MySQL解决海量数据和并发性的方案——分库分表
发布时间:2024年01月15日
分库分表其实是两个事情,为了解决的东西实际上也是两个,但是一定要注意,不到最后万不得已,不要用分库分表,因为这会对数据查询有极大限制。
- 数据量太大查询慢的问题。
这里面我们讲的「查询」其实 主要是事务中的查询和更新操作,因为 只读的查询可以通过缓存和主从分离来解决,这个我们在之前的「MySQL 如何应对高并发」的两节课中都讲过。那我们上节课也讲到过,解决查询慢,只要减少每次查询的数据总量就可以了,也就是说,分表就可以解决问题。 - 为了应对高并发的问题。
应对高并发的思想我们之前也说过,一个数据库实例撑不住,就把并发请求分散到多个实例中去,所以,解决高并发的问题是需要分库的。
那么分库实际上就是把表放到不同数据库上,所以分表才是基础,分表又分为垂直和水平两种:
- 垂直分表

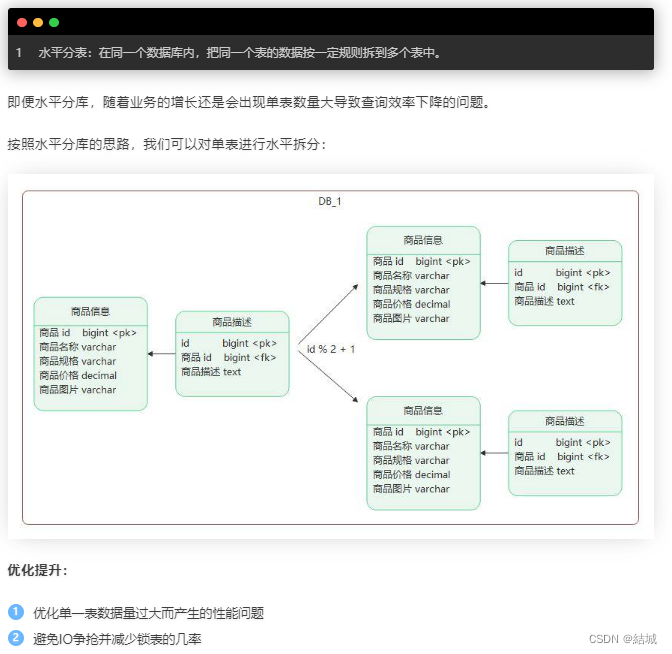
- 水平分表
但需要注意的是,假设是按照下面这种关键字%的方式,可能恰好大部分数据会被分到同一个表里,没起到分表作用。
所以要选好按照什么关键字分,比如按照用户id,那我要查我的订单时候,我并不知道我的订单具体信息被放到哪个分片了。
所以也可以根据时间分,但业务增长趋势初期不一定能预料到,可能后期业务爆炸增长。
也可以根据大小分,比如每200w就分一下,但这收到场景限制,会有一部分分表成为热点,其他的分表闲着。
一般来说,订单表都采用更均匀的哈希分片算法,取%就是一种简单的哈希算法。需要注意的一点是,哈希分片算法能够分得足够均匀的前提条件是,用户 ID 后几位数字必须是均匀分布的。
还有一种分片的方法:查表法。查表法其实就是没有分片算法,决定某个 Sharding Key 落在哪个分片上,全靠人为来分配,分配的结果记录在一张表里面。每次执行查询的时候,先去表里查一下要找的数据在哪个分片中。查表法的好处就是灵活,怎么分都可以,你用上面两种分片算法都没法分均匀的情况下,就可以用查表法,人为地来把数据分均匀了。查表法还有一个特好的地方是,它的分片是可以随时改变的。比如我发现某个分片已经是热点了,那我可以把这个分片再拆成几个分片,或者把这个分片的数据移到其他分片中去,然后修改一下分片映射表,就可以在线完成数据拆分了。
分库可以简单视为把分的表放到不同库里,不多赘述。但实际上分库会带来一些问题,需要我们考虑。

文章来源:https://blog.csdn.net/pige666/article/details/135612319
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构—二叉树的基础知识介绍和堆的实现(顺序表)】
- 【Golang】Json 无法表示 float64 类型的 NaN 以及 Inf 导致的 panic
- 怎么快速去除图片水印?这些快速去除的工具赶紧码住
- docker网络模式
- 购买cdn节点怎么接入服务器-速盾网络
- 钉钉考勤统计工时的方法
- 低功耗16位MCU:R7F100GLL3CFA、R7F100GLN2DLA、R7F100GLN3CFA、R7F100GLN2DFA是新一代RL78微控制器
- 8. 自定义分页
- 爬虫中,代理 IP 有哪些常见用途?
- 如何彻底卸载Edge