【LMM 004】LLaVA-RLHF:用事实增强的 RLHF 对齐大型多模态模型
论文标题:Aligning Large Multimodal Models with Factually Augmented RLHF
论文作者:Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
作者单位:UC Berkeley, CMU, UIUC, UW–Madison, UMass Amherst, Microsoft Research, MIT-IBM Watson AI Lab
论文原文:https://arxiv.org/abs/2309.14525
论文出处:–
论文被引:20(12/31/2023)
论文代码:https://github.com/llava-rlhf/LLaVA-RLHF,168 star
项目主页:https://llava-rlhf.github.io/
ABSTRACT
大型多模态模型(Large Multimodal Models,LMM)是跨模态建立的,两种模态之间的未对齐(unalignment)可能导致幻觉(hallucination),生成的文本输出没有上下文中的多模态信息作为基础。
- 为了解决多模态未对齐问题,我们将文本领域的人类反馈强化学习(Reinforcement Learning from Human Feedback,RLHF)应用到视觉语言对齐(vision-language alignment)任务中,要求人类标注者比较两个回答,并找出更有幻觉的那个,然后训练视觉语言模型,使模拟的人类奖励最大化。我们提出了一种名为 Factually Augmented RLHF 的对齐算法,该算法利用额外的事实信息(如图片描述和真实的多选选项)增强了奖励模型,从而缓解了 RLHF 中的 reward hacking 现象,并进一步提高了性能。
- 我们还利用以前可用的人类撰写的图像文本对增强了 GPT-4 生成的训练数据(用于视觉指令调优),以提高模型的综合能力。
- 为了在真实世界场景中评估所提出的方法,我们开发了一个新的评估基准 MMHAL-BENCH,特别关注对幻觉的惩罚。作为首个使用 RLHF 训练的 LMM,我们的方法在 LLaVA-Bench 数据集上取得了显著的改进,在纯文本 GPT-4 中的表现达到了 94%(而之前最好的方法只能达到 87%),在 MMHAL-BENCH 上比其他基准提高了 60%。
1 INTRODUCTION
大型语言模型(Large Language Models,LLMs)可以通过使用图像-文本对进行进一步的预训练或使用专门的视觉指令调优数据集进行微调来深入多模态领域,从而产生强大的大型多模态模型(LMMs)。然而,开发大型多模态模型面临着挑战,特别是多模态数据与纯文本数据集在数量和质量上的差距。LLaVA 模型是由预先训练好的视觉编码器和指令调优语言模型初始化而成的。该模型仅在 15 万个基于图像的合成对话中进行了训练,与纯文本模型利用了跨越 1800 个任务的超过 1 亿个示例相比要少得多。这种数据上的限制可能会导致视觉和语言模态之间的未对齐。因此,LMM 可能会产生幻觉输出,无法准确锚定(anchored)图像提供的上下文。
为了缓解用于 LMM 训练的高质量视觉指令调优数据稀缺所带来的挑战,我们引入了 LLaVA-RLHF,这是一种为改进多模态对齐而训练的视觉语言模型。我们的主要贡献之一是将人类反馈强化学习(RLHF)这一通用且可扩展的对齐范式应用于 LMM 的多模态对齐(RLHF是一种在基于文本的AI Agents中取得巨大成功的通用、可扩展的对齐范式)。通过收集人类偏好,重点是检测幻觉,并在强化学习中利用这些偏好对 LMM 进行微调。这种方法能以相对较低的注释成本改进多模态对齐,例如,用 3000 美元就能收集 10K 基于图像对话的人类偏好。据我们所知,这种方法是 RLHF 在多模态对齐方面的首次成功应用。
当前 RLHF 范式的一个潜在问题被称为奖励黑客(reward hacking),即从奖励模型中获得高分并不一定能改善人类的判断。为了防止奖励黑客,以前的工作建议反复收集新鲜的人类反馈,这往往成本高昂,而且不能有效利用现有的人类偏好数据。在这项工作中,我们提出了一种数据效率更高的替代方案,即尝试使奖励模型能够利用现有的人类标注数据和大型语言模型中的知识。
- 首先,我们通过使用分辨率更高的更好视觉编码器和更大的语言模型来提高奖励模型的一般能力。
- 其次,我们引入了一种名为事实增强 RLHF(Fact-RLHF)的新算法,如图 1 所示,该算法通过图像描述或真实的多选选项等附加信息来增强奖励信号,从而校准奖励信号。
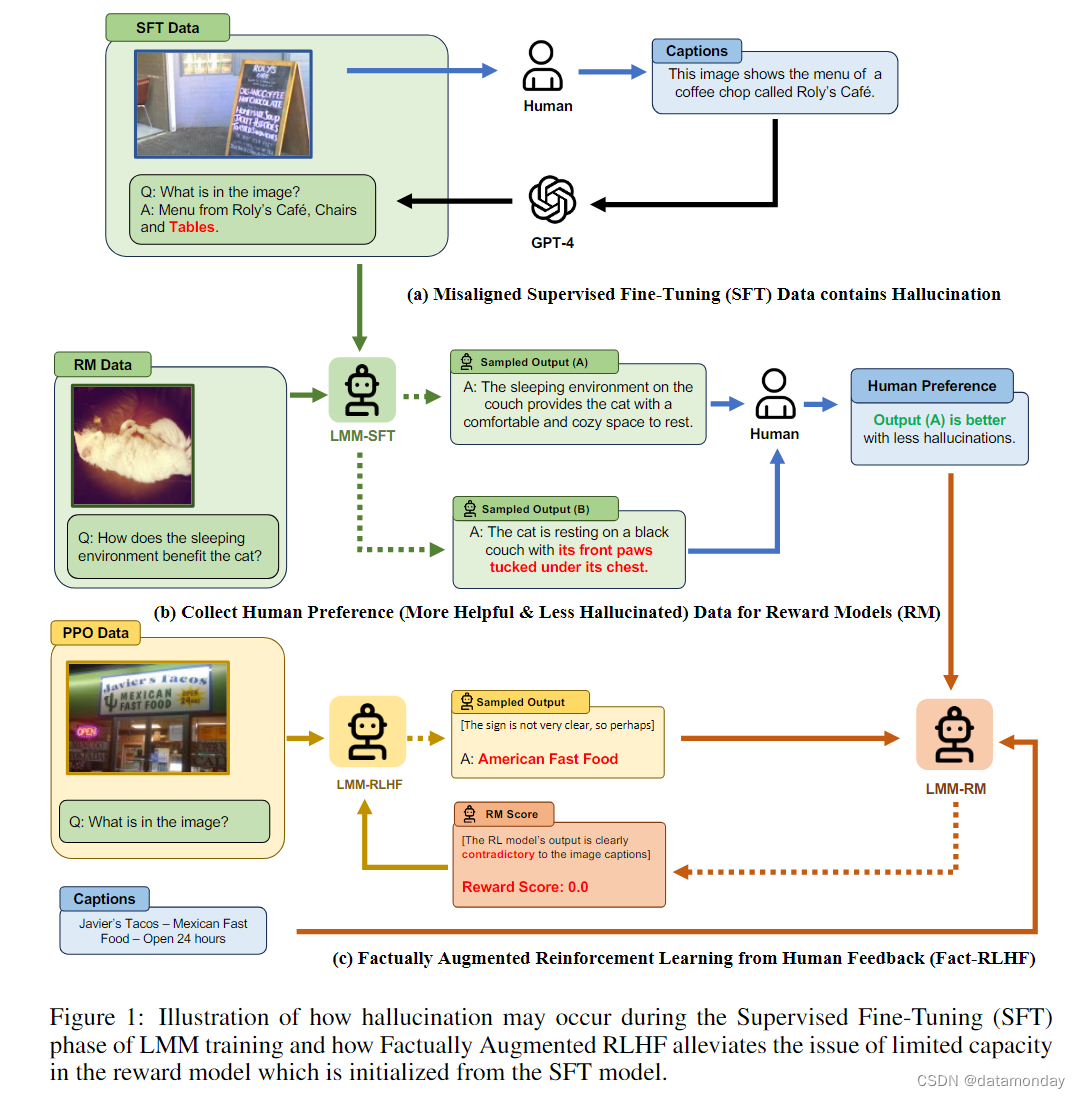
为了提高 LMM 在监督微调(Supervised Fine-Tuning,SFT)阶段的泛化能力,我们利用现有的高质量人类标注的对话格式多模态数据进一步增强了合成视觉指令调优数据。具体来说,我们将 VQA-v2 和 A-OKVQA 转换为多轮 QA 任务,将 Flickr30k 转换为 Spotting Captioning 任务,并基于新的混合数据训练 LLaVA-SFT+ 模型。
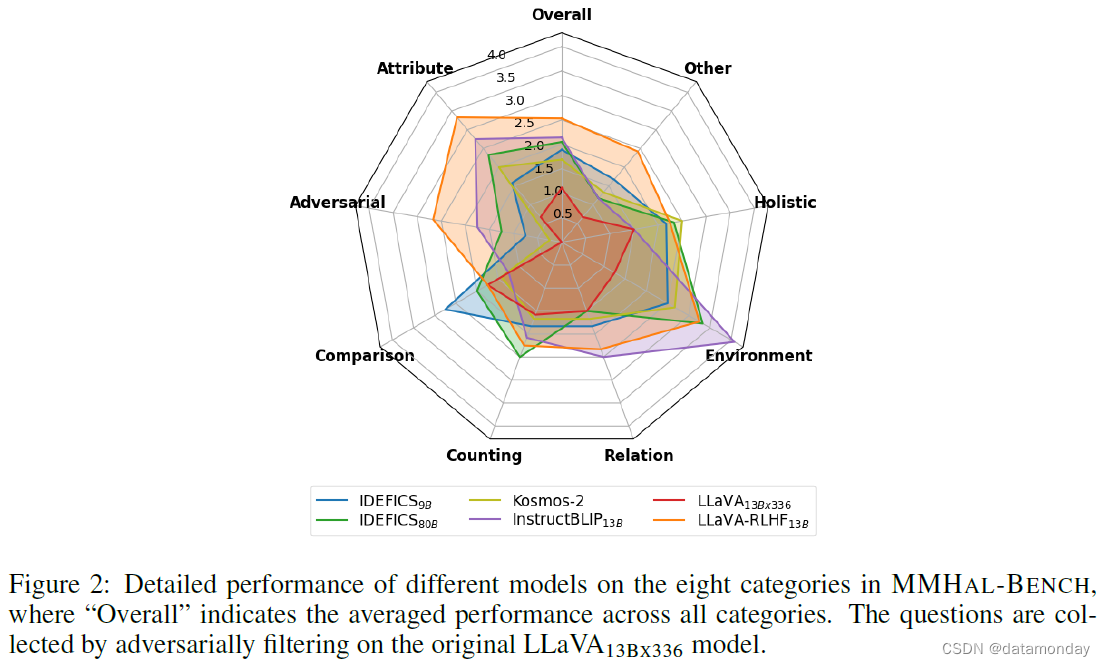
最后,我们将评估 LMM 在真实世界生成场景中的多模态对齐情况,特别强调对任何幻觉进行惩罚。我们创建了一组不同的基准问题,涵盖了 COCO 中的 12 个主要物体类别,并包括 8 种不同的任务类型,最终形成 MMHAL-BENCH。我们的评估结果表明,该基准数据集与人类的评估结果非常吻合,尤其是在对反幻觉(anti-hallucinations)进行分数调整后。在我们的实验评估中,作为第一个使用 RLHF 训练的 LMM,LLaVA-RLHF 取得了令人印象深刻的结果。我们观察到,LLaVA-Bench 的得分显著提高,达到 94%,MMHAL-BENCH 的得分提高了 60%,并为 LLaVA 建立了新的性能基准,MMBench 的得分达到 52.4%,POPE 的 F1 得分达到 82.7%。
2 METHOD
2.1 MULTIMODAL RLHF
从人类反馈中强化学习(RLHF)已成为一种强大且可扩展的策略,用于将大型语言模型(LLMs)与人类价值观相统一。在这项工作中,我们使用 RLHF 对齐 LMM。我们的多模态 RLHF 基本流程可概括为三个阶段:
1)多模态监督微调(Multimodal Supervised Fine-Tuning)
利用标记/词元级(token-level)监督,在指令遵循演示数据集上对视觉编码器和预训练的 LLM 进行联合微调,生成有监督微调(SFT)模型 π S F T π^{SFT} πSFT。
2)多模态偏好建模(Multimodal Preference Modeling)
在这一阶段,对奖励模型(也称偏好模型)进行训练,使其为更好的响应打出更高的分数。成对比较训练数据通常由人工标注。形式上,让汇总的偏好数据表示为 D R M = ( I , x , y 0 , y 1 , i ) D_{RM} = {(\mathcal{I}, x, y_0, y_1, i)} DRM?=(I,x,y0?,y1?,i),其中 I \mathcal{I} I 表示图像,x 表示提示(prompt), y 0 y_0 y0? 和 y 1 y_1 y1? 是两个相关的响应, i i i 表示首选响应的索引。奖励模型采用交叉熵损失函数:
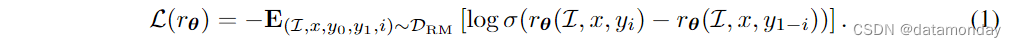
3)强化学习(Reinforcement Learning)
策略模型(policy model)通过多模态监督微调(SFT)初始化,其被训练以通过最大化奖励模型提供的奖励信号,为每个用户查询生成适当的响应。为了应对潜在的过度优化挑战,特别是奖励黑客,有时会应用从初始策略模型中得出的 per-token KL 惩罚。从形式上看,给定收集的图像和用户提示集 D R L = ( I , x ) D_{RL} = {(\mathcal{I}, x)} DRL?=(I,x) 以及固定的初始策略模型 π I N I T π^{INIT} πINIT 和 RL 优化模型 π φ R L π^{RL}_{φ} πφRL? ,全部优化损失可表述为:
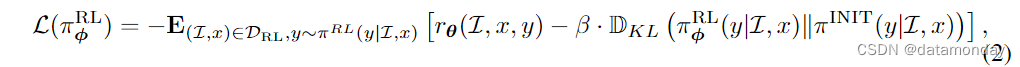
其中 β 是控制 KL 惩罚尺度的超参数。
2.2 AUGMENTING LLAVA WITH HIGH-QUALITY INSTRUCTION-TUNING
最近的研究表明,高质量的指令调优数据对于大型语言模型(LLMs)的对齐至关重要。我们发现这一点对于 LMM 来说变得更加突出。由于这些模型遍及广阔的文本和视觉领域,因此清晰的调优指令至关重要。正确对齐的数据可确保模型产生与上下文相关的输出,从而有效解决语言和视觉之间的gap。
例如,LLaVA 使用纯文本 GPT-4 合成了 150k 视觉指令数据,其中图像表示为边界框上的相关描述,以提示 GPT-4。虽然已经采用了仔细的过滤来提高质量,但管道偶尔也会生成视觉未对齐的指令数据,这些数据无法通过自动过滤脚本轻松去除,如表 1 所示。

在这项工作中,我们考虑利用从现有人类注释中获得的高质量指令调优数据来增强 LLaVA(98k 对话,其中 60k 对话用于偏好建模和 RL 训练)。具体来说,我们策划了三类视觉指令数据:
- VQA-v2 的 “是” 或 “否” 查询(83k)
- A-OKVQA 的多选题(16k)
- Flickr30k 的真实描述(23k)
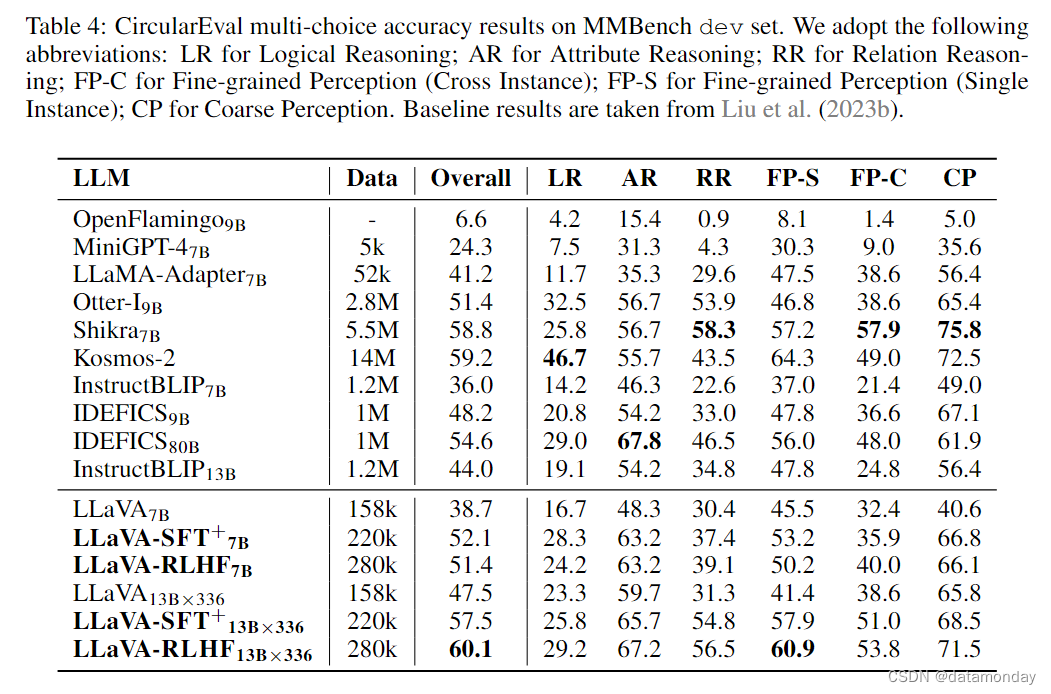
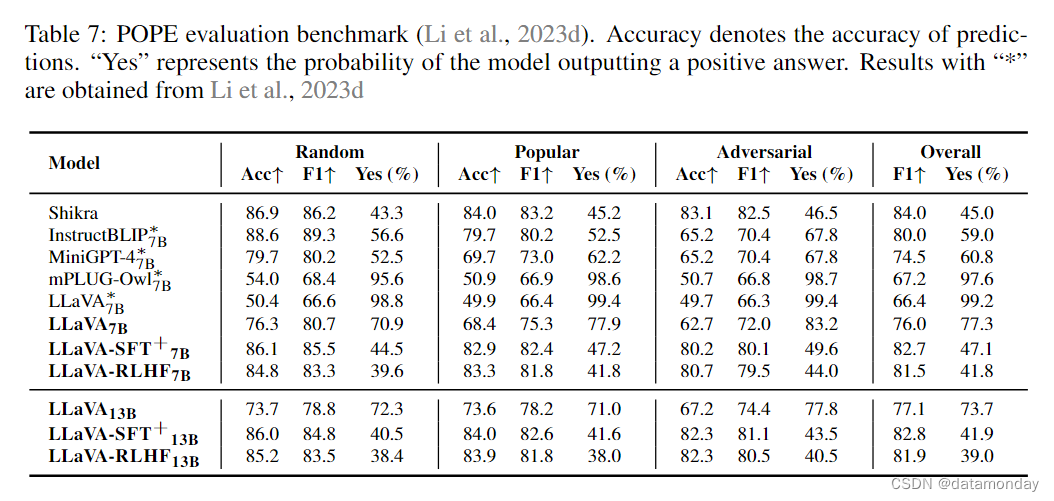
我们的分析表明,这些数据集的合并大大提高了 LMM 在基准测试中的能力。这些结果超过了在比我们大一个数量级的数据集上训练的模型,如表 7 和表 4 所示。有关每个数据集的影响,请参阅第 3.5 节。
2.3 HALLUCINATION-AWARE HUMAN PREFERENCE COLLECTION
最近的 RLHF 研究分别收集了有用性和无害性偏好,受此启发,在本研究中,我们决定区分仅仅是不太有用的回答和与图像不一致的回答(通常以多模态幻觉为特征)。为此,我们为众包工作者提供了表 2 所示的模板,以指导他们在比较两个给定回复时进行注释。通过当前的模板设计,我们的目标是促使众包工作者识别出模型回答中潜在的幻觉。

不过,我们的训练过程整合了一个单一的奖励模型,强调多模态一致性和整体帮助性。我们使用 SFT 模型和 0.7 的 temperature 对最后一个响应进行重新采样,从而在 10k 个保持不变的 LLaVA 数据上收集人类偏好。奖励模型由 SFT 模型初始化,以获得基本的多模态能力。
2.4 FACTUALLY AUGMENTED RLHF (FACT-RLHF)
我们在 50k 个保持不变的 LLaVA 对话中进行了多模态 RLHF,另外还从 A-OKVQA 中抽取了 12k 个多选问题,从 VQA-v2 中抽取了 10k 个是/否问题。由于担心 LLaVA 的合成多轮对话数据中存在幻觉,我们只使用每个对话中的第一个问题进行 RL 训练,从而避免了对话上下文中预先存在的幻觉。
Reward Hacking in RLHF
在初步的多模态 RLHF 实验中,我们观察到由于 SFT 模型内在的多模态未对齐,奖励模型很弱,有时无法有效检测 RL 模型响应中的幻觉。在文本领域,以前的工作建议反复收集 "新鲜的 "人类反馈。然而,这样做的成本可能相当高,而且不能有效利用现有的人类注释数据,也不能保证更多的偏好数据能显著提高奖励模型对多模态问题的判别能力。
Facutual Augmentation
为了增强奖励模型的能力,我们提出了事实增强 RLHF(Fact-RLHF),即奖励模型可以访问额外的真实的信息,如图片描述,以校准其判断。在最初的 RLHF 中,奖励模型只需要根据用户查询(即输入图像和提示)来判断响应的质量:

在事实增强 RLHF(Fact-RLHF)中,奖励模型对图像的文本描述有附加信息:

这可以防止策略模型产生一些明显与图片描述不符的幻觉时,奖励模型被策略模型黑客攻击。对于带有 COCO 图像的一般问题,我们将五个 COCO 标题串联起来作为额外的事实信息,而对于 A-OKVQA 问题,我们使用注释的理由作为事实信息。
除了在模型微调和推理过程中都会提供事实信息外,事实增强奖励模型的训练所依据的二分类偏好数据与普通奖励模型相同。
Symbolic Rewards: Correctness Penalty & Length Penalty
在我们的一些 RL 数据中,某些问题带有预先确定的基本答案。这包括 VQA-v2 中的二元选择(如 “是/否”)和 A-OKVQA 中的多选选项(如 “ABCD”)。这些注释也可视为额外的事实信息。因此,在 Fact-RLHF 算法中,我们进一步引入了符号奖励机制,对偏离这些基本事实选项的选择进行惩罚。
此外,我们观察到 RLHF 训练的模型通常会产生更多的冗长输出,Dubois et al(2023)也注意到了这一现象。虽然用户或基于 LLM 的自动评估系统可能喜欢这些冗长的输出,但它们往往会给 LMM 带来更多幻觉。在这项工作中,我们效仿 Sun et al(2023a)的做法,将响应长度(以token数量为单位)作为辅助惩罚因子。
3 EXPERIMENTS
3.1 NEURAL ARCHITECTURES
Base Model
我们采用与 LLaVA 相同的网络架构(Liu et al., 2023a)。我们的 LLM 基于 Vicuna(Touvron et al., 2023a;Chiang et al., 2023),并使用了预先训练好的 CLIP 视觉编码器 ViT-L/14(Radford et al., 2021)。我们在最后的 Transformer 层之前和之后都使用了网格特征(grid features)。为了将图像特征投射到词嵌入空间,我们采用了线性层。值得注意的是,我们利用了 LLaVA 线性投影矩阵的预训练检查点,在我们的研究中集中于多模态对齐的端到端微调阶段。对于 LLaVA-SFT±7b,我们使用了 Vicuna-V1.5-7b LLM 和 ViT-L/14,图像分辨率为 256 × 256。对于 LLaVA-SFT±13b,我们使用 Vicuna-V1.5-13b LLM 和 ViT-L/14,图像分辨率为 336 × 336。
RL Models: Reward, Policy, and Value
奖励模型的结构与基本的 LLaVA 模型相同,只是最后一个词元的嵌入输出被线性投影为一个标量值,以表示整个反应的奖励。根据 Dubois et al(2023)的研究,我们从奖励模型初始化价值模型。因此,在用基于 LLavA-13B 的奖励模型训练基于 LLaVA-7B 的策略模型时,价值模型也是 13B 大小。为了将所有模型(i.e., police, reward, value, original policy)整合到一个 GPU 中,我们在 RLHF 的所有微调过程中都采用了 LoRA(Hu et al., 2021)。我们使用带有 KL 惩罚的近端策略优化(PPO;Schulman et al., 2017)来进行 RL 训练。无需进一步说明,LLaVARLHF-7b 和 LLaVA-RLHF-13b 都是用 LLaVA-SFT±13b 初始化奖励模型训练的。更多详情请见附录 F。
3.2 MMHAL-BENCH DATA COLLECTION
为了量化和评估 LMM 响应中的幻觉,我们创建了一个新的基准 MMHAL-BENCH。MMHAL-BENCH 与之前的 VLM 基准有两个主要区别:
- 1)专业性: Liu et al(2023a;b);Li et al(2023d)从一般意义上(如有用性、相关性)评估响应质量,而我们则专注于确定LMM响应中是否存在幻觉。我们的评估指标就是直接根据这一主要标准制定的。
-
- 实用性: 之前的一些 LMM 基准 Li et al(2023d);Rohrbach et al(2018)也对幻觉进行了研究,但他们将问题限定为是/否问题,我们发现其结果有时可能与 LMM 生成的详细描述不一致。我们在MMHAL-BENCH中没有过度简化问题,而是采用了一般的、现实的和开放式的问题,这样可以更好地反映实际用户与LMM交互中的反应质量。
在 MMHAL-BENCH 中,我们精心设计了 96 对图像问题,涉及 8 个问题类别 × 12 个物体主题。更具体地说,我们观察到 LMM 在回答某些类型的问题时经常会对图像内容做出错误的判断,因此我们根据这些类型设计了问题:
- 物体属性: LMM 错误地描述了单个物体的视觉属性,如颜色和形状。
- 对抗物体: LMM 在回答问题时会涉及图像中不存在的东西,而不是指出找不到所指的物体。
- 比较: LMM 错误地比较多个物体的属性。
- 计数: LMM 无法计算指定对象的数量。
- 空间关系: LMM 无法理解答案中多个对象之间的空间关系。
- 环境: LMM 对给定图像的环境做出错误推断。
- 整体描述: LMM 在对整个图像进行全面而详细的描述时,对给定图像中的内容作出错误的断言。
- 其他: LMM 无法识别文字或图标,或根据观察到的视觉信息进行错误推理。
我们以对抗的方式创建和过滤问题。更具体地说,我们设计了图像问题对,以确保原始 LLaVA-13BX336 模型在回答这些问题时产生幻觉。虽然这些问题最初是根据 LLaVA-13BX336 的行为定制的,但我们观察到它们也具有更广泛的适用性,可导致其他 LMM 也产生幻觉。
为了避免数据泄露或对 LMM 在训练过程中观察到的数据进行评估,我们从 OpenImages(Kuznetsova et al., 2020)的验证集和测试集中选择图片,并设计了所有全新的问题。我们的图像-问题对涵盖了 COCO(Lin et al., 2014)中的 12 个常见物体元类别,包括:“accessory”, “animal”, “appliance”, “electronic”, “food”, “furniture”, “indoor”, “kitchen”, “outdoor”, “person”, “sports”, and “vehicle”。
在对 MMHAL-BENCH 上的 LMM 进行评估时,我们采用了功能强大的 GPT-4 模型(OpenAI,2023)来分析和评价回答。目前,公开的 GPT-4 API 仅支持文本输入,因此无法直接根据图像内容进行判断。因此,为了帮助 GPT-4 进行评估,除了问题和 LMM 响应对之外,我们还在提示中提供了图像内容的类别名称和人类生成的标准答案。因此,GPT-4 可以通过将 LMM 回答与图像内容和人工生成的完整答案进行比较,来确定 LMM 回答中是否存在幻觉。当从 MMHAL-BENCH 中获得足够的信息时,GPT-4 可以做出与人类判断一致的合理决定。例如,在判断 LLaVA-13BX336 和 IDEFICS80B 的回答是否存在幻觉时,GPT-4 与人类判断一致的比例高达 94%。有关我们用于 MMHAL-BENCH 评估的图像-问题对示例和 GPT-4 提示,请参阅附录。
3.3 RESULTS
我们使用 LLaVA-Bench(Liu et al., 2023a)和我们的 MMHAL-BENCH 作为主要评估指标,因为它们与人类偏好高度一致。此外,我们还在广泛认可的大型多模态模型基准上进行了测试。我们采用了 MMBench(Liu et al., 2023b),它是一个多模态基准,提供了一个客观的评估框架,包含 2,974 道多选题,横跨 20 个能力维度。该基准利用 ChatGPT 将模型预测与预期选择并列,确保对不同教学能力的 VLM 进行公平评估。此外,我们还采用了基于投票的查询技术 POPE(Li et al., 2023d),对大型多模态模型的物体感知倾向进行评估。
高质量的 SFT 数据对能力基准至关重要。通过深入研究能力基准(即 MMBench 和 POPE)的具体表现,我们在表 4 和表 7 中观察到高质量指令调优数据(LLaVA-SFT+)对能力的显著提升。其中,LLaVA-SFT+7B 模型在 MMBench 和 POPE 上分别取得了 52.1% 和 82.7% 的 F1 分数,与原始 LLaVA 相比分别提高了 13.4% 和 6.7%。不过,值得注意的是,LLaVA-SFT+ 确实落后于 Kosmos 和 Shikra 等型号。尽管如此,LLaVA-SFT+ 在采样效率方面仍有突出表现,它只使用了 280k 微调数据,仅为上述模型的 5%。此外,这种提升并不仅限于一种模型尺寸。当扩大规模时,LLaVA-SFT+13BX336 取得了值得称赞的结果,在 MMBench 上达到了 57.5%,在 POPE 上达到了 82.9%。相比之下,RLHF 对能力基准的影响则喜忧参半。LLaVA-RLHF 在 7b 级出现了微妙的退化,但 13b 级 LLaVA-RLHF 在 MMBench 上比 LLaVA-SFT+ 提高了 3%。这一现象类似于之前工作中观察到的对齐税(Bai et al., 2022a)。尽管如此,根据我们目前对 LLaVARLHF 的经验缩放规律,我们相信 RLHF 对齐不会损害 LMMs 对更大规模模型的一般能力。
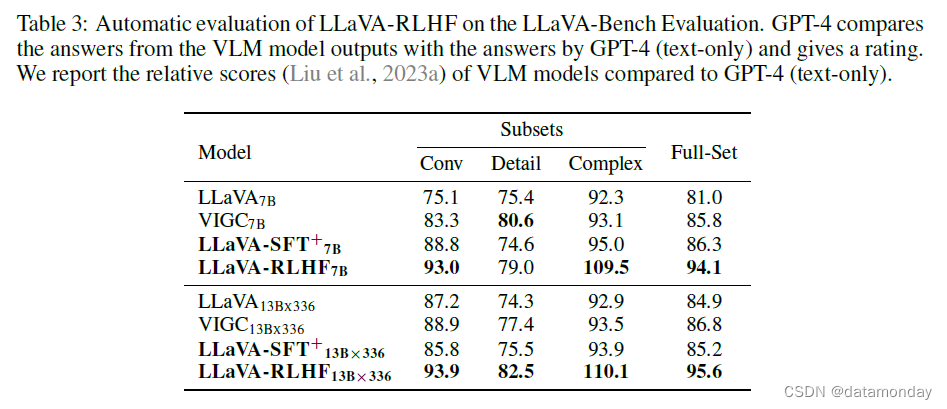
RLHF 进一步提高了人类对齐基准。从另一个角度看,尽管高质量的指令数据在能力评估方面有很大的提高,但在人类对齐基准(包括 LLaVA-Bench 和 MMHAL-BENCH)方面并没有太大的改进,这在最近的 LLM 研究中也很明显(Wang et al., 2023)。LLaVA-RLHF 在与人类价值对齐方面有显著改进。它在 MMHAL-BENCH 上的得分分别为 2.05(7b)和 2.53(13b),在 LLaVA-Bench 上将 LLaVA-SFT+ 提高了 10%以上。我们还在表 1 中列出了定性示例,表明 LLaVA-RLHF 能产生更可靠、更有用的输出结果。
3.4 ABLATION ANALYSIS
我们对 LlaVA7B 进行消融研究,并在上述四个基准上进行评估。
3.5 ABLATION ON HIGH-QUALITY INSTRUCTION-TUNING DATA
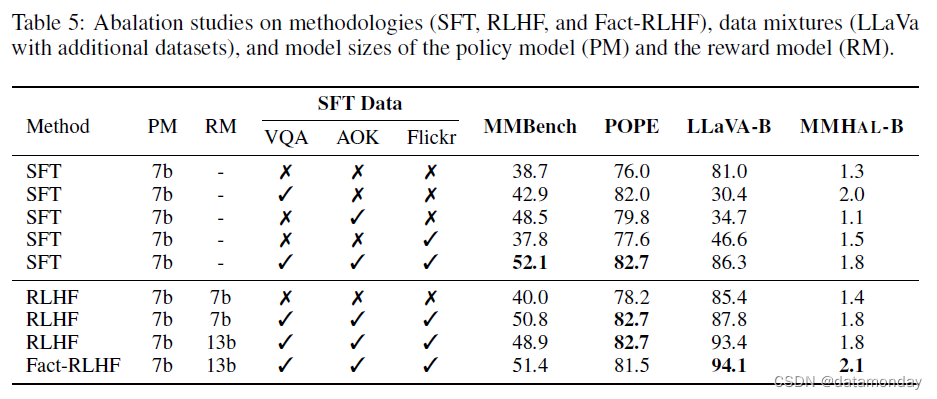
在表 5 中,我们评估了各个教学调整数据集的影响。为简单起见,我们没有调整混合率,而是将其留待今后研究时考虑。我们的研究结果表明,A-OKVQA(Schwenk et al., 2022)对性能提升的贡献很大,在 MMBench 上提升了 9.8%,在 POPE 上提升了 3.8%。相比之下,VQA-v2(Goyal et al., 2017a)对 POPE 的影响尤为明显,它使 POPE 的性能提高了 6%,而对 MMBench 的影响则微乎其微。这种差异可能归因于 VQA 中重叠的 "是/否 "格式和 AOKVQA 的多选结构。Flickr30k 显著提高了 LLaVA-Bench 和 MMHAL-BENCH 的性能–这可能是任务固有的基础性质造成的。此外,将这三个数据集合并后,在各种能力基准中的性能都得到了复合提升。
3.6 ABLATION ON FACT-AUGMENTED RLHF
表 5 比较了事实增强 RLHF(Fact-RLHF)和标准 RLHF 的性能。我们的研究结果表明,虽然传统 RLHF 在 LLaVABench 上的表现有所改善,但在 MMHAL-BENCH 上的表现却不尽如人意。这可能是由于在 PPO 期间,模型倾向于操纵原始 RLHF 奖励模型,产生更长的反应,而不是更不容易产生幻觉的反应。另一方面,我们的 Fact-RLHF 在 LLaVA-Bench 和 MMHAL-BENCH 上都有增强。这表明,Fact-RLHF 不仅更符合人类的偏好,而且还能有效减少幻觉输出。
3.7 DATA FILTERING V.S. RLHF
在初步测试中,我们使用 Fact-RLHF 奖励模型分别过滤掉了 70%、50% 和 30% 的 LLaVA 数据。随后,我们在这些过滤后的数据上对 LLaVA 模型进行了微调,结果在 LLaVA-Bench 上的得分分别为 81.2、81.5 和 81.8。但是,在 MMHAL-BENCH、POPE 和 MMBench 上的性能基本保持不变。我们认为这种停滞可归因于两个因素:没有负反馈机制阻止模型在其输出中识别幻觉,以及我们的Fact-RLHF奖励模型的潜在局限性,尤其是与之前成功研究中的高容量Oracle模型相比(Touvronet al., 2023b)。
4 RELATED WORK
Large Multimodal Models
最近在大型语言模型(LLMs)方面取得了成功,如
- GPTs(Brown et al., 2020;OpenAI,2023)
- PaLM(Chowdhery et al., 2022;Anil et al., 2023)
- BLOOM(Scao et al., 2022;Muennighoff et al., 2022)
- LLaMA(Touvron et al., 2023a;b)
- Alpaca(Taori et al., 2023)
- Vicuna(Chiang et al., 2023)
- Flamingo(Alayrac et al)率先将 LLMs 整合到视觉语言预训练中,利用门控交叉注意密集块来适应视觉特征;其开源变体是 OpenFlamingo(Awadalla et al., 2023)和 IDEFICS(Laurenc ?on et al., 2023)。
- PaLI(Chen et al., 2022;2023b)研究了各种任务中 V&L 组件的缩放因子。
- PaLM-E(Driess et al., 2023)进一步将 LMM 扩展到具身领域。
- BLIP-2(Liet al., 2023年c)引入了查询Transformer(Q-former),以弥补图像和语言编码器之间的差距,InstructBLIP(Daiet al., 2023年)对其进行了进一步改进。
- Otter(Liet al., 2023b;a)主要致力于增强OpenFlamingo的指令跟随能力。
- MiniGPT-4(Zhuet al., 2023年)认为GPT4的优势在于复杂的LLM,并建议使用单个项目层来微调视觉和语言模型。
- mPLUG-Owl (Ye et al., 2023)提供了一种新方法:首先对齐视觉特征,然后使用 LoRA(Hu et al., 2021)对语言模型进行微调。
- 最近,QWen-VL(Bai et al., 2023)将 LMM 的预训练扩展到 1.4B 数据,并在各种基准测试中取得了令人印象深刻的结果。
- 其中,LLaVA(Liu et al., 2023a;Lu et al., 2023)通过利用 GPT4(OpenAI,2023)生成类似于文本指令的视觉语言调优数据集,开创了 LMM 工作(Wei et al、 2021;Chung et al., 2022;Longpre et al., 2023;Sanh et al., 2021;Mukherjee et al., 2023;Taori et al., 2023;K ?opf et al., 2023)。
- 然而,由于这些生成数据集的句法性质,图像和文本模态之间的未对齐非常普遍。我们的研究首次通过 RLHF 解决了这种未对齐问题。
Hallucination
在 LLM 出现之前,NLP 界主要将 “幻觉” 定义为生成无意义的内容或偏离其来源的内容(Ji et al., 2023)。正如(Zhang et al., 2023)所概述的,多模态 LLM 的引入将这一定义扩展为
- 1)输入冲突幻觉,偏离用户提供的输入,例如机器翻译(Lee et al., 2018;Zhou et al., 2020);
- 2)上下文冲突幻觉,输出与 LLM 之前生成的信息相矛盾(Shi et al., 2023);
- 3)事实冲突幻觉,内容与既定知识不一致(Lin et al., 2021)。在 LMM 领域,“物体幻觉” 是有据可查的(Rohrbach et al., 2018;MacLeod et al., 2017;Li et al., 2023d;Biten et al., 2022),指的是模型产生的描述或说明包括与目标图像不匹配或缺少的物体。我们在此基础上进行了扩展,涵盖了任何 LMM 生成的不忠于图像方面的描述,包括关系、属性、环境等。因此,我们提出了 MMHAL-BENCH,旨在全面准确地识别和测量 LMM 中的幻觉。
5 DISCUSSIONS & LIMITATIONS
在大型语言模型(LLM)和大型多模态模型(LMM)中都能观察到幻觉现象。潜在的原因有两个方面。
-
首先,导致这一问题的一个突出因素是当前 LMM 的指令调优数据质量较低,因为它们通常是由 GPT-4 等更强大的 LLM 合成的。我们希望我们提出的高质量视觉指令调优数据以及未来手动整理高质量视觉指令调优数据的努力能够缓解这一问题。
-
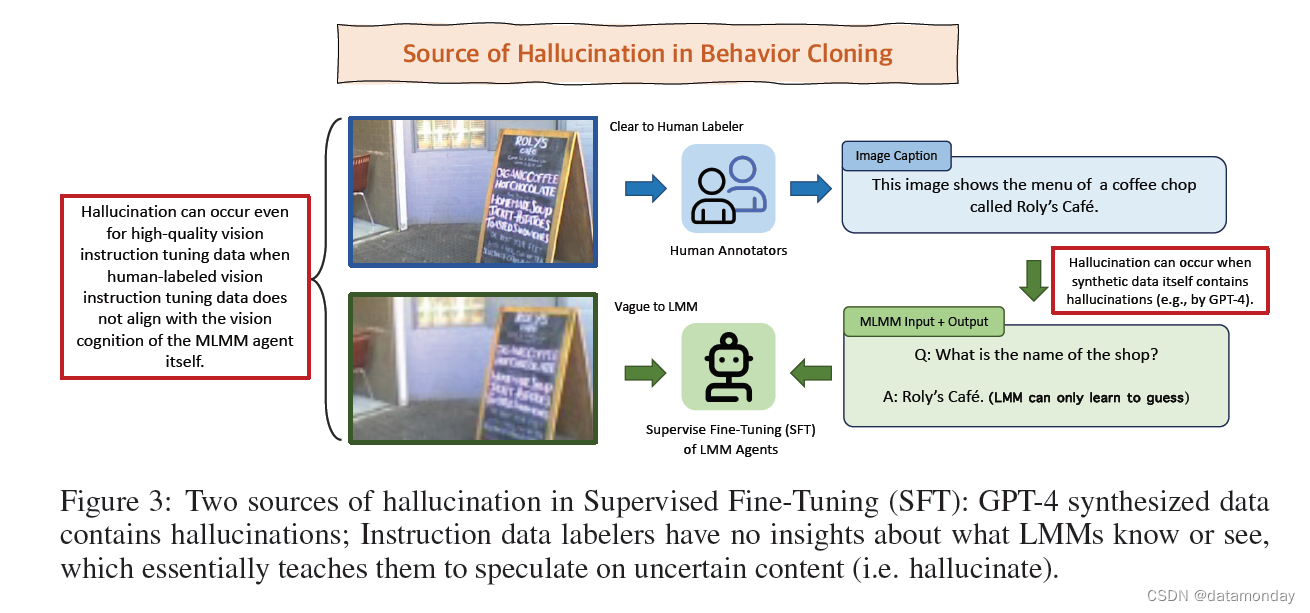
其次,在指令调优的 LMM 中采用行为克隆训练是另一个根本原因(Schulman,2023)。由于指令数据标注者缺乏对 LMM 对图像的视觉感知的洞察力,这种训练无意中会使 LMM 对不确定的内容进行推测。为了规避这一缺陷,实施基于强化学习的训练提供了一条大有可为的途径,引导模型更有效地表达不确定性(Lin et al., 2022;Kadavath et al., 2022)。我们的工作展示了在这一方向上的开创性努力。图 3 展示了当前 LLM 行为克隆训练中幻觉的两个来源。
然而,虽然 LLaVA-RLHF 增强了人类对齐能力,减少了幻觉,鼓励了真实性和校准,但应用 RLHF 可能会无意中降低小型 LMM 的性能。
- 如何在不影响 LMM 和 LLM 性能的情况下平衡对齐和增强功能,仍然是一个尚未解决的难题。
- 此外,虽然我们已经在 LLaVA 中用顶级指令数据证明了线性投影的有效使用,但确定最佳混合并将其扩展到更大的模型仍然是一个复杂的问题。
- 我们的研究主要深入到 VLM 的微调阶段,其他模态和预训练期间的未对齐问题仍有待探索。
最后,虽然 MMHAL-BENCH 强调以减少幻觉为目的对 LMM 进行评估,但值得注意的是,简短或回避性的回答会无意中在 MMHAL-BENCH 上获得高分。这凸显了诚实与乐于助人之间的内在权衡(Bai et al., 2022a)。因此,为了更全面地评估与人类偏好的一致性,我们主张同时使用 MMHAL-BENCH 和 LLaVA-Bench 对未来的 LMM 进行评估。
6 CONCLUSION
我们提出了几种策略来解决多模态未对齐问题,尤其是视觉语言模型(VLM),因为这些模型生成的文本往往与相关图像不一致。
- 首先,我们利用现有人类撰写的图像-文本对,丰富了 LLaVA 生成的 GPT-4 视觉指令调优数据。
- 接下来,我们采用文本领域的人类反馈强化学习(RLHF)算法来弥合视觉与语言之间的差距,由人类评估者来辨别和标记更多的幻觉输出。我们对 VLM 进行训练,以根据模拟的人类偏好进行优化。
- 此外,我们还引入了事实增强 RLHF,利用额外的事实信息(如图片说明)来增强奖励模型,抵御 RLHF 中的奖励黑客行为,并提高模型性能。
- 为了切实评估对现实世界的影响,我们设计了 MMHAL-BENCH,这是一个针对幻觉惩罚的评估基准。
- LLaVA-RLHF 作为首个使用 RLHF 训练的 VLM,在各种基准测试中都表现出了显著的性能提升。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- element plus 可选择树形组件(el-tree) 怎样一键展开/收起?实现方法详解
- 『 Linux 』进程地址空间概念
- python-日志模块以及实际使用设计
- 画颜色圆圈icon
- GitHub 一周热点汇总 第4期 (2024/01/01-01/06)
- 【数模百科】一文讲清楚主成分分析PCA算法(附python代码)
- jmeter的安装与目录介绍
- shell 如何调用多个脚本
- 若依如何集成websocket实现实时通信?
- 告别复杂排版:Markdown语法指南