【大数据毕设】基于Hadoop的音乐推荐系统的设计和实现(六)
博主介绍:?全网粉丝6W+,csdn特邀作者、博客专家、大数据领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于大数据技术领域和毕业项目实战?
🍅首页可直接下载项目🍅
🍅文末获取联系,有偿部署🍅
文章目录
基于Hadoop的音乐推荐系统的设计和实现
摘 要
随着音乐行业的不断发展和热爱音乐的人不断增加,为了适应当今社会人们追求质量和高标准的生活,从大量的歌曲中找到个人喜好的小部分歌曲成了当务之急,然而普通的系统已经无法处理这种相当大的数据,然而基于大数据的音乐推荐系统作为可以解决这个重要难题的主要解决办法,其方法的好用程度已经成为了人类高标准生活的重要的一部分。随着计算机技术和互联网的高速发展,大量的数据随之产生,如何从大量的、冗余度、低质量的数据中找到符合要求的高质量数据成为了重中之重,所以构建一个能够将大量低质量、复杂、冗余的数据转换成高质量数据的音乐推荐系统有非常重要的意义。
本文一开始分析了基于大数据音乐推荐系统和音乐推荐系统的背景,指明了本文的研究思路和方向,然后,根据软件工程项目的要求,进行了基于大数据的音乐推荐系统的需求分析,并通过数据处理流程的整理和分析,进行了系统的整体设计,主要包括数据的模拟、集群的搭建、Maven项目的构建、代码的编写以及代码的运行。在系统分析和设计的基础上进行了数据库的设计,主要包括了数据库建模和数据库逻辑设计,最后,对系统进行了开发和运行测试,通过Hadoop、Yarn、Zookeeper等技术的运用,开发了一个能够基于大量数据,处理好大量数据并且产生准确结果的基于大数据的音乐推荐系统。
在本文的研究中,在数据的处理方面做了很多的工作,主要的目标是能够开发出一个能够基于大量数据,处理好大量数据,展示出准确结果的系统,以便能够从大量的低质量数据中找到高质量的数据
关键词:音乐推荐系统;高质量数据;Hadoop
Design and implementation of music recommendation system based on big data
Abstract
With the continuous development of the music industry and the increasing number of people who love music, in order to adapt to today’s society where people pursue quality and high standards of life, it has become a priority to find a small part of personal preference from a large number of songs. However, ordinary systems can no longer handle such a large amount of data. However, music recommendation system based on big data, as the main solution to this important problem, has become an important part of the high standard of human life. With the high-speed development of computer technology and Internet, the resulting data, how to go from a lot of, redundancy, found in the data of low quality meets the requirements of high quality data has become a top priority, so build a to a large number of low quality, complex, redundant data into a high quality data of music recommendation system has very important significance.
This paper at first analyzes the music recommendation system based on big data and background music recommendation system, pointed out the research idea of this article and the direction, and then, according to the requirements of software engineering project, the music recommendation system based on the data of demand analysis, and through the collection and analysis of data processing, the system overall design, It mainly includes data simulation, cluster building, Maven project construction, code writing and code running. On the basis of system analysis and design, the design of database, including database modeling and database logic design, finally, the development and operation test of the system, through the application of Hadoop, Yarn, Zookeeper and other technologies, the development of a database based on a large amount of data, A music recommendation system based on big data that processes large amounts of data and produces accurate results.
In the research of this paper, a lot of work has been done in data processing. The main goal is to develop a system that can process a large amount of data and show accurate results based on a large amount of data, so that high-quality data can be found from a large amount of low quality data.
Keywords:Music recommendation system ; High quality data;Hadoop
目 录
1 绪 论
1.1 研究的背景及意义
1.1.1 选题的背景
随着互联网时代的到来以及经济的高速发展,人们的生活意识和生活方式产生了日新月异的变化,人们越来越喜欢追求生活各个发方面的方便和简洁,这是由于人的共性所决定的,都希望能够生活过得更好。在人们的生活方式中,人们之间的交流和互动会产生大量的且看似没有任何规律的信息,在这样相当大量的信息中,相当大的一部分都是没有用的垃圾信息,也就是属于是低质量的信息。然后又是由于信息量的不断增加,导致我们利用普通的技术已经无法处理这些低质量的信息,并且还无法有效的从这些低质量的信息中高效的分析,然后取出高质量的信息。恰好,近几年飞速发展的大数据就是趁着这个趋势顺势而起,用它自己卓越的能力——能够快速处理大量的数据,并且不用太高的配置还能够得到比较准确的结果这一巨大优势迅速吸引了人们的眼球。最近几年各大新闻媒体都经常报道大数据方面的信息,国家也非常重视大数据的发展以及各大互联网公司都在不断提升大数据技术和概念。由此可知,大数据处理时代已经是一个不可逆的历史潮流,一定会在未来越来越重要的,并且也会不负所望,也会在未来发挥巨大的作用。根据调查,发现近十几年越来越多的人喜欢听歌,把听歌当成了自己生活中非常重要的一部分,主要是因为听歌可以方便的放松一个人的心情,让心情更加愉快,在精神上可以十分的放松,也可以放松一天的疲惫。根据大量的数据显示平均每个人每天都会听一个小时的歌,一首歌大概3-4分钟,也就是说每天一个人大概会听20首歌,那整个人类一天大概要听上百亿次的歌。然而,由于歌是有限的并且大大小于听歌次数,这就表现出了一个问题,人们无法快速准确的找到自己喜欢的歌,那么如今人们怎么样才能够找到那些自己喜欢的歌便是至关重要的问题,那如何能够找到自己喜欢的歌呢?恰好基于大数据的音乐推荐系统便是为了能够从大量的数据中,利用大数据技术快速并且高质量的分析到人们自己真正喜欢的歌。基于大数据的音乐推荐系统就是通过分析用户兴趣爱好、需求等信息,获取用户的特殊需求,然后为用户提供个性化的服务环节。
1.1.2 国内外研究现状
引荐系统至今已然有了横跨二十多年的开展进程。RecSys是每一年都会举行一次的引荐研讨范畴的第一流此外会议。到如今为止已然完满的地举行了10届之多,每届都会有非常多的不一样学科的深度研讨人员被这个集会吸引而来。在2008年,Robin Burke提出关于引荐系统的强健性的研讨,包含划分引荐模子的进犯的类型、计算机研讨进犯以后酿成的影响、引荐交换方案等。2011年,Oscar Celma回想并归结在线音乐中运用的引荐系统的道理和面临地应战,并瞻望了部分未来有可能用于改良音乐引荐的技术。2017年,Markus Schedt提出音乐引荐范畴,以往的协同引荐已然不能满足听众的要求,音乐引荐的实质变成了收听感觉的推荐,应作为一种序列引荐方法,情形引荐,同时在学术界和产业界对当下音乐引荐问题的处理方案:播单生成,情形引荐,音乐制造时的引荐。同年,还有人研讨了怎么深度研究其应用于推荐系统,和深入研究基于内容地引荐和协同引荐的形态。
产业界与引荐系统的关系也有非常亲密的关系。特性化引荐系统在产业界的使用也相当的普遍,触及到了音乐、电商、图书、新闻等范畴。依据亚马逊的财政统计,引荐系统为其增加了约莫20%的月入。很多公司都安排了引荐系统,如国际有名的豆瓣片子、今天头条、淘宝、京东等。
同时在引荐算法计算的优化方面也失去了普通和深化的研究,有大量的知名研究者实行了算法并行化的研讨。Ferraira等人自创Map-Reduce编程思惟,以Hadoop平台为根,改善和完成了对高级大数据的并行方面的计算。针对引荐系统没法在秒内对大量用户实行引荐,将协同过滤算法的三个首要计算阶段分为4个MapReduce进程,提高了引荐计算的效力。顾荣改良了Hadoop中短作业在履行时情况预备任务、Task分派进程和节点之间的通讯方法,大幅度的进步了短作业在Hadoop上的效力。
1.1.3 研究的意义
随着互联网时代的高速发展,人们在日常的生活中已经非常习惯的利用互联网去便利自己的生活,提高自己的生活质量。在精神方面,人们可以通过互联网去听歌来放松自己疲惫的心灵,来缓解自己一天的疲惫。但是如何利用歌曲放松自己,这会因人而异,有的人喜欢听欢快的歌,有人喜欢听伤心的歌,有的人还不知道自己喜欢什么歌,并且歌曲表达的情感一般只有人听了才能感觉出来,这无疑会浪费人们大量的时间去试听歌曲,人们如果将少量的时间花在找自己喜欢听的歌曲上,还有可能找不到自己喜欢听的歌曲就会导致完全在浪费时间,这会极大的打击人们的心情,并且有可能会导致人们不仅仅没有放松,反而还加重了疲惫。由于人们的耐心不同以及歌曲的不同,试听也会错过喜欢的歌,那么如何才能让人们快速找到自己喜欢的歌呢?我觉得基于大数据的音乐推荐系统便可以,这一系统是基于大量的用户数据来做基础,基于一定的推荐算法来做核心,对大量的数据进行分析处理,最后可以将根据用户个性化的推荐结果分析出来,最后将推荐结果展示在web界面上。
1.2 系统目标
本系统作为一个基于大数据的音乐推荐系统,全力做到一个系统实用性强,适合不同圈子的,具有很高准确性的推荐系统。可以基于不同的用户数据,来分析并且产生最优的推荐结果,这样可以在系统对外扩展的时候能够减少投入的、并且能够快速取得预期结果。在设计该系统时,要设计一个完整的数据处理流程:数据清洗,数据上传,数据分析,数据存储,数据可视化。这个系统主要是针对于数据,对于数据进行处理,然后分析,能够得到推荐的结果,主要是基于协同过滤算法的推荐、十大流行歌曲、十大流行歌手。希望能够给大家一个直观的感受,所有添加了Echarts,利用这个技术可以图形化数据。
各个模块实现目标:
数据清洗模块:将指定的原始数据进行初步的清洗操作,将不需要的数据列清除。
数据上传模块:利用指定的类将数据清洗模块处理后的数据上传至提前运行的HDFS分布式系统的指定目录上。
数据分析模块:将提前写好的数据分析模块代码打包上传至HDFS集群上运行,然后在HDFS分布式系统上指定的目录得到推荐结果。
数据存储模块:利用类将HDFS分布式系统上指定目录中的推荐结果下载至本地指定目录中,然后数据导入到MySQL指定的表中。
数据可视化模块:利用SpringBoot+Echarts将MySQL中指定的数据可视化展示在Web页面中。
2 需求分析
2.1 功能需求
该基于大数据的音乐推荐系统实现的主要是对模拟的用户听歌历史数据进行分析,离线的处理用户的行为信息,并将结果可视化在web页面中,该系统主要分为以下几大模块:
2.1.1 数据清洗
数据清洗是将拿到的一定格式的数据进行脏数据的清洗工作,把不需要的数据列信息给清洗掉,并且对数据进行存储。由于本次的数据是进行模拟产生的,所以数据的清洗功能比较简单就是实现主要是对数据进行的清洗操作时将不需要的数据列信息清洗掉以方便后面数据的处理过程,也就是让后面不用存储那么多数据和处理那么多数据,这样就加快了数据的处理。
2.1.2 数据上传
在数据分析平台搭建完成之后,首先要做的是把数据采集处理,因为该系统所做的是离线数据处理,所以一定要把存储一定的数据文件文本上传到HDFS分布式文件系统上,本次设计主要是采用的模拟数据,数据产生具有随机性,它的存储格式为列存储,这样的数据更方便分析处理。HDFS分布式文件系统同时也能够支持大量的数据进行存储,一次导入可以多次查看,这为整个系统的设计与实现提供了技术保证,在这一功能模块,不仅可以上传数据还可以对数据进行相应的处理和修改。
2.1.3 数据分析
数据分析是对数据上传好的数据进行按需统计的过程,根据需求分析所得出的要求在本系统中进行的数据分析需求有三个。需求一:根据数据分析出用户推荐。需求二:分析出最受欢迎的十大歌曲。需求三:分析出最受欢迎的十大歌手。主要是利用MapReduce对数据进行分析,再加上基于物品的协同过滤算法然后将需求一实现,能够得到正确的推荐结果。这个功能主义是要利用Yarn对代码进行管理然后集群对数据按照代码进行处理然后得出推荐结果。
2.1.4 数据存储
数据存储是对数据分析产生的推荐结果数据进行存储,将生成的结果数据存储至MYSQL中。这主要是因为数据分析所生成的结果是在HDFS分布式系统上的,所有我们首先要将推荐结果数据从HDFS系统的指定目录上下载至指定的的本地目录,然后再利用指定的类将数据保存至MySQL提前设置好的表中。
2.1.5 数据可视化
数据可视化是将数据存储中存储在MySQL中的数据利用SpringBoot+Echarts将数据展示在web页面中,主要是要将MySQL中指定好的表中的数据能够可视化在Web页面中,加上Echarts就能够图形化数据,让数据变得更加的直观,给人们更加好的感受。
2.2 非功能需求
2.2.1 可维护性分析
该平台采用的是Yarn模式,Yarn是Hadoop集群的一个组件,在Hadoop集群下,只要同时存活的结点大于一般就能够正常的运行,如果处理的数据过于庞大,增加相应的结点就能解决这个问题,大大增加了平台的可维护性
2.2.2 可扩展性分析
该系统的可扩展主要从两个方面考虑,一方面是集群的可扩展性,增加集群的数量可以提高数据的存储量和对于数据的处理速度;另一个方面是程序的可扩展性,只有程序架构的好,可以直接传入数据进行分析,几乎不用去改动代码。因此,该系统会具有很高的可扩展性。
2.2.3 应用场景分析
在当今这个互联网普及的社会,网上每分每秒都会有大量的数据产生,如何能够从中找到有价值的数据,从而帮助个人、企业、社会快速发展,例如在一件商品在哪些城市的销量最好,在哪些城市增长趋势最高,这些都能够方便厂家做一些决策。
本平台采用的框架能够高效的处理社会上的那些海量的数据,能够帮助个人、企业、社会做一些正确且深远的决策,能够及时、准确的用于处理未知的场景。
2.2.4 可测试性分析
该系统的可测试分析主要是从数据源入手,对于不同的数据源可以利用这个系统进行处理,只要这个数据源的基本格式是符合我们所设计的数据就能够进行操作,这样就可以大大的方便对数据进行测试,并且测试的时候也可以对数据结果进行设计,然后再与程序所得的推荐结果进行比对。这样测试的结果可以用于不同的行业,只有是需求是推荐的功能。
2.2.5 其它需求
由于系统产生的推荐只能是在有数据的情况下进行推荐,如果不需要数据也能够进行推荐的话就需求求出最受欢迎的歌曲去进行推荐或者最受欢迎的歌手进行推荐歌手的歌曲。
3 总体设计
3.1 运行环境
开发环境:
(1)硬件环境:CPU i5-6300HQ,12.00GB内存
(2)开发工具:Idea 2019.3,Xftp7,Xshell7
运行条件:
(1)操作系统:Windows 、Centos-6.5
(2)网络协议:TCP/IP协议
(3)浏览器: Google Chrome
(4)数据库:MySQL
(5)集群管理工具:Zookeeper
3.2 基本处理流程
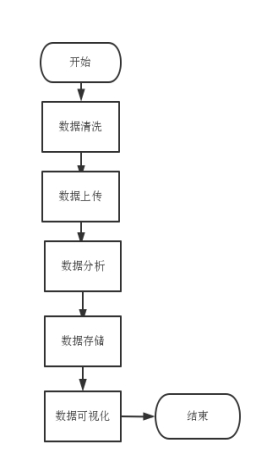 该系统的的基本处理流程主要是先对数据进行数据清洗、然后将数据上传到HDSF分布式系统上、再利用集群对数据进行分析、再将推荐结果存储在Mysql指定的表中储,最后将数据可视化在web页面中,如下图:
该系统的的基本处理流程主要是先对数据进行数据清洗、然后将数据上传到HDSF分布式系统上、再利用集群对数据进行分析、再将推荐结果存储在Mysql指定的表中储,最后将数据可视化在web页面中,如下图:
图3-1 平台业务流程图
3.3 模块结构
本系统是基于大数据的音乐推荐系统,主要的是对于模拟的用户历史播放数据进行分析,核心在于对数据的处理,各个模块就是针对数据进行顺序化的的处理操作,模块主要有数据清洗模块、数据上传模块、数据分析模块、数据存储模块、数据可视化模块。数据清洗模块、数据上传模块、数据存储模块是需要自己去操作对应的类然后去实现对应的结果。数据分析模块需要打包代码上传至HDFS分布式集群上运行的。数据可视化模块是运行代码直接将推荐结果展示在web页面。
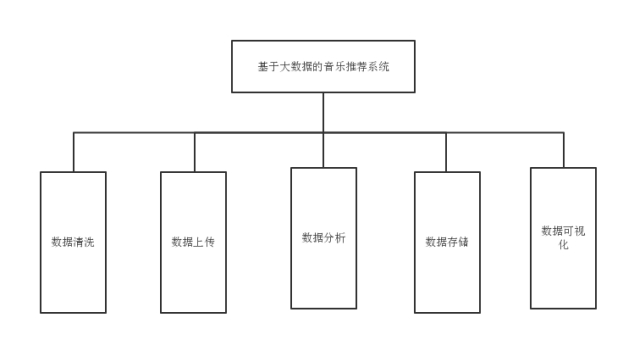
图3-2 基于大数据的音乐推荐系统的系统模块图
3.3.1数据清洗
数据清洗从名字上就可以轻易的看出就是把“脏”的数据去除掉,保存正确的数据,是指发现并且矫正数据文件中可识别的错误的一道程序,包括检查数据的一致性、处理无效值和缺失值等。因为数据仓库中的数据重要是面向某一主题的数据的集合,这些数据从系统中采取而来的用户历史数据,这样就不可避免的就会有的数据是错误的、无效的,有的数据相互之间还会有冲突,这些错误的或有冲突的数据很明确就不是我们所需要的数据,所以我们称之为脏数据。我们要按照一定的规则将脏数据清洗掉。
3.3.2数据上传
数据上传顾名思义就是将数据上传至指定的地方,是指我们将我们所需要的数据从一个地方转移到另一个地方。在数据的处理过程中,我们可能会经常跨系统操作,由于系统的不同,所以会必然而导致数据的不好互通,所以一般我们都有设计好指定的模块去将数据从一个系统指定的目录转移到另一个系统的指定目录,这其中经常会设计权限等问题的操作,所以为了保证数据的畅通性,我们必须提前设计好安全的数据上传模块。
3.3.3数据分析
数据分析首要是对数据实行操作,想要对数据实行剖析,然后尝试对于用户是有用的数据。这个过程当中是指用正确的统计剖析方法对收集来的数据实行合理性分析,将它们加以结合和了解并处理,以此来以得到最大化地开发数据的作用,将数据的用处发扬到极尽描摹。数据分析主要是提取有用的信息的过程和形成结论而对数据加以具体的分析和归纳综合形成推荐结果的过程。
3.3.4数据存储
数据存储关于数据来讲就是一个地方来持久保管关键的数据,由于人类天下天天都会发生非常多的数据,但是人类存储数据的才能是有限的,所以我们不能存储一切的数据,只能将我们以为关键的数据应用技术存储起来。数据存储一开始是以某种格局记录在计算机的内部或外部的存储介质里面。数据存储要定好名,这类定名要反映信息特点,然后构成寄义。数据流体现了系统中流动的数据,会表现出动态数据的特征;数据存储反应系统中静止的数据,会表现出静态数据的特点。
3.3.5数据可视化
数据可视化是主要指在技术上利用比较高级的技术来实现,但是这些技术办法利用图形、图象处置、计算机视觉和用户界面的办法,经过表达、建模和平面、外表、属性和动画的显示,对数据加以可视化说明。首要就是将板滞的大量数据,应用高级的技术转换为图形化的展现,这样就愈加直观的展现数据,可以便利用户旁观。
3.4 外部接口
软件接口:该基于大数据的音乐推荐系统的数据库是使用的MySQL,系统中连接上数据库之后,通过运行SpringBoot自带的类就能使得系统访问内部的数据。
3.5 内部接口
系统的数据库是通过jdbc连接的,利用模块之间的相互关系,是通过模块接口处的参数实现通信的。
4 数据库设计
4.1 概念结构设计
4.1.1 设计思路
基于大数据的音乐推荐系统在进行数据分析之后产生的数据是需要存放在数据库中的,本次设计采用的是关系型数据库MySQL,它可以将数据存放在不同的表中,从而增加了查找速度和它的便捷性。本次设计分析得到的数据主要是根据用户的三个需求进行数据分析的。用户的三个需求分别是推荐歌曲、最受欢迎歌手、最受欢迎歌曲所以本次设计需要构建三个数据分析结果实体表。
(1)基于协同过滤算法的歌曲推荐结果
(2)基于听歌次数最多的歌曲排序
(3)基于最欢迎歌手进行排序
4.1.2 实体属性图
基于大数据的音乐推荐系统进行数据分析之后产生的数据是需要存放在数据库中的,本次设计采用的MySQL数据库,它可以将不同的推荐结果保存在数据库中不同的表中,从而增加了查询的速度。本次设计需要构建三个数据分析结果实体表。
(1)分析结果1是利用协同过滤算法对用户数据进行分析形成的结果,主要有用户ID、歌曲ID和推荐值,实体属性图如下:
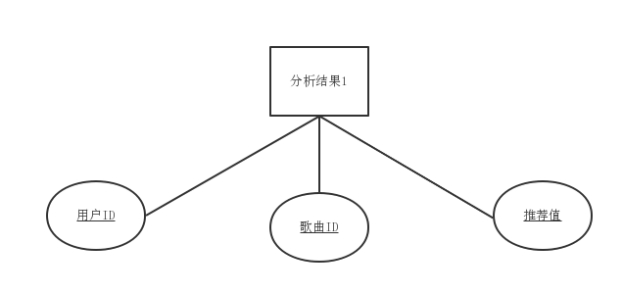
图4-1 基于协同过滤算法推荐结果实体属性图
(2)分析结果2是基于用户数据分析得到最受欢迎歌曲结果,主要有歌曲ID、歌曲名字、歌曲次数,实体属性图如下:
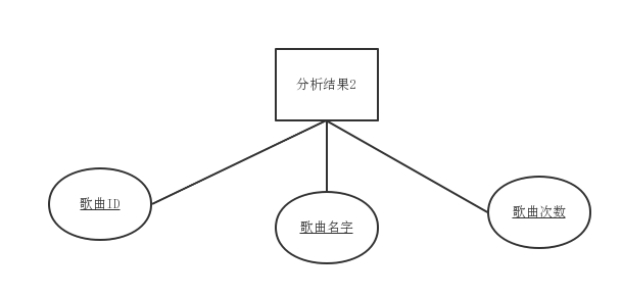
图4-2 最受欢迎的歌曲实体属性图
(3)分析结果3是基于用户数据分析得到最受欢迎歌手结果,主要有歌手ID、歌手名字、歌手次数,实体属性图如下:
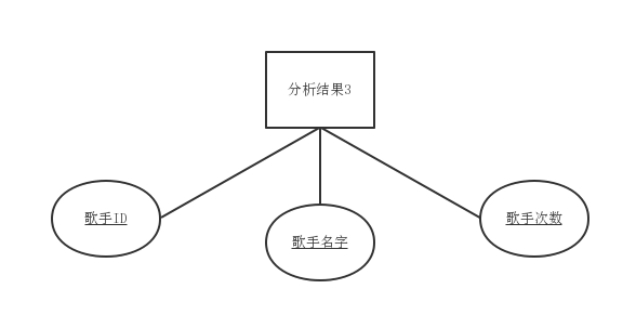
图4-2 最受欢迎的歌手实体属性图
4.2 逻辑结构设计
4.2.1 设计思路
根据需求条件,在系统设计中所设计出来数据库所需要的数据库的相关表、主要是对进行推荐结果存储的三个表,第一个表时用来存储基于协同过滤算法的推荐结果的,第二个表是用来存储最受欢迎歌曲的数据,第三个表是用来存储最受欢迎歌手的数据。
4.2.2 逻辑模型
(1)基于协同过滤算法的歌曲推荐结果表,主要包括了歌曲的ID,歌曲的名字和歌曲被听的次数。建表信息如表4-1所示。
表4-1 基于协同过滤算法推荐结果表
| 字段名称 | 字段类型 | 空/非空 | 注释 |
|---|---|---|---|
| NameID | Int | 非空 | 用户名字ID |
| SongID | Int | 非空 | 歌曲ID |
| Num | Double | 非空 | 推荐度 |
(2)最受欢迎歌曲表中存储了歌曲ID,歌曲名字和歌曲被听的次数,其内容如表4-2所示:
表4-2 最欢迎歌曲表
| 字段名称 | 字段类型 | 空/非空 | 注释 |
|---|---|---|---|
| SongID | Int | 非空 | 歌曲ID |
| SongName | Varchar | 非空 | 歌曲名字 |
| Num | Int | 非空 | 歌曲被听次数 |
(3)最受欢迎歌手表中存储了歌手ID,歌手名字和歌受被引用的次数,其内容如表4-2所示:
表4-3 最受欢迎歌手表
| 字段名称 | 字段类型 | 空/非空 | 注释 |
|---|---|---|---|
| SingerID | Int | 非空 | 歌手ID |
| SingerName | varchar | 非空 | 歌手名字 |
| Num | Int | 非空 | 歌手被引用次数 |
4.3 物理结构设计
4.3.1 存取方式
本系统采取的是比较经常使用的Hash索引存取办法,我们常说的Hash索引就是一种可以将任意的长度的输入紧缩到某一固定的长度的输出的办法。但是Hash索引就是基于哈希表所完成的,只有在准确适配索引中一切列的查询的条件下下才会生效。对于每行的数据,存储引擎都会对一切的索引列计算出一个相关的Hash code,Hash code是一个相对来水比较小的值,而且不同的键值的行计算出来的Hash code都是不尽相同的。Hash索引会把所有的Hash code都存储在索引当中,与此同时在Hash表中会保存指向每个数据行的指针。关于Hash类似的,则采取链表的方法处理抵触。
4.3.2 存储结构
基于大数据的音乐推荐系统所涉及到的数据都会存储在数据库的不同的表中。table_recommend表主要是存储推荐结果的相关信息,在这个表中主要是有推荐人ID、推荐歌曲ID和推荐度;table_psinger表中主要是存储最受欢迎歌手的信息,在这个表中主要是有推荐歌手ID、推荐度;table_psong表中主要是存储最受欢迎歌曲的信息,在这个表中主要是有推荐歌曲ID、推荐度。Song表中主要是存储了歌曲和歌曲名字的一对一映射关系,在这个表中主要是有歌曲ID和歌曲名字。table_user表中主要是存储了歌手ID和歌手名字的一对一映射关系,在这个表中主要是有歌手ID和歌手名字。系统中相关表的建表语句有以下几个部分:
table_recommend的建表语句如下所示:
CREATE TABLE table_recommend (
NameID int DEFAULT NULL,
SongID int DEFAULT NULL,
Num double DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
table_recommend表的物理结构图如下:
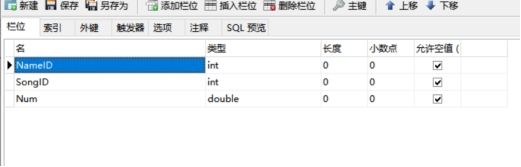
图4-4 table_recommend表的物理结构图
table_psinger的建表语句如下所示:
CREATE TABLE table_psinger (
SingerID int DEFAULT NULL,
Num int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
table_psinger表的物理结构图如下:
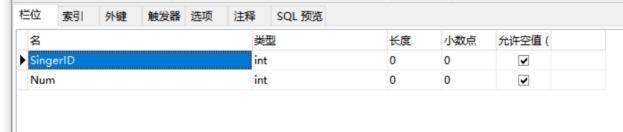
图4-5 table_psinger表的物理结构图
table_psong的建表语句如下所示:
CREATE TABLE table_psong (
SongID int DEFAULT NULL,
Num int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
table_psong表的物理结构图如下:
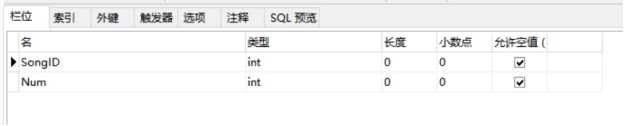
图4-6 table_psong表的物理结构图
Song表的建表语句如下所示:
CREATE TABLE song (
songID int DEFAULT NULL,
songname varchar(255) DEFAULT NULL,
singerID int DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
Song表的物理结构图如下:
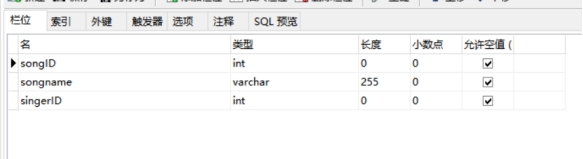
图4-7 Song表的物理结构图
table_user表的建表语句如下所示:
CREATE TABLE table_user (
nameID int NOT NULL,
name varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (nameID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
table_user表的物理结构图如下:

图4-8 table_user表的物理结构图
5 界面设计
5.1 界面关系图或工作流图
该系统是一个基于大数据的音乐推荐系统,它主要是对数据进行处理,然后对产生的推荐结果进行处理然后将其在web页面展示出来。然后结合需求进行分析,可以得出只要四个页面就可以。
第一个页面就是展示出导航作用,可以给用户进行对需求结果的挑选,分为三个,第一个是基于算法形成的推荐结果,第二个是最受欢迎的十大歌曲,第三个是最受欢迎的十大歌手。这个页面提供三个按钮,可以分别转入其他三个页面。
第二个页面就是基于算法形成的推荐结果进行可视化,利用web页面将数据结果展示出来,然后在这个页面下面也是有三个按钮,分别可以去第一个页面,第三个页面和第四个页面。
第三个页面就是利用Echarts将Mysql中的数据结果进行展示出来,将最受欢迎的十大歌曲在页面中展示,然后在这个页面下面也是有三个按钮,分别可以去第一个页面,第二个页面和第四个页面。
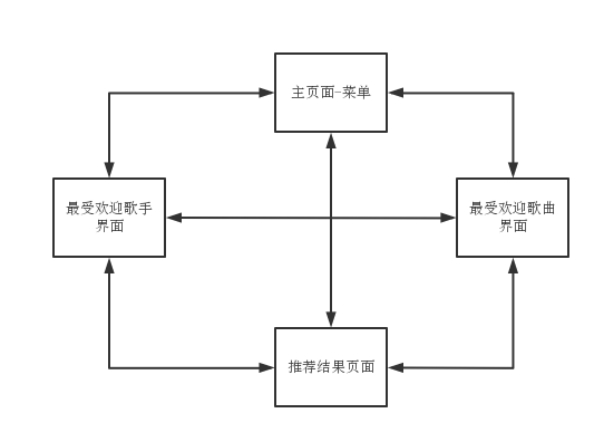 第四个页面也是利用Echarts将Mysql中的数据进行可视化展示出来,将最受欢迎的十大歌手在页面中进行展示。然后在这个页面下面也是有三个按钮,分别可以去第一个页面,第二个页面和第三个页面。
第四个页面也是利用Echarts将Mysql中的数据进行可视化展示出来,将最受欢迎的十大歌手在页面中进行展示。然后在这个页面下面也是有三个按钮,分别可以去第一个页面,第二个页面和第三个页面。
图5-1 界面关系图
5.2 界面设计成果
略
6 详细设计
6.1 系统主要功能模块介绍
作为基于大数据的音乐推荐系统,其功能主要是对数据进行处理,保证能够在大量低质量的数据中筛选出高质量的数据,在这个过程中要保证能够数据的准确性以及结果的准确性,再结合需求进行剖析,在设计系统时要从程序、功能和友好界面等方面进行考虑,从而设计出更加便捷的系统。在了解系统需求之后,基于大数据的音乐推荐系统可分为数据清洗,数据上传,数据分析,数据存储,数据可视化这一整个流程模块。
数据清洗模块:数据清洗模块主要是对取得的数据进行清洗,一般在这里会进行两个操作,一个是对脏数据的清洗,只挑选对研究有用的数据列,这样可以加快后面的运算速度;二是对数据进行分区存储。主要是利用CleanData类对数据进行处理。
数据上传模块:数据上传模块主要是将已经清洗好的数据上传到HDFS分布式文件系统上面的指定位置,该模块还可以对数据进行下载、修改、删除等功能。主要是利用File类中的upload方法实现文件上传操作。
数据分析模块:数据分析模块主要功能就是将上传至HDFS分布式系统的数据进行分析,本系统主要是利用MapReduce对数据进行处理,主要是利用基于协同过滤算法进行分析得到有价值的数据信息。主要是利用FinalJob类对One、Two、Three、Four、Five、Six包内的类进行协调,对数据进行分析。
数据存储模块:数据存储模块就是用来存放数据分析模块的处理结果的,这样方便之后的数据查询工作。主要是将数据分析模块所得出的推荐结果从HDFS分布式系统上指定的结果目录下的文件下载至本地,然后再将本地文件的数据保存到MySQL指定的表中。主要利用Mysql包内对应数据表插入的类将文件中的数据对数据库进行插入操作。
数据可视化模块:数据可视化模块就是把数据存储模块中的数据结果进行图形化展示在web页面之中。主要是利用SpringBoot+Echarts技术利用MySQL中的数据表中的数据,然后将数据图形化的展示在页面中。
6.2 数据清洗模块设计
6.2.1 数据清洗模块算法描述
略
7 编码
7.1 代码实现与核心算法
(1)核心算法
核心算法主要是是对数据的处理的算法、是运用于数据分析模块,是基于用户的协同过滤算法。
基于用户的协同过滤算法简单讲解如下:
协同过滤算法是一种借助“群体计算”的途径。它主要是利用大量已有的用户偏好数据来大致估计用户对其未接触歌曲的喜欢程度。其内在的本质就是相似度的意思。本系统就是基于用户的协同过滤算法来对用户进行歌曲推荐。
基于用户的协同过滤算法中,如果两个用户显示出相似的喜欢程度(也就是对相同歌曲的喜欢大概是相同的),那么本系统就会认为他们的兴趣歌曲的类型是类似的。所以可以对他们中的一个用户推荐另一个用户喜欢的歌曲而此用户听过的歌曲。举个例子,如果用户1喜欢歌曲a、歌曲b、歌曲c、歌曲d,而用户2喜欢歌曲a、歌曲d,算法就会认为用户1和用户2是相似的,因此给用户2推荐用户1喜欢的歌曲b和歌曲d。
(2)代码实现
该系统的核心代码主要是数据进行处理,基于协同过滤算法,主要实现功能如下:
1、从数据中获取用户听歌记录的列表

图7-1 获取用户听歌记录核心代码图
2、计算歌曲之间的共现关系
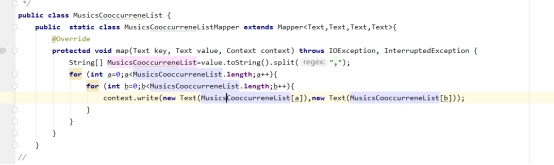
图7-2 计算共现关系核心代码图
3、计算出歌曲的共现次数(共现矩阵)

图7-3 计算共现次数核心代码图
4、计算出用户的听歌向量

图7-4 计算用户听歌向量核心代码图
5、获取歌曲共现矩阵乘以用户歌曲向量,形成暂时的推荐结果文件。
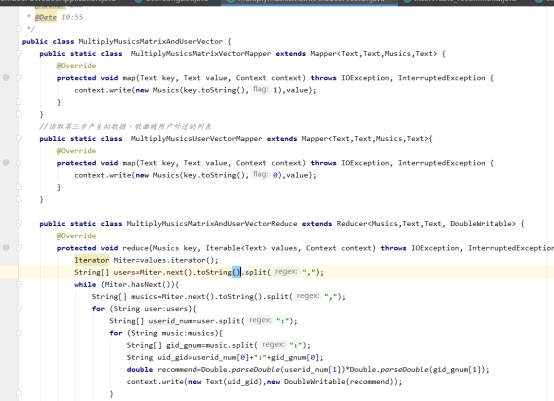
图7-5 临时推荐核心代码图
6、对上一步计算的推荐的结果进行求和
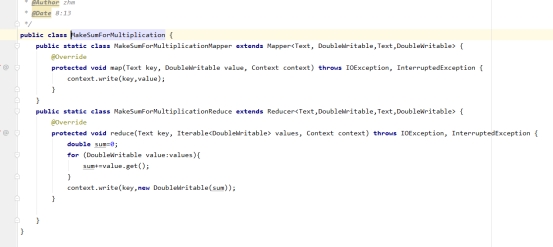
图7-6 计算结果求和核心代码图
7、去重复的数据,在推荐结果中去掉用户已经听过的歌曲信息。

图7-7 去重核心代码图
8、启动类核心代码
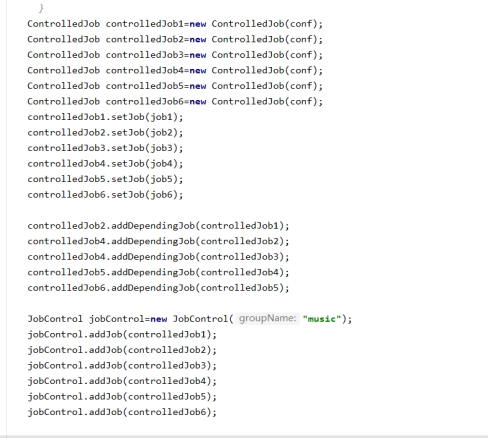
图7-8 启动类核心代码图
9、将数据从Mysql取出并且返回集合对象核心代码
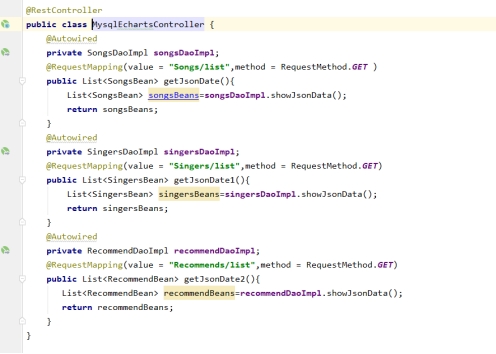
图7-9 可视化核心代码图
7.2 代码优化分析
(1)在Mapper和Reduce代码中,有的步骤只需要一个Mapper就能处理,另一个步骤只用一个Reduce就能处理,我将两个步骤写在了一个job作业中。
(2)利用Buffer将表中的数据按行插入到MySQL对应的表中。
(3)在形成初始推荐的时候,设置了分区来对数据进行更好的处理。
8 测试
8.1 测试方案设计
8.1.1 测试策略
测试是一个系统完善自身和投入生产线时都必须提前通过的一道门槛,而测试方案的好坏会决定一个系统最终的好坏,如果测试案例比较不规范就会导致投入使用时可能会出现各种bug,导致给用户不好的体验,只有测试方案很好,并且系统能够完美的经过测试才能够保证这个系统是很完美的,能够给用户很好的用户体验和完成用户的需求。尽快的加入测试可以更早的发现问题和解决问题,在每次完成一个功能模块的功能是可以采用白盒测试原则开放性地进行多次的单元测试。项目的功能全部完成之后,可以设计多组黑盒测试样例进行集成测试。
本系统的测试过程主要是动态测试的方法,输入相应的测试实例,然后将运行结果与预期结果去比对,如果对比结果一直则没有问题,如果对比不一致就是有问题。
8.1.2 测试进度安排
本测试主要是要先将数据模拟出来,利用java代码模拟大量数据,大概需要一天的时间完成数据的模拟,然后将集群搭建好并且能够正常运行,主要有hadoop集群和yarn集群,再利用maven构建项目,编写对数据进行处理,先模拟少部分数据然后运行在集群上,然后将结果可视化,提前可以手算得结果,然后再让真正的运行结果进行比对,如果对比之后发现是一样的就表示完美处理。
8.1.3 测试资源
软件资源:IDEA、Vmare、Navicat、Google浏览器
硬件资源:炫龙笔记本电脑、Windows 10 x64操作系统、Intel? Core? i5 CPU、12GB内存、CentOS-6.5。
人力资源:测试人员一个。
8.1.4 关键测试点
这个基于大数据的音乐推荐系统测试的关键点主要是要搭建好集群,然后构建maven项目编写数据分析模块的代码,然后打包上传至集群运行。
8.2 测试用例构建
8.2.1 测试用例编写约定
整个测试过程大部分是一边写,一边测试的,通常是完成了一个功能就会对这个功能模块进行测试,在此过程中都是利用随机数据进行测试。
8.2.2 测试用例设计
作为一个基于大数据的音乐推荐系统,在使用过程中,主要是要将模拟数据的文件上传至提前搭建好的HDFS分布式系统上,然后再将jar上传至集群上运行,最后将结果从HDFS分布式系统中下载至本地文件中,再将文件中的内容输入到MySQL中。其测试用例表如下:
表8-1 测试用例表
| 用例编号 | 用例名称 | 测试内容 | 测试结果 |
|---|---|---|---|
| 1 | 数据清洗 | 将数据清洗成想要的格式 | 清洗成功 |
| 2 | 数据上传 | 将数据文件上传至HDFS | 上传成功 |
| 3 | 数据分析 | 对HDFS上的数据文件进行数据分析 | 分析成功 |
| 4 | 数据存储 | 将结果文件存储至MySQL中 | 存储成功 |
| 5 | 数据可视化 | 将MySQL中的文件展示在web页面中 | 展示成功 |
8.2.3 关键测试用例
通过采用测试数据来进行对系统的功能进行测试,本次采用的测试数据是提前知道数据结果的,通过系统得出的结果与预期结果进行对比。
(1)测试文件上传功能
预期结果:文件在HDFS分布式文件系统不存在就会直接显示上传成功、如果HDFS分布式文件实体上已经存在就会显示文件存在、正在删除文件、文件上传成功。
测试结果:在进行数据测试之前,首先要把数据上传至HDFS分布式系统上面,将数据上传到HDFS分布式系统上如图8-1所示:
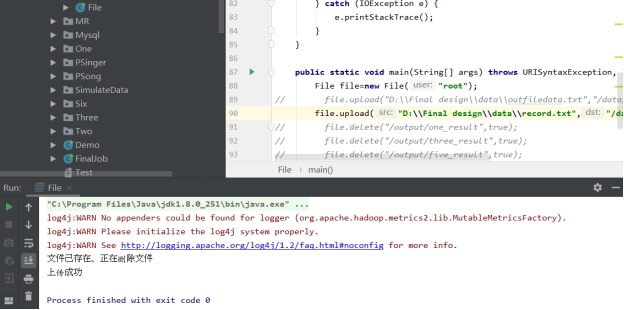
图8-1 数据上传成功图

图8-2 数据上传结果图
(2)测试数据分析功能
预期结果:如果成功处理数据就会在HDFS分布式上面会有设置的8个结果目录,如果失败的话就会缺少结果目录。
测试结果:再由数据分析模块对数据进行处理,在测试数据分析模块之前,要先将maven中的项目打包到HDFS分布式集群上运行,结果如下图:
图8-3 数据分析过程图
图8-4 在浏览器查看job图
? 图8-5 查看数据图
(3)测试数据可视化功能
预期结果:如果数据可视化成功就会显示Mysql中的数据内容,如果测试失败就会显示提前默认设置的数据。
测试结果:运行对应的前端代码,将MYSQL中的数据可视化在web页面中,结果如下图:
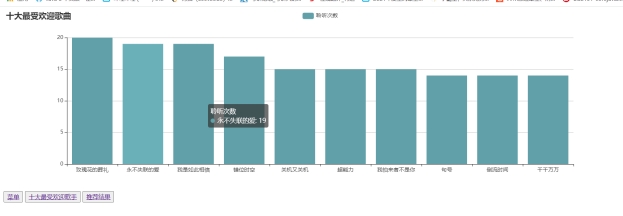
图8-6 查看十大最受欢迎歌曲图

图8-7 查看十大最受欢迎歌手图
8.2.4 测试用例维护
在系统的开发过程中,随着项目的进一步开发以及需求的变化,需要不但维护和更新使得系统可以更好的执行,所以我们测试的用例不应该一成不变,要采用多种数据进行测试,从而对系统进行完善。具体维护如下:
删除过时的测试用例
在由于数据尝试变化时,位于HDFS分布式系统的结果目录需要删除,这是由于 MapReduce所决定的,所以我们在每次用新的测试用例时要对结果目录进行删除。
添加新的测试用例
当数据发生变化时,要及时对数据进行处理,按照编写代码是所指定的数据格式
BUG转测试用例
在测试过程中发现的bug,在测试用例没有体现,应该将BUG转为测试用例
参考文献
[1]曾刚.实战Hadoop大数据处理[M].北京:清华大学出版社,2015.
[2]张兰廷.大数据的社会价值与战略选择[D].北京:中共中央党校,2014.
[3]隋占丽.基于协同过滤算法的音乐推荐系统[D].华侨大学,2013年12月.
[4]Hadoop集群的部署与管理系统的设计与实现[D],王宾硕士论文.
[5]基于大数据分析的音乐个性化推荐系统应用研究[D],郭博林硕士论文.
[6]卢丽静,朱杰,杨志芳.基于大数据的个性化音乐推荐系统[J].
[7]MapReduce实现商品推荐算法[J/OL].https://blog.csdn.net/uhgfrdss/article/details/79926497.
[8]基于物品的协同过滤算法(ItemCF)[J/OL].https://blog.csdn.net/weixin_34119545/article/details/90618574
[9]Hadoop权威指南[M],清华大学,Tom Wbitc著.
[10]Hadoop实战(第2版)[M],机械工业,陆嘉恒著.
[11]Hadoop 基础教程[M],人民邮电,Garry Turkington著.
[12]Hadoop技术详解[M],人民邮电,Eric Sammer著.
[13]吕宇琛. Spring Boot框架在web应用开发中的探讨[J]. 科技创新导报,2018. 168-173.
[14]协同过滤推荐算法研究进展[J]. 翁小兰,王志坚. 计算机工程与应用. 2018(01)
[15]基于混合推荐算法的个性化新闻推荐系统设计与实现[D]. 胡凯达.北京邮电大学 2021
[16]基于大数据的推荐系统研究[J]. 王彦琨. 通信电源技术. 2020(12)
[17]数据库系统概论[M]. 高等教育出版社 , 萨师煊,王珊[编著], 2000
[18]基于大数据分析的音乐个性化推荐系统应用研究[D]. 郭博林.电子科技大学 2018
[19]基于大数据技术的个性化推荐系统的设计与实现[J]. 乔岚. 信息与电脑(理论版). 2017(21)
[20]Hadoop MapReduce短作业执行性能优化[J]. 顾荣,严金双,杨晓亮,袁春风,黄宜华. 计算机研究与发展. 2014(06)
[21]音乐个性化推荐系统研究综述[J]. 谭学清,何珊. 现代图书情报技术. 2014(09)
[22]电信企业大数据分析、应用及管理发展策略[J]. 漆晨曦. 电信科学. 2013(03)
[23]基于大数据集的协同过滤算法的并行化研究[J]. 李改,潘嵘,李章凤,李磊. 计算机工程与设计. 2012(06)
[24]应用SpringBoot改变web应用开发模式[J]. 张峰. 科技创新与应用. 2017(23)
[25]基于用户偏好的矩阵分解推荐算法[J]. 刘慧婷,陈艳,肖慧慧. 计算机应用. 2015(S2)
[26]Spring Boot研究和应用[J]. 王永和,张劲松,邓安明,周智勋. 信息通信. 2016(10)
[27]基于SpringBoot微服务架构下的MVC模型研究[J]. 张雷,王悦. 安徽电子信息职业技术学院学报. 2018(04)
[28]李智萍,周金鑫.浅析音乐美育对大学生幸福感的影响[J].华东交通大学学报,2008,(4).
[29]Deep Item-based Collaborative Filtering for Top-N Recommendation[J] . Feng Xue,Xiangnan He,Xiang Wang,Jiandong Xu,Kai Liu,Richang Hong. ACM Transactions on Information Systems (TOIS) . 2019 (3)
[30]A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques[J] . Mehrbakhsh Nilashi,Othman Ibrahim,Karamollah Bagherifard. Expert Systems With Applications . 2018
[31]Matrix factorization for recommendation with explicit and implicit feedback[J] . Shulong Chen,Yuxing Peng. Knowledge-Based Systems . 2018
[32]Sequence-based context-aware music recommendation[J] . Dongjing Wang,Shuiguang Deng,Guandong Xu. Information Retrieval Journal . 2018 (2-3)
[33]A recommender system based on collaborative filtering using ontology and dimensionality reduction techniques[J] . Mehrbakhsh Nilashi,Othman Ibrahim,Karamollah Bagherifard. Expert Systems With Applications . 2018
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CISCO AIR-CT2504-15-K9 AP 注册不上常见问题
- 827. 双链表
- 分布式事务的8种解决方案(荣耀典藏版)
- 达梦数据库安装超详细教程(小白篇)
- 基于源码去理解Iterator迭代器的Fail-Fast与Fail-Safe机制
- vllm 加速推理通义千问Qwen经验总结
- 线上问题排查-接口请求偶尔失败
- echarts仪表效果
- Oracle数据库查询表空间使用情况
- 【MySQL】:探秘主流关系型数据库管理系统及SQL语言