FastSAM 分割一切 速度可以比 SAM 快 50 倍
一、FastSAM
在自然语言处理领域有 ChatGPT 通用大语言模型系列,但是在图像领域好像一直没有通用领域模型,但MetaAI 提出能够 分割一切 的视觉基础大模型 SAM 可以做到很好的分割效果,并且不限于场景、不限于目标,为探索视觉大模型提供了一个新的方向,可以说是视觉领域通用大模型。而 FastSAM 为该任务提供了一套实时的解决方案,进一步推动了分割一切模型的实际应用和发展。
FastSAM 基于YOLOv8-seg,是一个配备了实例分割分支的对象检测器,它利用了YOLACT 方法。作者还采用了由SAM发布的广泛的SA-1B数据集。通过直接在仅2%(1/50)的SA-1B数据集上训练这个CNN检测器,它实现了与SAM相当的性能,但大大减少了计算和资源需求,从而实现了实时应用。作者还将其应用于多个下游分割任务,以显示其泛化性能。在MS COCO的对象检测任务上,在AR1000上实现了63.7,比32×32点提示输入的SAM高1.2分,在NVIDIA RTX 3090上运行速度快50倍。

FastSAM 同样实现了 SAM 的各种提示来分割感兴趣的特定对象。包括点提示、框提示和文本提示,通过这种提示的方式进一步促进了通用领域模型的应用:

- 论文地址:https://arxiv.org/pdf/2306.12156.pdf
- 代码地址:https://github.com/CASIA-IVA-Lab/FastSAM
- web demo:https://huggingface.co/spaces/An-619/FastSAM
FastSAM VS SAM
运行速度:

内存使用:

更多介绍,大家可以关注官方论文和 GitHub。
二、FastSAM 使用
拉取官方代码:
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
下载相关依赖:
pip install --trusted-host mirrors.tuna.tsinghua.edu.cn -r requirements.txt -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple/
还需要 openai-clip 依赖:
pip install openai-clip==1.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
下载 FastSAM 模型权重,其中 FastSAM_S 是轻量级的实现,模型更小,运算速度更快:
FastSAM_X : https://drive.google.com/file/d/1m1sjY4ihXBU1fZXdQ-Xdj-mDltW-2Rqv/view
FastSAM_S: https://drive.google.com/file/d/10XmSj6mmpmRb8NhXbtiuO9cTTBwR_9SV/view
将下载的模型放到项目的weights目录下:

使用下面官方图像进行测试:

1. 分割一切:
FastSAM 会将一切他认为可以分割的东西进行分割
from fastsam import FastSAM, FastSAMPrompt
import matplotlib.pyplot as plt
def main():
# 加载模型
model = FastSAM('./weights/FastSAM_X.pt')
# 图像地址
IMAGE_PATH = './images/dogs.jpg'
# 指定设备
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device="'cpu'", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
output_img= prompt_process.plot_to_result(annotations=ann)
plt.imshow(output_img)
plt.show()
if __name__ == '__main__':
main()
输出效果:

2. bbox prompts
根据给定一个左上角和一下右下角所形成一个矩形框,对该框中的目标进行分割:
例如:框出黑色狗的区域
from fastsam import FastSAM, FastSAMPrompt
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def main():
# 加载模型
model = FastSAM('./weights/FastSAM_X.pt')
# 图像地址
IMAGE_PATH = './images/dogs.jpg'
# 指定设备
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device="'cpu'", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9, )
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# 目标框
bbox = [578, 230, 776, 589]
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bboxes=[bbox])
output_img = prompt_process.plot_to_result(annotations=ann)
fig, ax = plt.subplots()
ax.imshow(output_img)
rectangle = patches.Rectangle((bbox[0],bbox[1]), (bbox[2]-bbox[0]), (bbox[3]-bbox[1]), linewidth=1, edgecolor='b', facecolor='none')
ax.add_patch(rectangle)
plt.show()
if __name__ == '__main__':
main()
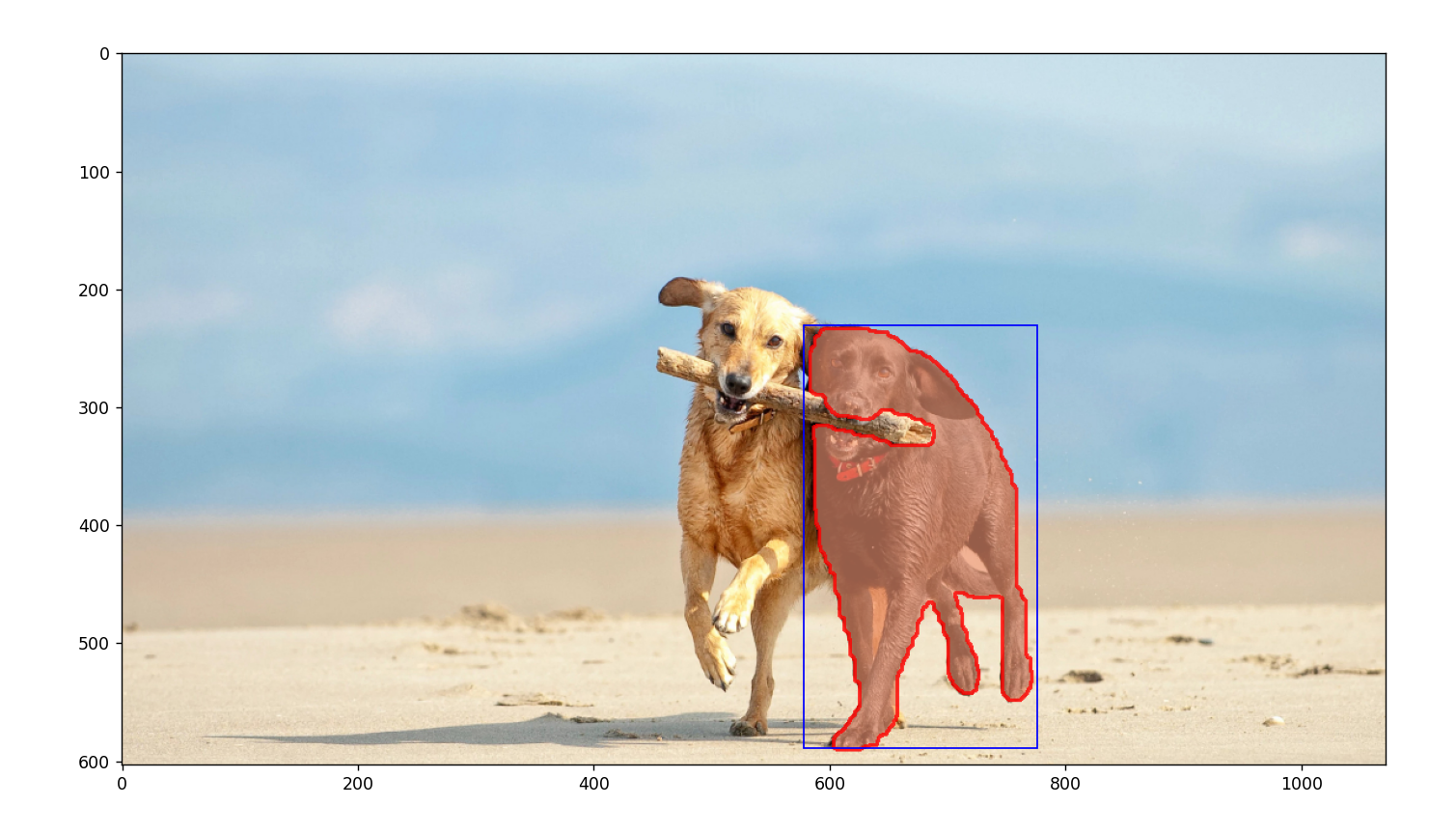
3. Point prompt
根据给定目标区域中某个点的形式分割出该目标。
例如:给出黑色狗身上的点
from fastsam import FastSAM, FastSAMPrompt
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def main():
# 加载模型
model = FastSAM('./weights/FastSAM_X.pt')
# 图像地址
IMAGE_PATH = './images/dogs.jpg'
# 指定设备
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device="'cpu'", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9, )
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
point = [661, 380]
pointlabel = 1
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[point], pointlabel=[pointlabel])
output_img = prompt_process.plot_to_result(annotations=ann)
fig, ax = plt.subplots()
ax.imshow(output_img)
ax.scatter(point[0], point[1], color='r', marker='o', label='Points')
plt.show()
if __name__ == '__main__':
main()

4. Text prompt
根据文本提示的方式分割出目标,目前仅限英语提示:
例如:分割出黑色的狗:the black dog
from fastsam import FastSAM, FastSAMPrompt
import matplotlib.pyplot as plt
def main():
# 加载模型
model = FastSAM('./weights/FastSAM_X.pt')
# 图像地址
IMAGE_PATH = './images/dogs.jpg'
# 指定设备
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device="'cpu'", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# text prompt
ann = prompt_process.text_prompt(text='the black dog')
output_img = prompt_process.plot_to_result(annotations=ann)
plt.imshow(output_img)
plt.show()
if __name__ == '__main__':
main()

三、结合目标检测进行实例分割
以目标检测模型的 bboxs 作为提示给到 FastSAM 分割其中的目标:
import os
import torch
from torchvision.models.detection import fasterrcnn_resnet50_fpn_v2
from torchvision.transforms import functional as F
from PIL import Image, ImageDraw, ImageFont
from torchvision.ops import nms
from fastsam import FastSAM, FastSAMPrompt
import matplotlib.pyplot as plt
import numpy as np
import random
# COCO 目标分类
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle',
'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'N/A', 'stop sign', 'parking meter', 'bench',
'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant',
'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A',
'N/A', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard',
'surfboard', 'tennis racket', 'bottle', 'N/A', 'wine glass',
'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A',
'dining table', 'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop',
'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven',
'toaster', 'sink', 'refrigerator', 'N/A', 'book', 'clock',
'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
# 目标检测
def object_detection(image, model, iou_threshold=0.5, threshold=0.8):
# 对图像进行预处理
image_tensor = F.to_tensor(image)
# 增加 batch 维度
image_tensor = image_tensor.unsqueeze(0)
# 获取预测结果
with torch.no_grad():
predictions = model(image_tensor)
# 提取预测的边界框、类别和分数
boxes = predictions[0]['boxes'].cpu().numpy()
labels = predictions[0]['labels'].cpu().numpy()
scores = predictions[0]['scores'].cpu().numpy()
# 非极大值抑制
keep = nms(torch.tensor(boxes), torch.tensor(scores), iou_threshold=iou_threshold)
# 保留NMS后的结果
boxes = boxes[keep]
labels = labels[keep]
scores = scores[keep]
# 过滤掉低置信度的预测
results = []
bboxs = []
for box, label, score in zip(boxes, labels, scores):
if score > threshold:
box = [round(coord, 2) for coord in box]
classify = COCO_INSTANCE_CATEGORY_NAMES[label]
score = round(score, 2)
results.append({
"box": box,
"classify": classify,
"score": score,
})
bboxs.append(box)
return results, bboxs
# 目标分割
def sam(image, model, bboxes, device="cpu", retina_masks=True, imgsz=1024, conf=0.4, iou=0.9):
everything_results = model(image, device=device, retina_masks=retina_masks, imgsz=imgsz, conf=conf, iou=iou)
prompt_process = FastSAMPrompt(image, everything_results, device=device)
ann = prompt_process.box_prompt(bboxes=bboxes)
return prompt_process.plot_to_result(annotations=ann)
# 生成随机颜色
def generate_random_color():
# 生成深色随机颜色
r = random.randint(128, 255)
g = random.randint(120, 180)
b = random.randint(50, 125)
return (r, g, b)
def main():
# 图像目录位置:
image_path = "./img"
# sam 模型位置
sam_model_path = "./weights/FastSAM_X.pt"
# 加载 FastSAM 模型
sam_model = FastSAM(sam_model_path)
# 加载预训练的 Faster R-CNN 模型
object_detection_model = fasterrcnn_resnet50_fpn_v2(pretrained=True)
object_detection_model.eval()
# 字体
font = ImageFont.truetype("arial.ttf", 20)
for image_name in os.listdir(image_path):
# 加载图像
image = Image.open(os.path.join(image_path, image_name))
# 目标检测
results, bboxs = object_detection(image, object_detection_model)
if (len(results) == 0):
continue
# 目标分割
sam_image = sam(image, sam_model, bboxs)
# 可视化结果
sam_image = Image.fromarray(sam_image)
draw = ImageDraw.Draw(sam_image)
for item in results:
box = item["box"]
classify = item["classify"]
score = item["score"]
draw.rectangle(box, outline=generate_random_color(), width=2)
draw.text((box[0], box[1]), f"{classify} ({score})", fill='red', font=font)
plt.figure()
plt.subplot(1, 2, 1)
plt.imshow(image)
plt.subplot(1, 2, 2)
plt.imshow(sam_image)
plt.show()
if __name__ == '__main__':
main()
运行示例:

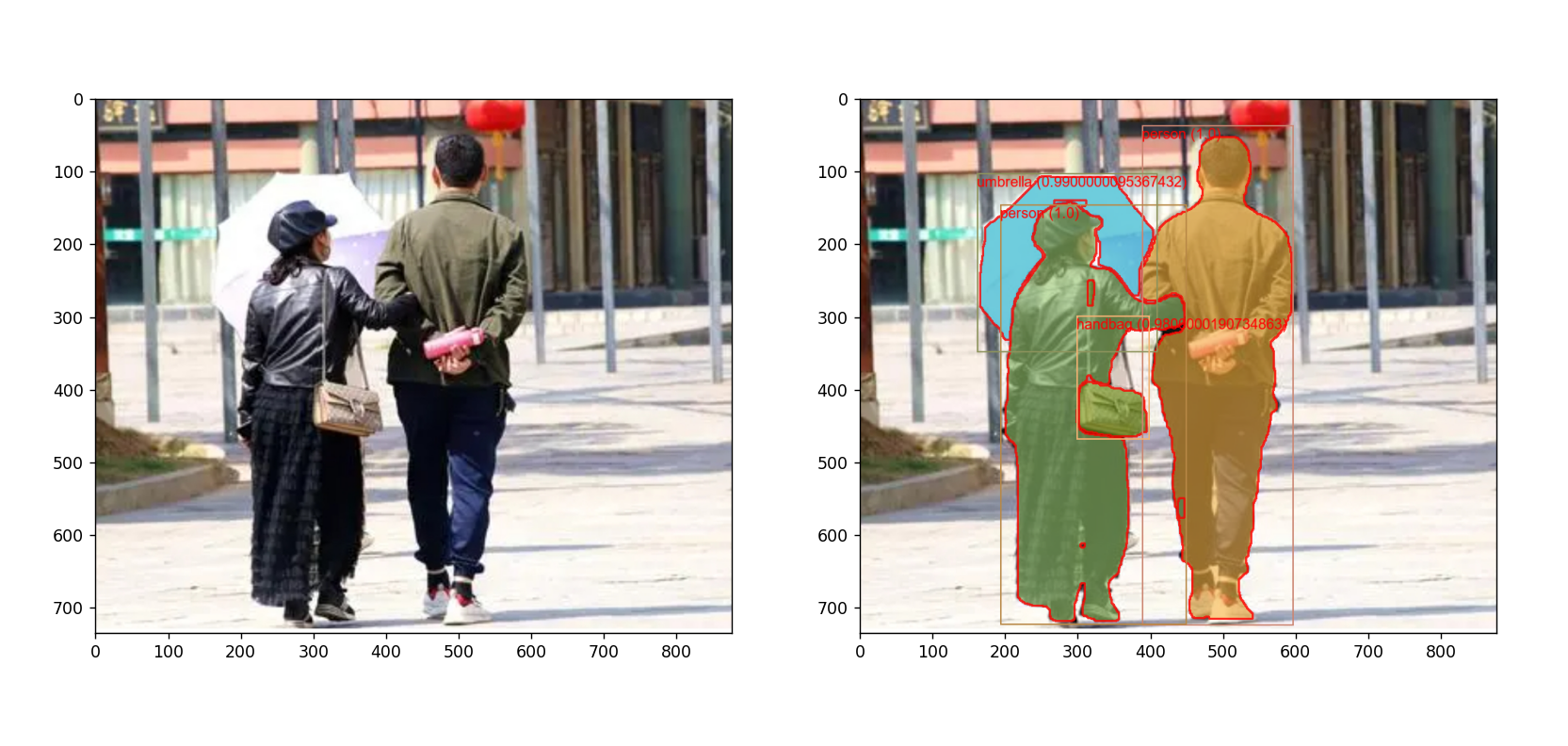
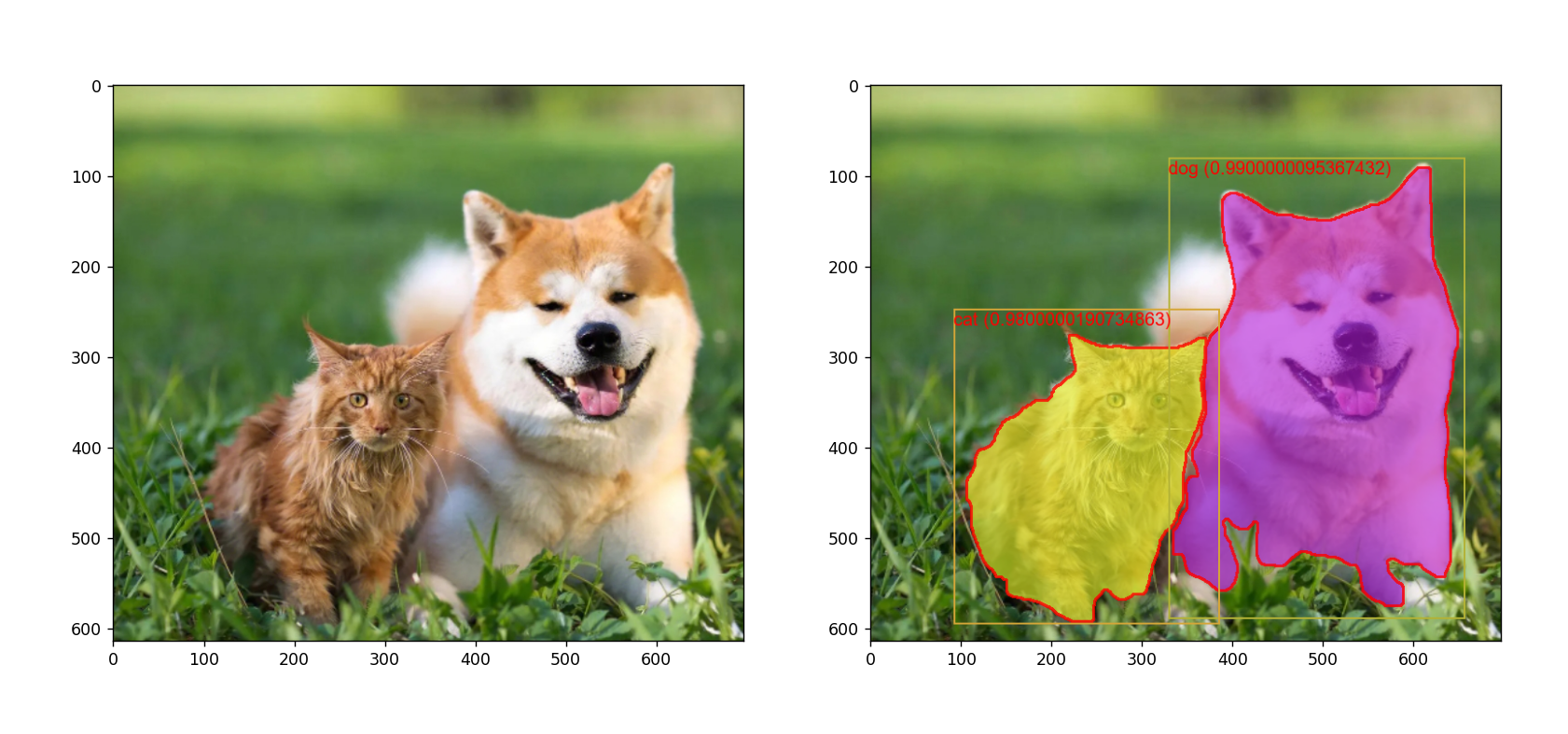
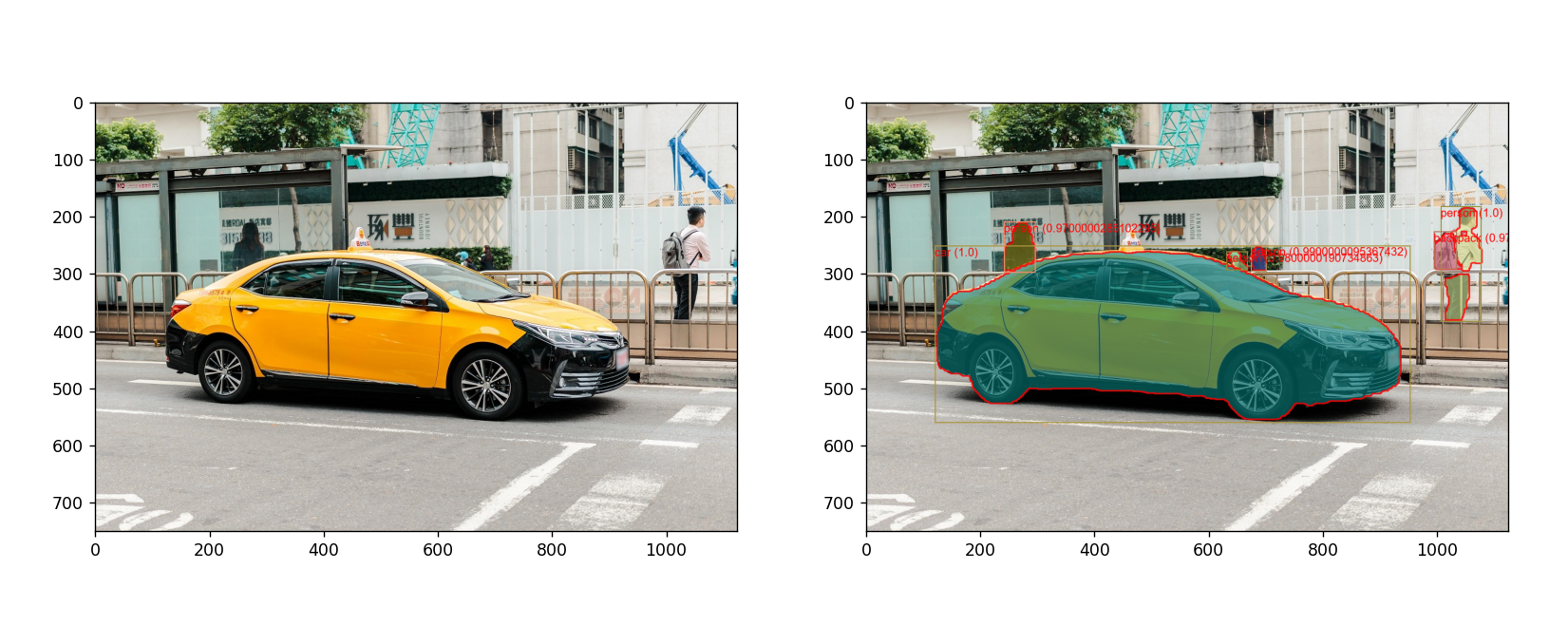
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uni-app的 js API 回调函数this指向问题,导致视图层没有更新
- Docker 操作
- 【Leetcode 1944】队列中可以看到的人数 —— 单调栈
- GNSS星历下载链接汇总
- 两种雪花的动态效果代码,分别使用HTML/CSS和JavaScript实现
- 大一作业习题
- 网络中的关键桥梁:Neo4j中的介数中心性分析
- C语言常见的错误(形参的改变与实参,输出时%d的各种情况)
- Java基础-OJ
- CSS 加载中动画