Kafka-生产调优
Kafka生产调优实践
通常在生产环境中,Kafka都是用来应对整个项目中最高峰的流量
搭建Kafka监控平台
生产环境通常会对Kafka搭建监控平台。而Kafka-eagle就是一个可以监控Kafka集群整体运行情况的框架,在生产环境经常会用到。官网地址:EFAK 以前叫做Kafka-eagle,现在用了简写,EFAK(Eagle For Apache Kafka)
环境准备:
在官网的DownLoad页面可以下载EFAK的运行包,efak-web-3.0.2-bin.tar.gz。
另外,EFAK需要依赖的环境主要是Java和数据库。其中,数据库支持本地化的SQLLite以及集中式的MySQL。生产环境建议使用MySQL。在搭建EFAK之前,需要准备好对应的服务器以及MySQL数据库。
# linux安装mysql,我用的第一个5.7版本
wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz
wget https://cdn.mysql.com/archives/mysql-8.0/mysql-8.0.22-linux-glibc2.12-x86_64.tar.xzUnit mysql.service could not be found解决参考文章:解决Unit mysql.service could not be found-CSDN博客
MySQL安装参考文章:解决缺少libncurses.so.5库文件-CSDN博客
安装过程:以Linux服务器为例。
1、将efak压缩包解压。
tar -zxvf efak-web-3.0.2-bin.tar.gz -C /app/kafka/eagle2、修改efak解压目录下的conf/system-config.properties。 这个文件中提供了完整的配置,下面只列出需要修改的部分。
######################################
# multi zookeeper & kafka cluster list
# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead
######################################
# 指向Zookeeper地址
efak.zk.cluster.alias=cluster1
cluster1.zk.list=worker1:2181,worker2:2181,worker3:2181
######################################
# zookeeper enable acl
######################################
# Zookeeper权限控制
cluster1.zk.acl.enable=false
cluster1.zk.acl.schema=digest
#cluster1.zk.acl.username=test
#cluster1.zk.acl.password=test123
######################################
# kafka offset storage
######################################
# offset选择存在kafka中。
cluster1.efak.offset.storage=kafka
#cluster2.efak.offset.storage=zk
######################################
# kafka mysql jdbc driver address
######################################
#指向自己的MySQL服务。库需要提前创建
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://worker1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=root3、配置EFAK的环境变量
vi ~/.bash_profile
-- 配置KE_HOME环境变量,并添加到PATH中。
export KE_HOME=/app/kafka/eagle/efak-web-3.0.2
PATH=$PATH:#KE_HOME/bin:$HOME/.local/bin:$HOME/bin
--让环境变量生效
source ~/.bash_profile4、启动EFAK
配置完成后,先启动Zookeeper和Kafka服务,然后调用EFAK的bin目录下的ke.sh脚本启动服务
[root@worker1 bin]$ ./ke.sh start
-- 日志很长,看到以下内容表示服务启动成功
[2023-12-16 16:09:43] INFO: [Job done!]
Welcome to
______ ______ ___ __ __
/ ____/ / ____/ / | / //_/
/ __/ / /_ / /| | / ,<
/ /___ / __/ / ___ | / /| |
/_____/ /_/ /_/ |_|/_/ |_|
( Eagle For Apache Kafka? )
Version v3.0.2 -- Copyright 2016-2022
*******************************************************************
* EFAK Service has started success.
* Welcome, Now you can visit 'http://192.168.146.128:8048'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> https://www.kafka-eagle.org/ </Usage>
*******************************************************************5、访问EFAK管理页面
接下来就可以访问EFAK的管理页面。解决缺少libncurses.so.5库文件-CSDN博客。 默认的用户名是admin ,密码是123456
合理规划Kafka部署环境
机械硬盘:准备部署Kafka服务的服务器,建议配置大容量机械硬盘。
大内存:在Kafka的服务启动脚本bin/kafka-server-start.sh中,对于JVM内存进行适当优化。
# 默认只申请了1G内存
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
? export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
? ?
# 对于主流的16核32G服务器,可以适当扩大Kafka的内存
export KAFKA_HEAP_OPTS="‐Xmx16G ‐Xms16G ‐Xmn10G ‐XX:MetaspaceSize=256M ‐XX:+UseG1GC ‐XX:MaxGCPauseMillis=50 ‐XX:G1HeapRegionSize=16M"高性能网卡:Kafka本身的服务性能非常高,单机就可以支持百万级的TPS。在高流量冲击下,网络非常有可能优先于服务,成为性能瓶颈。并且Kafka集群内部也需要大量同步消息。因此,对于Kafka服务器,建议配置高性能的网卡。成本允许的话,尽量选择千兆以上的网卡。
合理优化Kafka集群配置
合理配置Partition数量: Kafka的单个Partition读写效率是非常高的,但是,如果Partition文件过多,很容易严重影响Kafka的整体性能。
控制Partition文件数量主要有两个方面: 1、尽量不要使用过多的Topic,通常不建议超过3个Topic。过多的Topic会加大索引Partition文件的压力。2、每个Topic的副本数不要设置太多。大部分情况下,将副本数设置为2就可以了。
Partition的数量,最好根据业务情况灵活调整。partition数量设置多一些,可以一定程度增加Topic的吞吐量。但是过多的partition数量还是同样会带来partition索引的压力。
Kafka提供了一个生产者的性能压测脚本,可以用来衡量集群的整体性能。
bin/kafka-producer-perf-test.sh --topic test --num-record 1000000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=worker1:9092 acks=1
?
// num-record表示要发送100000条压测消息,
// record-size表示每条消息大小1KB,
// throughput表示限流控制,设置为小于0表示不限流。
// properducer-props用来设置生产者的参数合理对数据进行压缩:在生产者的ProducerConfig中,有一个配置 COMPRESSION_TYPE_CONFIG,是用来对消息进行压缩的。
/** <code>compression.type</code> */
public static final String COMPRESSION_TYPE_CONFIG = "compression.type";
private static final String COMPRESSION_TYPE_DOC = "The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid "
? + " values are <code>none</code>, <code>gzip</code>, <code>snappy</code>, <code>lz4</code>, or <code>zstd</code>. "
? + "Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).";Kafka的生产者支持四种压缩算法。其中,zstd算法具有最高的数据压缩比,但是吞吐量不高。lz4在吞吐量方面的优势比较明显。在实际使用时,可以根据业务情况选择合适的压缩算法。但是要注意下,压缩消息必然增加CPU的消耗,如果CPU资源紧张,就不要压缩了。
关于数据压缩机制,在Broker端的broker.conf文件中,也是可以配置压缩算法的。正常情况下,Broker从Producer端接收到消息后不会对其进行任何修改,但是如果Broker端和Producer端指定了不同的压缩算法,就会产生很多异常的表现。
compression.type
Specify the final compression type for a given topic. This configuration accepts the standard compression codecs ('gzip', 'snappy', 'lz4', 'zstd'). It additionally accepts 'uncompressed' which is equivalent to no compression; and 'producer' which means retain the original compression codec set by the producer.
?
Type: string
Default: producer
Valid Values: [uncompressed, zstd, lz4, snappy, gzip, producer]
Server Default Property: compression.type
Importance: medium如果开启了消息压缩,那么在消费者端自然是要进行解压缩的。在Kafka中,消息从Producer到Broker再到Consumer会一直携带消息的压缩方式,这样当Consumer读取到消息集合时,自然就知道了这些消息使用的是哪种压缩算法,也就可以自己进行解压了。但是这时要注意的是应用中使用的Kafka客户端版本和Kafka服务端版本是否匹配。
优化Kafka客户端使用方式
合理保证消息安全
在生产者端最好从以下几个方面进行优化。
-
设置好发送者应答参数:主要涉及到两个参数。
-
生产者的ACKS_CONFIG配置。acks=0,生产者不关心Broker端有没有将消息写入到Partition,只发送消息就不管了。acks=all or -1,生产者需要等Broker端的所有Partition(Leader Partition以及其对应的Follower Partition都写完了才能得到返回结果,这样数据是最安全的,但是每次发消息需要等待更长的时间,吞吐量是最低的。acks设置成1,则是一种相对中和的策略。Leader Partition在完成自己的消息写入后,就向生产者返回结果。、
其中acks=1是应用最广的一种方案。但是,如果结合服务端的min.insync.replicas参数,就可以配置更灵活的方式。
-
min.insync.replicas参数表示如果生产者的acks设置为-1或all,服务端并不是强行要求所有Paritition都完成写入再返回,而是可以配置多少个Partition完成消息写入后,再往Producer返回消息。比如,对于一个Topic,设置他的备份因子replication factor为3,然后将min.insync.replicas参数配置为2,而生产者端将ACKS_CONFIG设定为-1或all,这样就能在消息安全性和发送效率之间进行灵活选择。
-
-
打开生产者端的幂等性配置:ENABLE_IDEMPOTENCE_CONFIG。 生产者将这个参数设置为true后,服务端会根据生产者实例以及消息的目标Partition,进行重复判断,从而过滤掉生产者一部分重复发送的消息。
-
使用生产者事务机制发送消息:
在打开幂等性配置后,如果一个生产者实例需要发送多条消息,而你能够确定这些消息都是发往同一个Partition的,那么你就不需要再过多考虑消息安全的问题。但是如果你不确定这些消息是不是发往同一个Partition,那么尽量使用异步发送消息机制加上事务消息机制进一步提高消息的安全性。
生产者事务机制:
// 1 初始化事务
void initTransactions();
// 2 开启事务
void beginTransaction() throws ProducerFencedException;
// 3 提交事务
void commitTransaction() throws ProducerFencedException;
// 4 放弃事务(类似于回滚事务的操作)
void abortTransaction() throws ProducerFencedException;在消费者端,Kafka消费消息是有重试机制的,如果消费者没有主动提交事务(自动提交或者手动提交),这些失败的消息是可以交由消费者组进行重试的,所以正常情况下,消费者这一端是不会丢失消息的。但是如果消费者要使用异步方式进行业务处理,那么如果业务处理失败,此时消费者已经提交了Offset,这个消息就无法重试了,这就会造成消息丢失。
因此在消费者端,尽量不要使用异步处理方式,在绝大部分场景下,就能够通过Kafka的消费者重试机制,保证消息安全处理。此时,在消费者端,需要更多考虑的问题,就变成了消费重试机制造成的消息重复消费的问题。
消费者防止消息重复消费
通常消费者实现步骤:
while (true) {
//拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofNanos(100));
//处理消息
for (ConsumerRecord<String, String> record : records) {
//do business ...
}
//提交offset,消息就不会重复推送。
consumer.commitSync(); //同步提交,表示必须等到offset提交完毕,再去消费下一批数据。
}大部分业务场景没有问题,但是在大型项目中,消费者的业务流程处理很长,Broker认为消息处理失败后,回推送消息给同一个消费者组的其他消费者实例,由这种重试机制造成消费的幂等性问题。
消费者端的幂等性问题,可以交给消费者自己进行处理,大部分的业务场景下也是这样处理的。但是这样会给消费者端带来更大的业务复杂性。
但是在很多大型项目中,消费者端的业务逻辑有可能是非常复杂的。因此会更希望以一种统一的方式处理幂等性问题,让消费者端能够专注于处理自己的业务逻辑。这时,在大型项目中有一种比较好的处理方式就是将Offset放到Redis中自行进行管理。通过Redis中的offset来判断消息之前是否处理过。
while(true){
? ?//拉取消息
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
? ?records.partitions().forEach(partition ->{
? ? ? ? ?//从redis获取partition的偏移量
? ? ? ?String redisKafkaOffset = redisTemplate.opsForHash().get(partition.topic(), "" + partition.partition()).toString();
? ? ? ?long redisOffset = StringUtils.isEmpty(redisKafkaOffset)?-1:Long.valueOf(redisKafkaOffset);
?List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
? ? ? ?partitionRecords.forEach(record ->{
? ? ? ? ? ?//redis记录的偏移量>=kafka实际的偏移量,表示已经消费过了,则丢弃。
? ? ? ? ? ?if(redisOffset >= record.offset()){
? ? ? ? ? ? ? ?return;
? ? ? ? ? }
? ? ? ? ? ?//业务端只需要实现这个处理业务的方法就可以了,不用再处理幂等性问题
? ? ? ? ? ?doMessage(record.topic(),record.value());
? ? ? });
? });
? ?//处理完成后立即保存Redis偏移量
? ?long saveRedisOffset = partitionRecords.get(partitionRecords.size() - 1).offset();
? ?redisTemplate.opsForHash().put(partition.topic(),"" + partition.partition(),saveRedisOffset);
? ?//异步提交。消费业务多时,异步提交有可能造成消息重复消费,通过Redis中的Offset,就可以过滤掉这一部分重复的消息。。
? ?consumer.commitAsync();
}将这段代码封装成一个抽象类,具体的业务消费者端只要继承这个抽象类,然后就可以专注于实现doMessage方法,处理业务逻辑即可,不用再过多关心幂等性的问题。
生产环境常见问题分析
消息零丢失方案
生产者发送消息到Broker不丢失
Kafka的消息生产者Producer,支持定制一个参数,ProducerConfig.ACKS_CONFIG。
-
acks配置为0 : 生产者只负责往Broker端发消息,而不关注Broker的响应。也就是说不关心Broker端有没有收到消息。性能高,但是数据会有丢消息的可能。
-
acks配置为1:当Broker端的Leader Partition接收到消息后,只完成本地日志文件的写入,然后就给生产者答复。其他Partiton异步拉取Leader Partiton的消息文件。这种方式如果其他Partiton拉取消息失败,也有可能丢消息。
-
acks配置为-1或者all:Broker端会完整所有Partition的本地日志写入后,才会给生产者答复。数据安全性最高,但是性能显然是最低的。
对于KafkaProducer,只要将acks设置成1或-1,那么Producer发送消息后都可以拿到Broker的反馈RecordMetadata,里面包含了消息在Broker端的partition,offset等信息。通过这这些信息可以判断消息是否发送成功。如果没有发送成功,Producer就可以根据情况选择重新进行发送。
Broker端保存消息不丢失
合理优化刷盘频率,防止服务异常崩溃造成消息未刷盘。Kafka的消息都是先写入操作系统的PageCache缓存,然后再刷盘写入到硬盘。PageCache缓存中的消息是断电即丢失的。如果消息只在PageCache中,而没有写入硬盘,此时如果服务异常崩溃,这些未写入硬盘的消息就会丢失。Kafka并不支持写一条消息就刷一次盘的同步刷盘机制,只能通过调整刷盘的执行频率,提升消息安全。主要涉及几个参数:
-
flush.ms : 多长时间进行一次强制刷盘。
-
log.flush.interval.messages:表示当同一个Partiton的消息条数积累到这个数量时,就会申请一次刷盘操作。默认是Long.MAX。
-
log.flush.interval.ms:当一个消息在内存中保留的时间,达到这个数量时,就会申请一次刷盘操作。他的默认值是空。
然后,配置多备份因子,防止单点消息丢失。在Kafka中,可以给Topic配置更大的备份因子replication-factors。配置了备份因子后,Kafka会给每个Partition分配多个备份Partition。这些Partiton会尽量平均的分配到多个Broker上。并且,在这些Partiton中,会选举产生Leader Partition和Follower Partition。这样,当Leader Partition发生故障时,其他Follower Partition上还有消息的备份。就可以重新选举产生Leader Partition,继续提供服务。
消费者端防止异步处理丢失消息
消费者端由于有消息重试机制,正常情况下是不会丢消息的。每次消费者处理一批消息,需要在处理完后给Broker应答,提交当前消息的Offset。Broker接到应答后,会推进本地日志的Offset记录。如果Broker没有接到应答,那么Broker会重新向同一个消费者组的消费者实例推送消息,最终保证消息不丢失。这时,消费者端采用手动提交Offset的方式,相比自动提交会更容易控制提交Offset的时机。
消费者端唯一需要注意的是,不要异步处理业务逻辑。
消息积压如何处理
通常情况下,Kafka本身是能够存储海量消息的,他的消息积压能力是很强的。但是,如果发现消息积压问题已经影响了业务处理进度,这时就需要进行一定的优化。
1、如果业务运行正常,只是因为消费者处理消息过慢,造成消息加压。那么可以增加Topic的Partition分区数,将消息拆分到更到的Partition。然后增加消费者个数,最多让消费者个数=Partition分区数,让一个Consumer负责一个分区,将消费进度提升到最大。
另外,在发送消息时,还是要尽量保证消息在各个Partition中的分布比较均匀。比如,在原有Topic下,可以调整Producer的分区策略,让Producer将后续的消息更多的发送到新增的Partition里,这样可以让各个Partition上的消息能够趋于平衡。如果你觉得这样太麻烦,那就新增一个Topic,配置更多的Partition以及对应的消费者实例。然后启动一批Consumer,将消息从旧的Topic搬运到新的Topic。这些Consumer不处理业务逻辑,只是做消息搬运,所以他们的性能是很高的。这样就能让新的Topic下的各个Partition数量趋于平衡。
2、如果是消费者的业务问题导致消息阻塞了,从而积压大量消息,并影响了系统正常运行。比如消费者序列化失败,或者业务处理全部异常。这时可以采用一种降级的方案,先启动一个Consumer将Topic下的消息先转发到其他队列中,然后再慢慢分析新队列里的消息处理问题。类似于死信队列的处理方式。
如何保证消息顺序
如何保证Producer发到Partition上的消息是有序的
一种简答粗暴的想法就是给Topic只配一个Partition,没有其他Partition可选了,自然所有消息都到同一个Partition上了。但是放弃了吞吐量,显然是不现实的。
更现实的想法,Topic配置多个Partition,但是通过定制Producer的Partition分区器,将消息分配到同一个Partition上。这样对于某一些要求局部有序的场景至少是可行的。但是要考虑到消息失败重新发送的情况,重试次数多少?顺序消息有多少各步骤?处理起来就很难,而且性能很难保证了。
其实消息顺序这事,Kafka是有考量的。回顾对于生产者消息幂等性的设计:
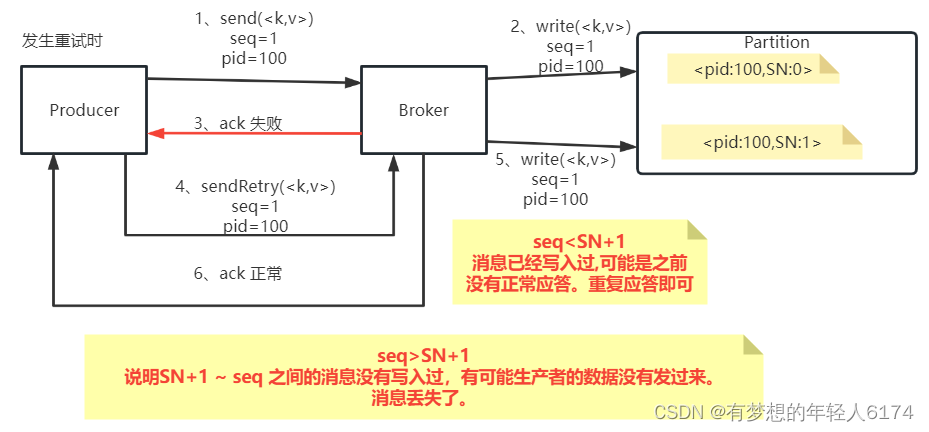
Kafka的这个sequenceNumber是单调递增的。如果只是为了消息幂等性考虑,那么只要保证sequenceNumber唯一就行了,为什么要设计成单调递增呢?其实Kafka这样设计的原因就是可以通过sequenceNumber来判断消息的顺序。也就是说,在Producer发送消息之前就可以通过sequenceNumber定制好消息的顺序,然后Broker端就可以按照顺序来保存消息。与此同时, SequenceNumber单调递增的特性不光保证了消息是有顺序的,同时还保证了每一条消息不会丢失。一旦Kafka发现Producer传过来的SequenceNumber出现了跨越,那么就意味着中间有可能消息出现了丢失,就会往Producer抛出一个OutOfOrderSequenceException异常。
public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection";
private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking."
+ " Note that if this configuration is set to be greater than 1 and <code>enable.idempotence</code> is set to false, there is a risk of"
+ " message reordering after a failed send due to retries (i.e., if retries are enabled); "
+ " if retries are disabled or if <code>enable.idempotence</code> is set to true, ordering will be preserved."
+ " Additionally, enabling idempotence requires the value of this configuration to be less than or equal to " + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_FOR_IDEMPOTENCE + "."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled. ";
?
public static final String RETRIES_CONFIG = CommonClientConfigs.RETRIES_CONFIG;
private static final String RETRIES_DOC = "Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error."
+ " Note that this retry is no different than if the client resent the record upon receiving the error."
+ " Produce requests will be failed before the number of retries has been exhausted if the timeout configured by"
+ " <code>" + DELIVERY_TIMEOUT_MS_CONFIG + "</code> expires first before successful acknowledgement. Users should generally"
+ " prefer to leave this config unset and instead use <code>" + DELIVERY_TIMEOUT_MS_CONFIG + "</code> to control"
+ " retry behavior."
+ "<p>"
+ "Enabling idempotence requires this config value to be greater than 0."
+ " If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled."
+ "<p>"
+ "Allowing retries while setting <code>enable.idempotence</code> to <code>false</code> and <code>" + MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION + "</code> to 1 will potentially change the"
+ " ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second"
+ " succeeds, then the records in the second batch may appear first.";思考:这种机制其实不光适合Kafka这样的消息发送场景,如果你的微服务对请求顺序敏感,这也是一种非常值得借鉴的方案
Partition中的消息有序后,如何保证Consumer的消费顺序是有序的
public static final String FETCH_MAX_BYTES_CONFIG = "fetch.max.bytes";
private static final String FETCH_MAX_BYTES_DOC = "The maximum amount of data the server should return for a fetch request. " +
"Records are fetched in batches by the consumer, and if the first record batch in the first non-empty partition of the fetch is larger than " +
"this value, the record batch will still be returned to ensure that the consumer can make progress. As such, this is not a absolute maximum. " +
"The maximum record batch size accepted by the broker is defined via <code>message.max.bytes</code> (broker config) or " +
"<code>max.message.bytes</code> (topic config). Note that the consumer performs multiple fetches in parallel.";
public static final int DEFAULT_FETCH_MAX_BYTES = 50 * 1024 * 1024;Consumer其实是每次并行的拉取多个Batch批次的消息进行处理的。也就是说Consumer拉取过来的多批消息并不是串行消费的。所以在Kafka提供的客户端Consumer中,是没有办法直接保证消费的消息顺序。
所以这时候,我们能做的就是在Consumer的处理逻辑中,将消息进行排序。比如将消息按照业务独立性收集到一个集合中,然后在集合中对消息进行排序。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 142.环形链表 II 、141. 环形链表(附带源码)
- 计算机专业的大学毕业生,怎么快速的写文献综述呢?
- Ncast盈可视高清智能录播系统busiFacade RCE漏洞(CVE-2024-0305)
- java爱心代码动态
- 什么是redis雪崩
- 数据挖掘总结(考试版)
- 数字经济理论体系:推动数字经济的发展应用的科学指引
- spring ioc容器
- 提升图像分割精度:学习UNet++算法
- [zabbix] 分布式应用之监控平台zabbix的认识与搭建