Segment Anything:SAM系列模型总结
发布时间:2024年01月19日

Segment Anything | Meta AI https://segment-anything.com/
https://segment-anything.com/
SAM
https://arxiv.org/pdf/2304.02643.pdf
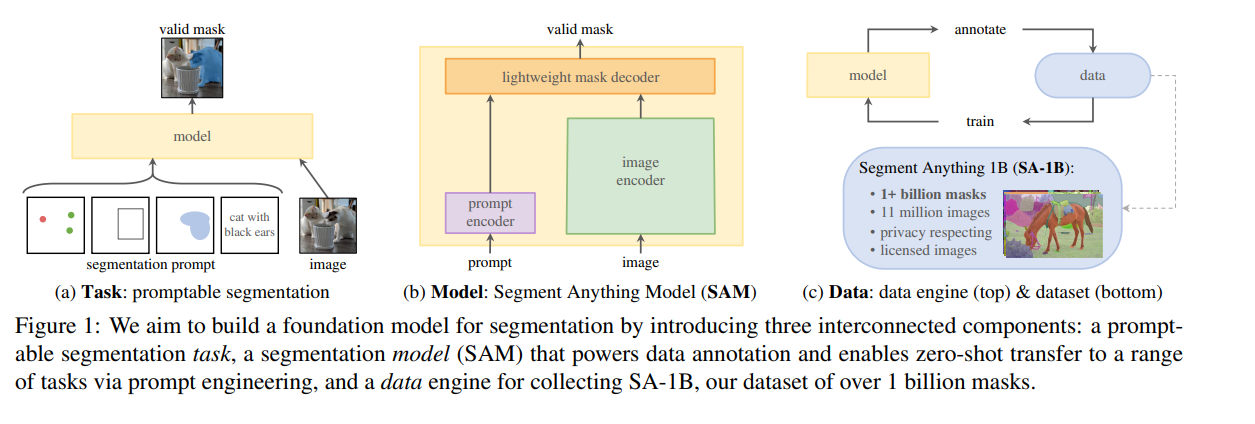
- 新的图像分割任务:这样的任务需要实现零样本泛化。
- 新的模型:Segment Anthing Model。目前分为vit_b,vit_l,vit_h
- 新的数据集:SA-1B。其中包括10亿个掩码和1100万张图像
?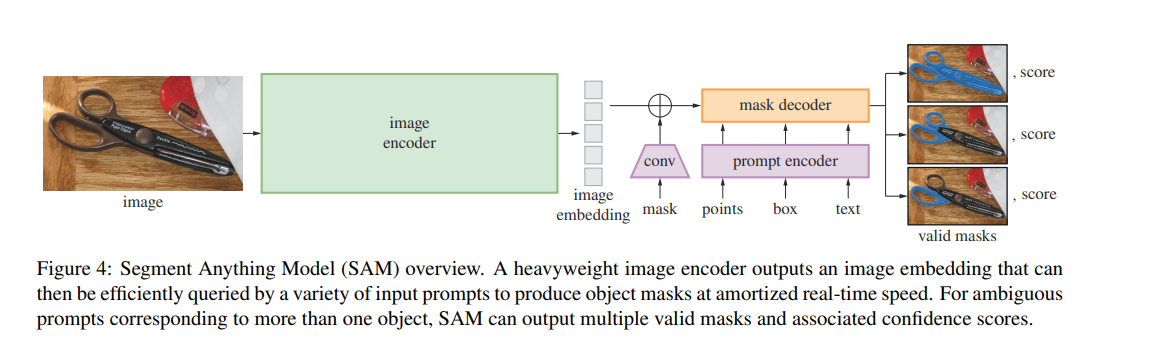
图像编码器?作者使用经过MAE预训练的Vision Transformer (ViT) ,并对其进行微调以处理高分辨率输入 。图像编码器在每张图像上运行一次,并可以在对模型进行提示之前应用。?
提示编码器?作者考虑两种类型的提示:稀疏提示(点、框、文本)和密集提示(掩码)。使用位置编码表示点和框,与每种提示类型的学习嵌入相加,而对于自由文本,则使用来自CLIP的现成文本编码器。密集提示(即掩码)使用卷积进行嵌入,并与图像嵌入进行逐元素求和。
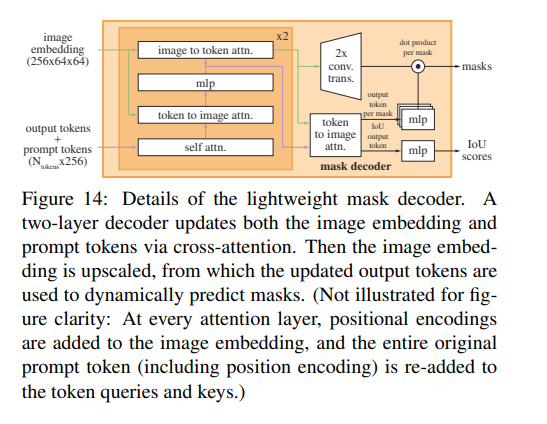
掩码解码器?掩码解码器高效地将图像嵌入、提示嵌入和输出标记映射到一个掩码上。这种设计受到《基于Trasformers的端到端目标检测》和Maskformer的启发,使用了一个修改的Transformer解码器block,后跟一个动态掩码预测头。修改后的解码器block在两个方向(提示到图像嵌入和图像嵌入到提示)上使用自注意力和交叉注意力来更新所有嵌入。在运行两个Block后,对图像嵌入进行上采样,并通过MLP层将输出标记映射到一个动态线性分类器(该分类器用于计算每个图像位置的掩码前景概率)。
相关解读链接:
【Paper日记】Segment Anything - 知乎?
EfficientSAM
MobileSAM
MobileM-v2
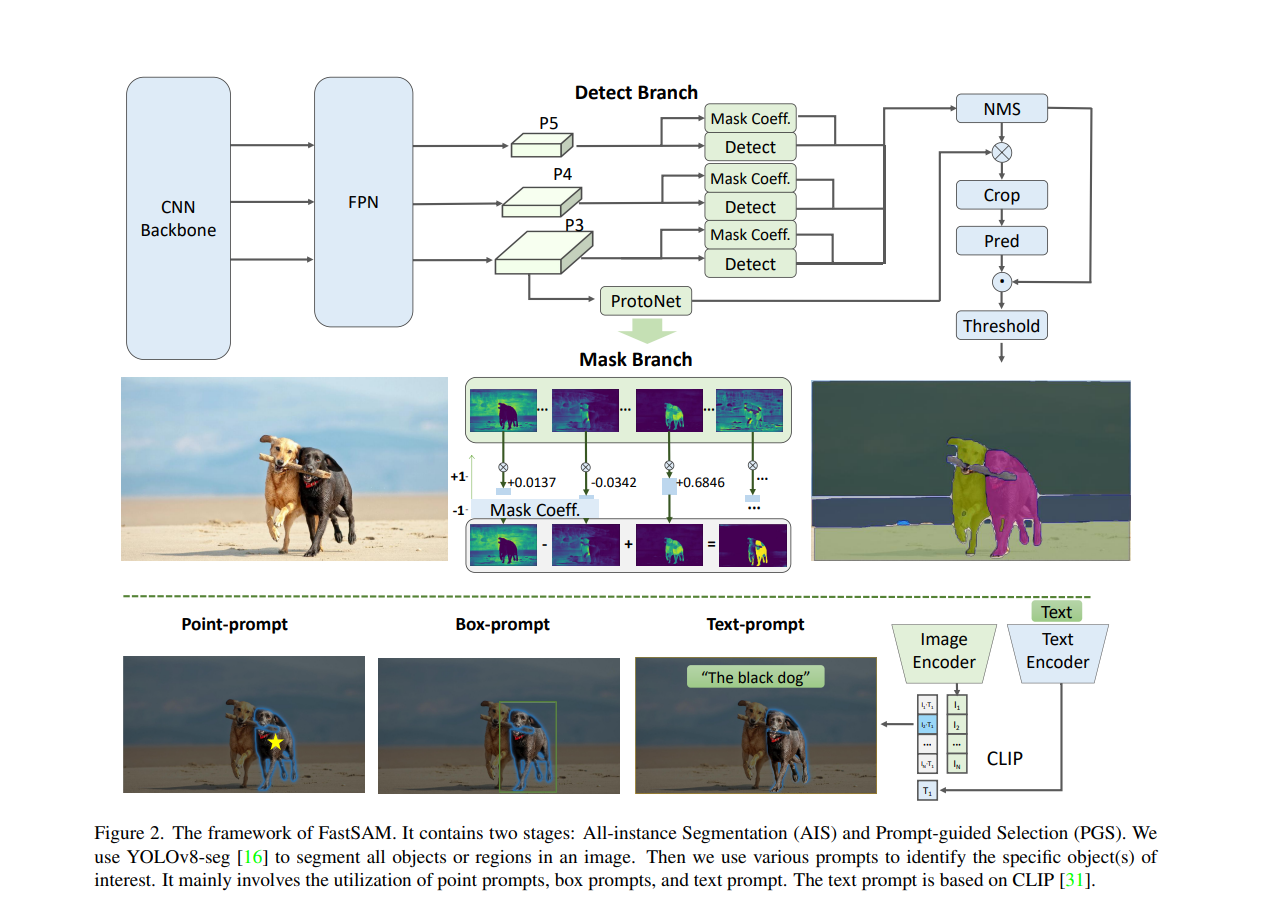
FastSAM
文章来源:https://blog.csdn.net/TYUT_xiaoming/article/details/135689602
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!