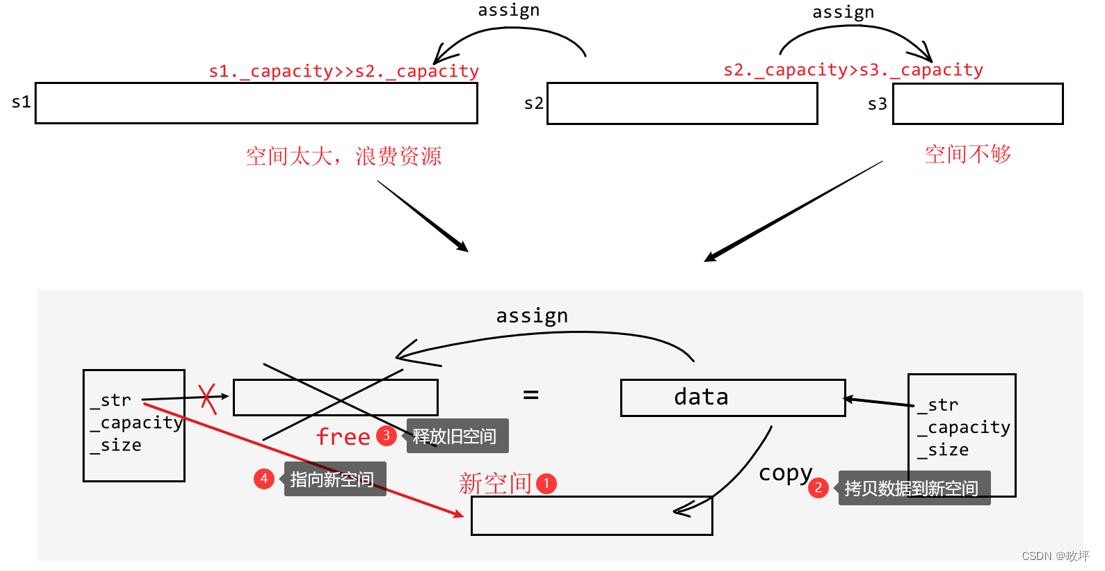
代码示例:
string& operator=(const string& s)//assign
{
if (this != &s)
{
char* tmp = new char[s._capacity + 1];
strcpy(tmp, s._str);
delete[]_str;
_str = tmp;
_size = s._size;
_capacity = s._capacity;
return *this;
}
}上述进行深拷贝行为的写法被成为“传统写法”。下面介绍一种“现代写法”。
- 对于拷贝构造函数:
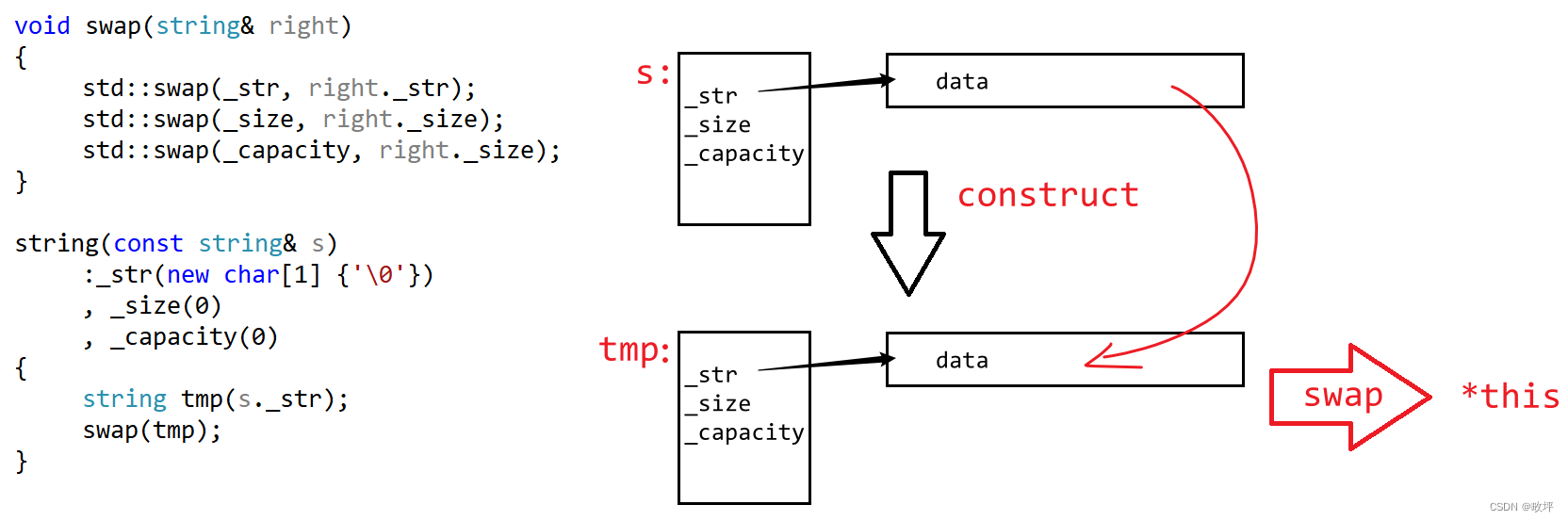
?ps.这里交换 tmp 和要被构造的对象 *this 要注意一个问题:要被构造的对象存储的数据可能随机值(这里尤指其中的私有成员?_str?存的地址是一个随机地址),拷贝构造函数执行完后,tmp 会调用析构函数,delete[]?一个随机地址会出现问题,所以这个构造函数最好先在初始化列表对成员变量初始化。如下图所示。
注意:其中用到的 swap 函数要自己实现,不建议直接用C++标准库里的 swap 函数。
- 对于赋值重载:

?
以上,传统写法和现代写法本质上是一样的,效率上没有区别,只是写法上更简洁。
补充说明:
1)sizeof(string)
不同平台下 string类 的底层设计不同。

?
2)string类设计上的效率问题:深拷贝的浪费
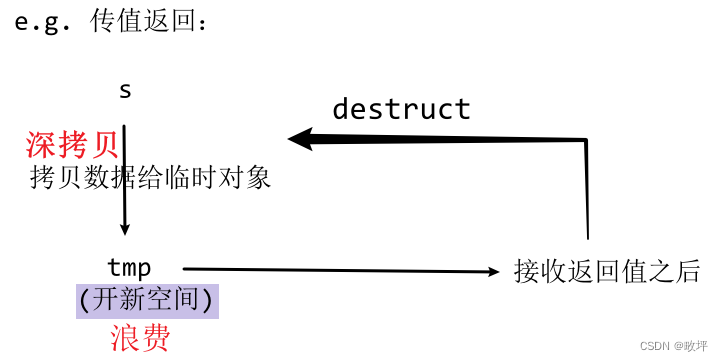 ?既然深拷贝导致了浪费,那么我们考虑可不可以浅拷贝。
?既然深拷贝导致了浪费,那么我们考虑可不可以浅拷贝。
浅拷贝具有两个问题:
①两个对象中的两个指针指向同一块空间,而导致该空间会被析构两次。
②当我们修改其中一个对象的时候会影响另一个对象。
接下来我们针对以上两个问题做讨论。(以下仅作简单粗略的讨论,仅供了解)
- 析构两次 👉 引用计数
引用计数:记录有几个对象指向这个空间
作用过程:引用计数 = 2 → 其中一个对象析构一次之后 → 引用计数减一
? ? ? ? ? ? ? ? ? 引用计数 = 1 → 另一个对象不执行析构 → 引用计数减一,并释放这个对象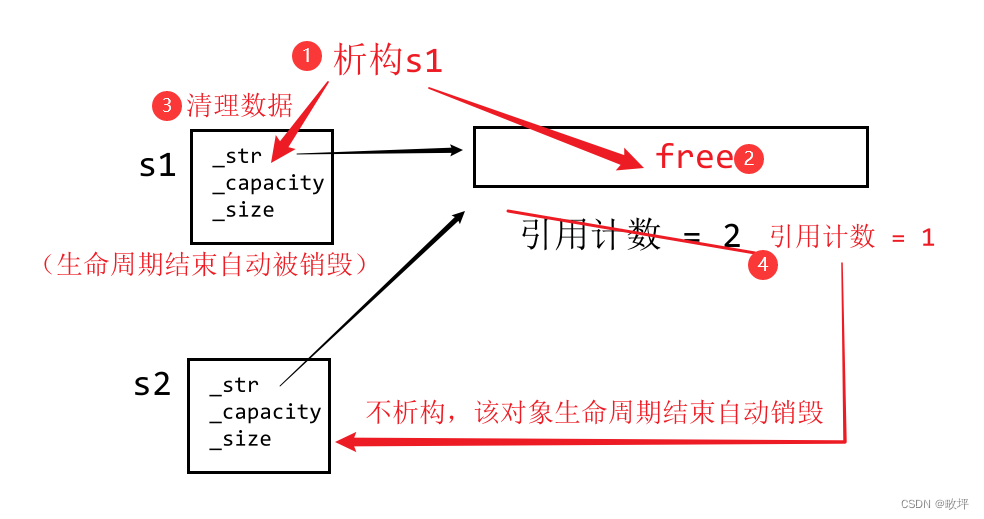
?
- 修改影响 👉 写时拷贝
写时拷贝:对数据进行修改时进行深拷贝(延迟拷贝)
作用过程:引用计数 = 1 → 修改行为可以直接进行
? ? ? ? ? ? ? ? ? 引用计数 ≠ 1 →? 要进行修改时,进行深拷贝,新开的空间配新的引用计数 → 引用计数减一
全称:引用计数写时拷贝
总结:在不需要修改的场景下,写时拷贝会避免很多资源浪费。
(ps.g++采用的是写时拷贝)
END?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 计算机系统基础_第六章-层次结构存储系统_期末速成
- 十四、W5100S/W5500+RP2040之MicroPython开发<MQTT&ThingSpeak示例>
- 15 责任链模式
- JAVA进化史: JDK8特性及说明
- 计算机网络 - 路由器查表过程模拟 C++(2024)
- 算法——广度优先搜索(BFS)
- 经典目标检测YOLO系列(一)复现YOLOV1(5)模型的训练及验证
- Vc++ 6.0对话框实现简单的单据套打预览及打印功能,源码正常编译
- 超级管理员权限&绕过windows登录&windows命令
- 浅析性能测试策略及适用场景